







0 环境准备
- ollama已部署推理模型deepseek-r1:8b
- ollama已部署嵌入模型quentinz/bge-large-zh-v1.5:latest
- 已安装miniconda环境
1 开发环境准备
1.1 创建开发python环境
conda create -n LangchainDemo python=3.101.2 pycharm创建项目
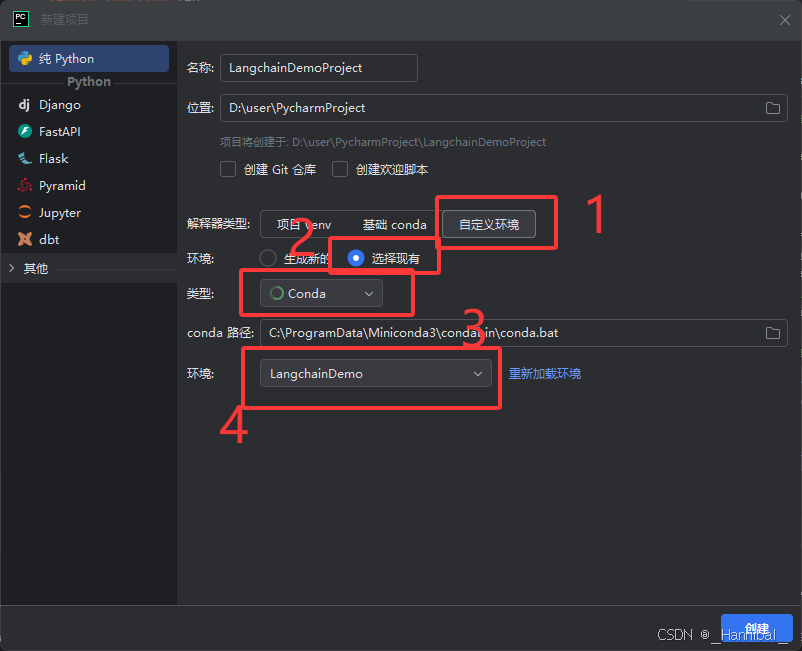
- 解释器类型:选择自定义环境
- 环境:选择现有
- 类型:选择conda
- 环境:选择上一步创建的环境
1.3 激活python环境
conda activate LangchainDemo1.4 安装langchain依赖包
pip install langchain
pip install langchain-community
pip install langchain-core
pip install langchain-experimental1.5 安装langchain-ollamayi依赖包
pip install langchain-ollama1.6 安装pypdf模块
pip install pypdf注意:在使用pip安装python依赖模块时一定要激活第一步创建的conda环境,后续开发都是在此环境下。
2 逻辑实现
2.1 导入相关依赖
import asyncio
from langchain_community.document_loaders import PyPDFLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_ollama import OllamaEmbeddings, ChatOllama
from langchain_text_splitters import CharacterTextSplitter2.2 加载本地pdf文件
file_path = (
"D:/QMDownload/数据库架构选型指南.pdf"
)
loader = PyPDFLoader(file_path)
pages = []
for page in loader.load():
pages.append(page.page_content)2.3 添加分段逻辑
text_splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=3000,
chunk_overlap=500,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents(pages)2.4 定义嵌入模型
ollama_baseurl = "http://localhost:11434"
embeddings_model = OllamaEmbeddings(
model="quentinz/bge-large-zh-v1.5:latest",
base_url=ollama_baseurl)2.5 将文档通过嵌入模型加载至内存
vector_store = InMemoryVectorStore.from_documents(
texts,
embeddings_model
)2.6 定义提示词模板
prompt = ChatPromptTemplate.from_template(
"""
请根据上下文之间输出最终答案,不要包含任何推理过程,如果不知道答案,请输出不知道
上下文: {context}
问题: {question}
答案:
"""
)2.7 定义推理模型
model_name = "deepseek-r1:8b"
chat_llm = ChatOllama(
model=model_name,
base_url=ollama_baseurl
)2.8 构建langchain执行链
setup_retriever = RunnableParallel({"context": vector_store.as_retriever(), "question" : RunnablePassthrough()})
chain = setup_retriever | prompt | chat_llm | StrOutputParser()2.9 定义流式输出
async def stream_data():
async for chunk in chain.astream("爱奇艺选用了哪些数据库?"):
print(chunk, flush=True, end="")
if __name__ == "__main__":
loop = asyncio.get_event_loop()
asyncio.set_event_loop(loop)
loop.run_until_complete(stream_data())3 测试
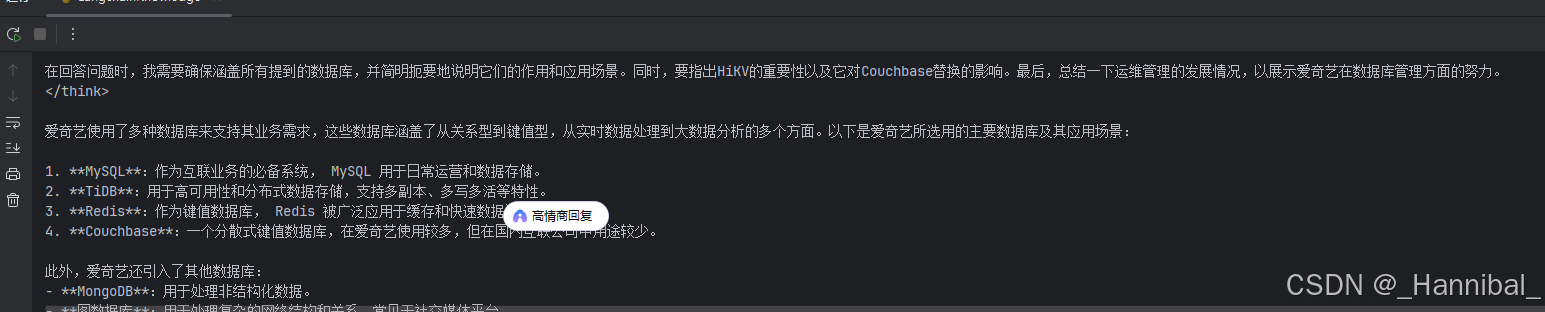
执行程序,可看到执行结果如下图

















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









