







Model evaluation(模型评估)
Throughout this course, you've seen statements like the model demonstrated good performance on this task or this fine-tuned model showed a large improvement in performance over the base model. What do statements like this mean? How can you formalize the improvement in performance of your fine-tuned model over the pre-trained model you started with? Let's explore several metrics that are used by developers of large language models that you can use to assess the performance of your own models and compare to other models out in the world.

In traditional machine learning, you can assess how well a model is doing by looking at its performance on training and validation data sets where the output is already known. You're able to calculate simple metrics such as accuracy, which states the fraction of all predictions that are correct because the models are deterministic. But with large language models where the output is non-deterministic and language-based evaluation is much more challenging. Take, for example, the sentence, Mike really loves drinking tea. This is quite similar to Mike adores sipping tea. But how do you measure the similarity? Let's look at these other two sentences. Mike does not drink coffee, and Mike does drink coffee. There is only one word difference between these two sentences. However, the meaning is completely different.
 Now, for humans like us with squishy organic brains, we can see the similarities and differences. But when you train a model on millions of sentences, you need an automated, structured way to make measurements. ROUGE and BLEU, are two widely used evaluation metrics for different tasks.
Now, for humans like us with squishy organic brains, we can see the similarities and differences. But when you train a model on millions of sentences, you need an automated, structured way to make measurements. ROUGE and BLEU, are two widely used evaluation metrics for different tasks.
 ROUGE or Recall Oriented Understudy for Gisting Evaluation is primarily employed to assess the quality of automatically generated summaries by comparing them to human-generated reference summaries. On the other hand, BLEU, or Bilingual Evaluation Understudy is an algorithm designed to evaluate the quality of machine-translated text, again, by comparing it to human-generated translations. Now the word BLEU is French for blue. You might hear people calling this blue but here I'm going to stick with the original BLEU.
ROUGE or Recall Oriented Understudy for Gisting Evaluation is primarily employed to assess the quality of automatically generated summaries by comparing them to human-generated reference summaries. On the other hand, BLEU, or Bilingual Evaluation Understudy is an algorithm designed to evaluate the quality of machine-translated text, again, by comparing it to human-generated translations. Now the word BLEU is French for blue. You might hear people calling this blue but here I'm going to stick with the original BLEU.
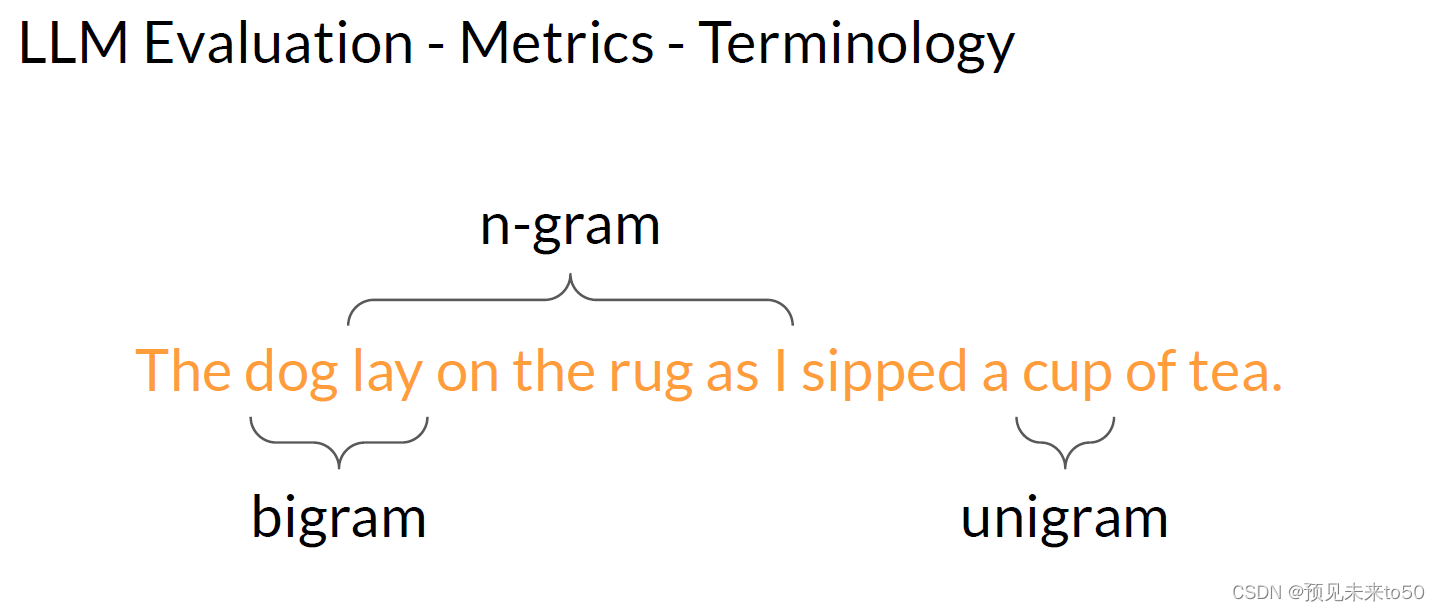
Before we start calculating metrics. Let's review some terminology. In the anatomy of language, a unigram is equivalent to a single word. A bigram is two words and n-gram is a group of n-words. Pretty straightforward stuff. First, let's look at the ROUGE-1 metric. To do so, let's look at a human-generated reference sentence. It is cold outside and a generated output It is very cold outside. You can perform simple metric calculations similar to other machine-learning tasks using recall, precision, and F1. The recall metric measures the number of words or unigrams that are matched between the reference and the generated output divided by the number of words or unigrams in the reference. In this case, that gets a perfect score of one as all the generated words match words in the reference. Precision measures the unigram matches divided by the output size. The F1 score is the harmonic mean of both of these values.

These are very basic metrics that only focused on individual words, hence the one in the name, and don't consider the ordering of the words. It can be deceptive. It's easily possible to generate sentences that score well but would be subjectively poor. Stop for a moment and imagine that the sentence generated by the model was different by just one word. Not, so it is not cold outside. The scores would be the same.
 You can get a slightly better score by taking into account bigrams or collections of two words at a time from the reference and generated sentence. By working with pairs of words you're acknowledging in a very simple way, the ordering of the words in the sentence. By using bigrams, you're able to calculate a ROUGE-2. Now, you can calculate the recall, precision, and F1 score using bigram matches instead of individual words. You'll notice that the scores are lower than the ROUGE-1 scores. With longer sentences, they're a greater chance that bigrams don't match, and the scores may be even lower.
You can get a slightly better score by taking into account bigrams or collections of two words at a time from the reference and generated sentence. By working with pairs of words you're acknowledging in a very simple way, the ordering of the words in the sentence. By using bigrams, you're able to calculate a ROUGE-2. Now, you can calculate the recall, precision, and F1 score using bigram matches instead of individual words. You'll notice that the scores are lower than the ROUGE-1 scores. With longer sentences, they're a greater chance that bigrams don't match, and the scores may be even lower.


Rather than continue on with ROUGE numbers growing bigger to n-grams of three or fours, let's take a different approach. Instead, you'll look for the longest common subsequence present in both the generated output and the reference output. In this case, the longest matching sub-sequences are, it is and cold outside, each with a length of two.
 You can now use the LCS value to calculate the recall precision and F1 score, where the numerator in both the recall and precision calculations is the length of the longest common subsequence, in this case, two. Collectively, these three quantities are known as the Rouge-L score.
You can now use the LCS value to calculate the recall precision and F1 score, where the numerator in both the recall and precision calculations is the length of the longest common subsequence, in this case, two. Collectively, these three quantities are known as the Rouge-L score.
 As with all of the rouge scores, you need to take the values in context. You can only use the scores to compare the capabilities of models if the scores were determined for the same task. For example, summarization. Rouge scores for different tasks are not comparable to one another. As you've seen, a particular problem with simple rouge scores is that it's possible for a bad completion to result in a good score. Take, for example, this generated output, cold, cold, cold, cold. As this generated output contains one of the words from the reference sentence, it will score quite highly, even though the same word is repeated multiple times. The Rouge-1 precision score will be perfect.
As with all of the rouge scores, you need to take the values in context. You can only use the scores to compare the capabilities of models if the scores were determined for the same task. For example, summarization. Rouge scores for different tasks are not comparable to one another. As you've seen, a particular problem with simple rouge scores is that it's possible for a bad completion to result in a good score. Take, for example, this generated output, cold, cold, cold, cold. As this generated output contains one of the words from the reference sentence, it will score quite highly, even though the same word is repeated multiple times. The Rouge-1 precision score will be perfect.

One way you can counter this issue is by using a clipping function to limit the number of unigram matches to the maximum count for that unigram within the reference. In this case, there is one appearance of cold and the reference and so a modified precision with a clip on the unigram matches results in a dramatically reduced score. However, you'll still be challenged if their generated words are all present, but just in a different order. For example, with this generated sentence, outside cold it is. This sentence was called perfectly even on the modified precision with the clipping function as all of the words and the generated output are present in the reference. Whilst using a different rouge score can help experimenting with a n-gram size that will calculate the most useful score will be dependent on the sentence, the sentence size, and your use case. Note that many language model libraries, for example, Hugging Face, which you used in the first week's lab, include implementations of rouge score that you can use to easily evaluate the output of your model. You'll get to try the rouge score and use it to compare the model's performance before and after fine-tuning in this week's lab.

The other score that can be useful in evaluating the performance of your model is the BLEU score, which stands for Bilingual Evaluation Understudy. Just to remind you that BLEU score is useful for evaluating the quality of machine-translated text. The score itself is calculated using the average precision over multiple n-gram sizes. Just like the Rouge-1 score that we looked at before, but calculated for a range of n-gram sizes and then averaged. Let's take a closer look at what this measures and how it's calculated. The BLEU score quantifies the quality of a translation by checking how many n-grams in the machine-generated translation match those in the reference translation.
To calculate the score, you average precision across a range of different n-gram sizes. If you were to calculate this by hand, you would carry out multiple calculations and then average all of the results to find the BLEU score. For this example, let's take a look at a longer sentence so that you can get a better sense of the scores value. The reference human-provided sentence is, I am very happy to say that I am drinking a warm cup of tea. Now, as you've seen these individual calculations in depth when you looked at rouge, I will show you the results of BLEU using a standard library. Calculating the BLEU score is easy with pre-written libraries from providers like Hugging Face and I've done just that for each of our candidate sentences. The first candidate is, I am very happy that I am drinking a cup of tea. The BLEU score is 0.495. As we get closer and closer to the original sentence, we get a score that is closer and closer to one.
Both rouge and BLEU are quite simple metrics and are relatively low-cost to calculate. You can use them for simple reference as you iterate over your models, but you shouldn't use them alone to report the final evaluation of a large language model. Use rouge for diagnostic evaluation of summarization tasks and BLEU for translation tasks. For overall evaluation of your model's performance, however, you will need to look at one of the evaluation benchmarks that have been developed by researchers. Let's take a look at some of these in more detail in the next video.
在整个课程中,你已经看到了诸如“该模型在这个任务上表现出良好的性能”或“这个微调过的模型比基础模型在性能上有了大幅度的提升”等表述。这些表述是什么意思?你如何正式地量化你的微调模型相比于你开始时使用的预训练模型的性能提升?让我们来探讨一些大型语言模型的开发者所使用的几种评估指标,你可以使用这些指标来评估自己模型的性能,并与世界上其他模型进行比较。
在传统的机器学习中,你可以通过查看模型在训练和验证数据集上的表现来评估模型的好坏,其中输出已经是已知的。由于模型是确定性的,你能够计算简单的指标,如准确率,它表示所有预测中正确的比例。但对于大型语言模型来说,输出是非确定性的,基于语言的评估要困难得多。例如,考虑这句话:“Mike真的喜欢喝茶。”这与“Mike喜爱品茶。”非常相似。但你如何衡量这种相似性呢?让我们来看看另外两个句子。“Mike不喝咖啡”和“Mike确实喝咖啡”。这两个句子之间只有一个词的差别。然而,意义完全不同。对于我们这样拥有柔软有机大脑的人类来说,我们可以看到相似之处和不同之处。但是当你在数百万个句子上训练一个模型时,你需要一种自动化、结构化的方法来进行测量。ROUGE和BLEU是两个广泛用于不同任务的评估指标。
ROUGE或面向召回率的幽默评估主要用于通过将它们与人工生成的参考摘要进行比较来评估自动生成摘要的质量。另一方面,BLEU或双语评估研究是一种旨在评估机器翻译文本质量的算法,同样,通过将其与人工生成的翻译进行比较。现在,单词BLEU是法语中的蓝色。你可能听到人们称它为蓝色,但在这里我将继续使用原始的BLEU。
在我们开始计算指标之前,让我们回顾一些术语。在语言的解剖学中,unigram相当于单个单词。bigram是两个单词,n-gram是n个单词的组。相当直接的东西。首先,让我们看看ROUGE-1指标。为此,让我们看一个人工生成的参考句子:“外面很冷”,以及一个生成的输出“外面真的很冷”。你可以使用召回率、精确度和F1分数执行类似于其他机器学习任务的简单指标计算。召回率指标测量参考和生成输出之间匹配的单词或unigram的数量除以参考中的单词或unigram的数量。在这种情况下,得分完美为1,因为所有生成的单词都与参考中的单词匹配。精确度测量unigram匹配数除以输出大小。F1分数是这两个值的调和平均数。
这些是非常基础的指标,只关注单个单词,因此名称中有“1”,不考虑单词的顺序。这可能是具有欺骗性的。很容易生成得分高但主观上差的句子。停下来想象一下,如果模型生成的句子只是一个单词不同会怎样。不是,所以外面不冷。得分会是相同的。通过考虑bigrams或同时从参考和生成句子中获取的两个单词的集合,你可以获得稍微好一些的得分。通过处理单词对,你以一种非常简单的方式承认了句子中单词的顺序。通过使用bigrams,你可以计算ROUGE-2。现在,你可以使用bigram匹配而不是单个单词来计算召回率、精确度和F1分数。你会注意到得分比ROUGE-1分数低。对于较长的句子,bigrams不匹配的机会更大,得分可能会更低。
与其继续计算越来越大的n-grams(三四个单词的组)的ROUGE数值,不如我们采取不同的方法。我们将寻找在生成的输出和参考输出中都存在的最长公共子序列。在这个例子中,最长的匹配子序列是“it is”和“cold outside”,每个长度为两个单词。你现在可以使用LCS(最长公共子序列)值来计算召回率、精确度和F1分数,其中召回率和精确度计算的分子是最长公共子序列的长度,在这个例子中是两个。这三个量合起来被称为Rouge-L分数。和所有的rouge分数一样,你需要在上下文中考虑这些值。只有在相同的任务上确定的分数,你才能用这些分数来比较模型的能力。例如,摘要任务。不同任务的rouge分数是不可相互比较的。正如你所看到的,简单rouge分数的一个特定问题是,一个糟糕的完成可能得到一个好分数。例如,这个生成的输出“冷,冷,冷,冷”。由于这个生成的输出包含了参考句子中的一个词,它的得分会相当高,即使同一个词被重复了多次。Rouge-1精确度分数将是完美的。
你可以使用一种剪辑功能来解决这个问题,它通过限制unigram匹配到参考中该unigram的最大计数来限制unigram匹配的数量。在这个例子中,“冷”在参考中出现了一次,所以修改后的精确度通过对unigram匹配进行剪辑导致分数大大降低。然而,如果生成的单词都存在,但只是顺序不同,你仍然会遇到挑战。例如,对于这个生成的句子“外面冷,它是。”即使是在使用剪辑功能的修改后的精确度上,这个句子也被完美地称为,因为所有生成的输出中的单词都在参考中出现。虽然使用不同的rouge分数可以帮助实验,但计算最有用的分数的n-gram大小将取决于句子、句子的大小和你的使用案例。请注意,许多语言模型库,例如你在第一周实验室中使用的Hugging Face,包括你可以使用来轻松评估模型输出的rouge分数的实现。在本周的实验室中,你将尝试rouge分数,并使用它来比较模型在微调之前和之后的性能。
另一个在评估模型性能时可能有用的分数是BLEU分数,即双语评估研究。提醒你,BLEU分数用于评估机器翻译文本的质量。该分数本身是使用多个n-gram大小的平均值计算的。就像我们之前看过的Rouge-1分数一样,但是为一系列n-gram大小计算然后取平均值。让我们更仔细地看看这是如何衡量和计算的。BLEU分数通过检查机器生成的翻译中有多少n-grams与参考翻译中的n-grams匹配来量化翻译的质量。
要计算这个分数,你需要在不同n-gram大小上平均精确度。如果你要手工计算,你会进行多次计算,然后平均所有结果以找到BLEU分数。对于这个例子,让我们看一个更长的句子,这样你可以更好地了解分数的价值。参考的人提供的句子是:“我很高兴地说我正在喝一杯热茶。”现在,当你在看rouge时已经深入了解了这些个别计算,我将向你展示使用标准库的BLEU结果。使用像Hugging Face这样的供应商提供的预写库计算BLEU分数很容易,我已经为我们每个候选句子做了这样的计算。第一个候选是:“我很高兴我正在喝茶。”BLEU分数是0.495。当我们越来越接近原始句子时,我们得到的分数越来越接近1。
Rouge和BLEU都是相当简单的指标,计算成本相对较低。你可以在迭代模型时使用它们作为简单的参考,但你不应该单独使用它们来报告大型语言模型的最终评估。使用Rouge对摘要任务进行诊断性评估,使用BLEU对翻译任务进行评估。然而,为了全面评估你的模型性能,你需要考虑研究人员开发的评估基准之一。让我们在下一段视频中更详细地看看这些。















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









