







 文章介绍了如何利用Arcgis免费访问和应用全国地质资料馆提供的地质数据。首先,用户需要安装Arcgis客户端,然后添加GIS服务器,分别引用基础数据服务和业务图层服务。通过在Arcmap中拖拽对应的图层,用户可以在客户端进行查询和修改,尽管坐标系统经过处理,不适合严格定位。文章提供了详细的步骤和相关网址。
文章介绍了如何利用Arcgis免费访问和应用全国地质资料馆提供的地质数据。首先,用户需要安装Arcgis客户端,然后添加GIS服务器,分别引用基础数据服务和业务图层服务。通过在Arcmap中拖拽对应的图层,用户可以在客户端进行查询和修改,尽管坐标系统经过处理,不适合严格定位。文章提供了详细的步骤和相关网址。
使用Arcgis免费使用全国地质数据
如今是大数据并发的时代,并且还是数据大开放的时代。全国地质资料馆开放了大量的地质资料数据,供全民使用。今天我在这里教大家使用免费的数据,帮助我们工作。
全国地质资料馆地址:
http://www.ngac.org.cn
国家数字地质资料馆:
http://data.ngac.org.cn/arcgis/geoonline/viewer/index.html
以上的两个网址是我们都能在中国境内轻松打开的网站,由于这两个网站的开发基层都是Arcgis平台,而且发布出来的数据都是以WMST服务发布出来的,当然我们我可以在网站上免费的浏览,但是对于我们地质工作者,我们更想做的是怎么应用这些数据并在此基础上作出一定的修改。
因此接下来我讲解如何应用这些地图数据最终能达到以下的效果,方便我们在客户端进行查询甚至在此地图的基础上划出自己的感兴趣区域导出图片(.jpg)。
1.首先你需要安装10.0版本以上的Arcgis客户端,目前版本到了10.7版本,这里推荐10.2版本,目前较为流行。
这里提供大家一个下载的地址:
链接:
https://pan.baidu.com/s/1CBmBWg_7YYjtg60NNf0pnw&shfl=sharepset
提取码:
5qud
2.打开国家数字地质资料馆

找到 基础数据服务--矿产地分布2019
我们打开这个链接,发现内容如下。
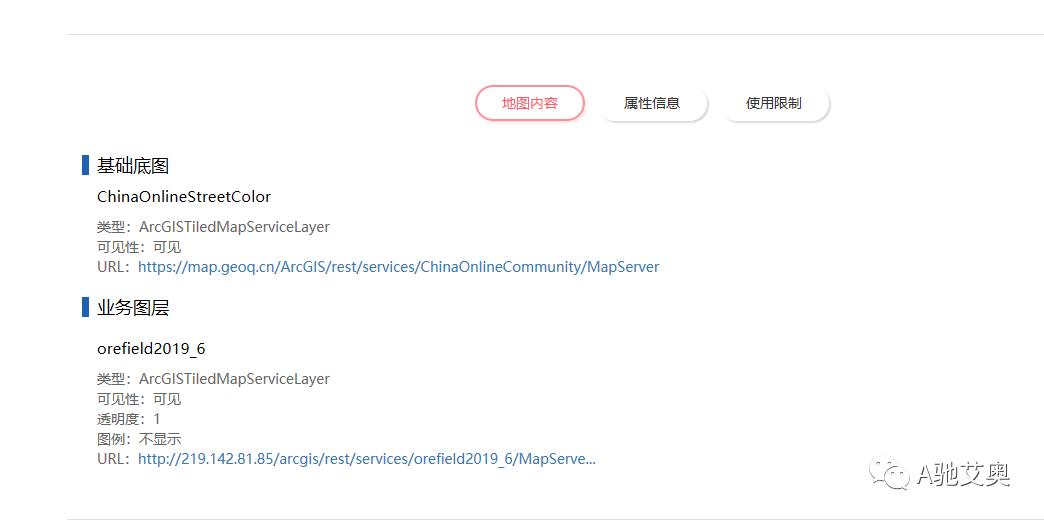
其中基础地图为ChinaOnlineStreetColor
URL:https://map.geoq.cn/ArcGIS/rest/services/ChinaOnlineCommunity/MapServer业务图层为orefield20196
URL:http://219.142.81.85/arcgis/rest/services/orefield20196/MapServer
这里我们不进行任何操作只是记住这些基础图层和业务图层即可。
3. 添加GIS服务器
打开我们的arcmap,在数据目录中,我们找到,如下图所示的路径
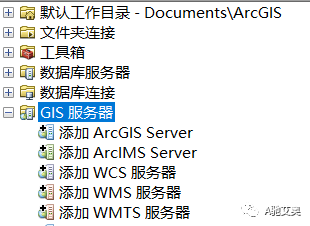
GIS服务器--添加ArcGIS Server -- 使用GIS服务
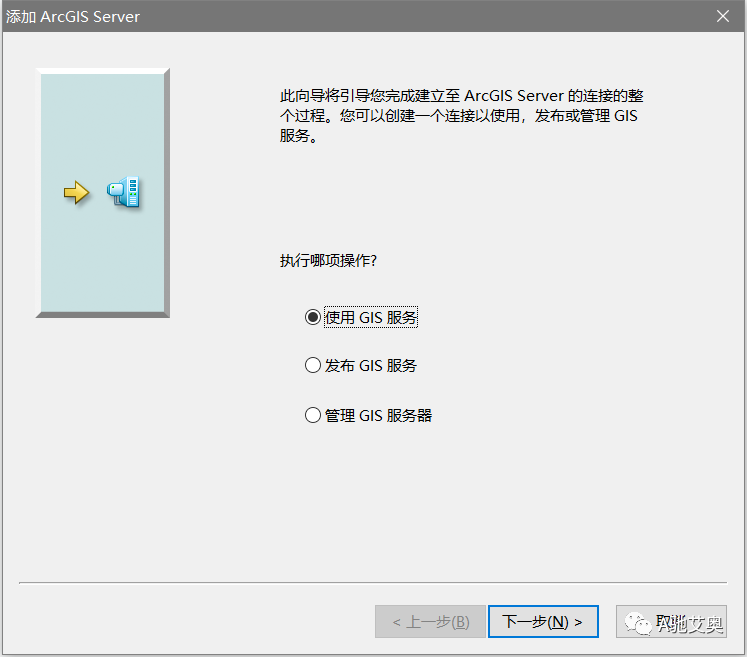
分别两次添加业务图层服务和基础数据服务,只需填写路径即可,不需要填写用户名和密码
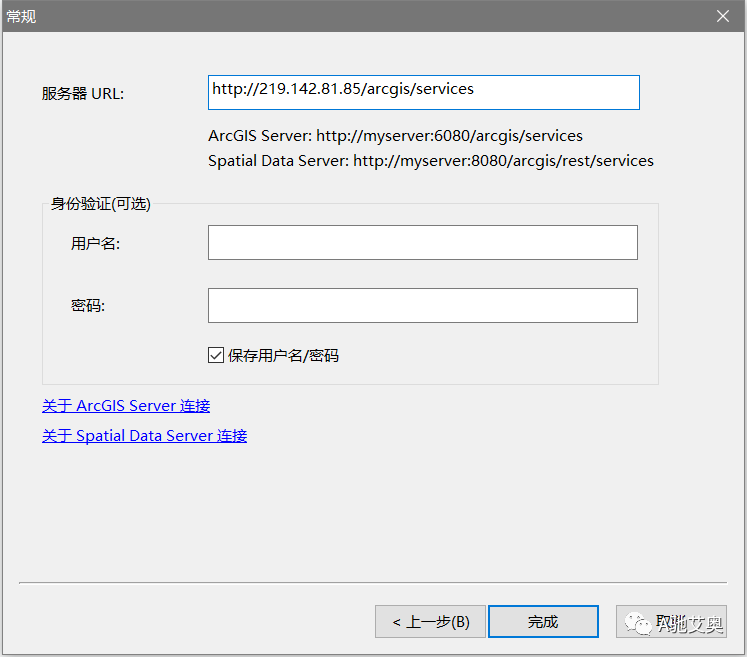
业务图层服务:
http://219.142.81.85/arcgis/services
基础数据服务:
https://map.geoq.cn/ArcGIS/services
给大家的这两个数据服务,将全国地质数据库的所有地图数据服务都加载到了Arcgis中。
4.区分数据并引用
在这一步中我们需要给我们两个数据服务重命名,方便大家知道。
"ArcGIS on map.geoq.cn (用户)"重命名为"基础数据图层库"里面是中国的基本地形图
"arcgis on 219.142.81.85 (用户)重命名为"业务数据图层库"里面是中国全部相关的地址资料成果。
我们打开每个数据将会看到有众多的数据,一开始不知道引用那一个,不用着急,你还记得第二步那两个图层吗,找到对应的图层。拖拽到视图中,便得到了。我们需要的结果。
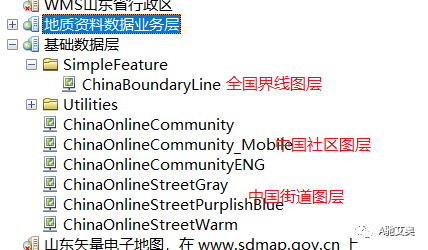
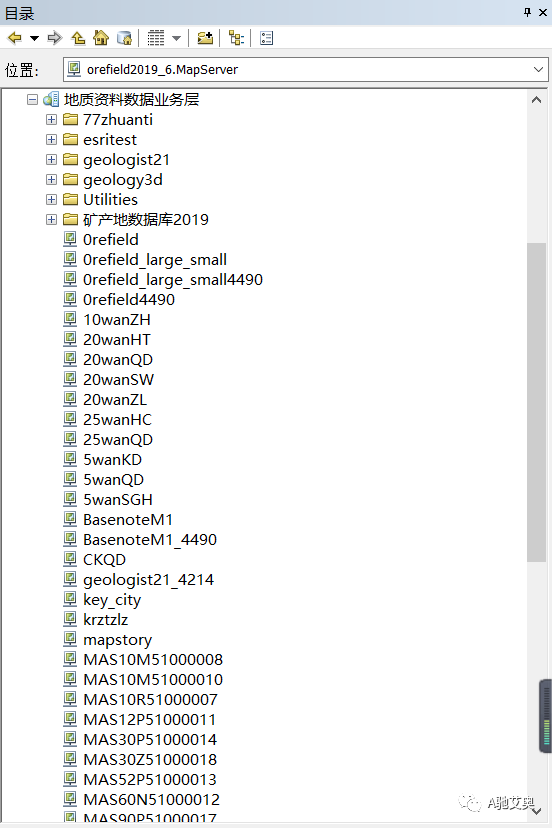
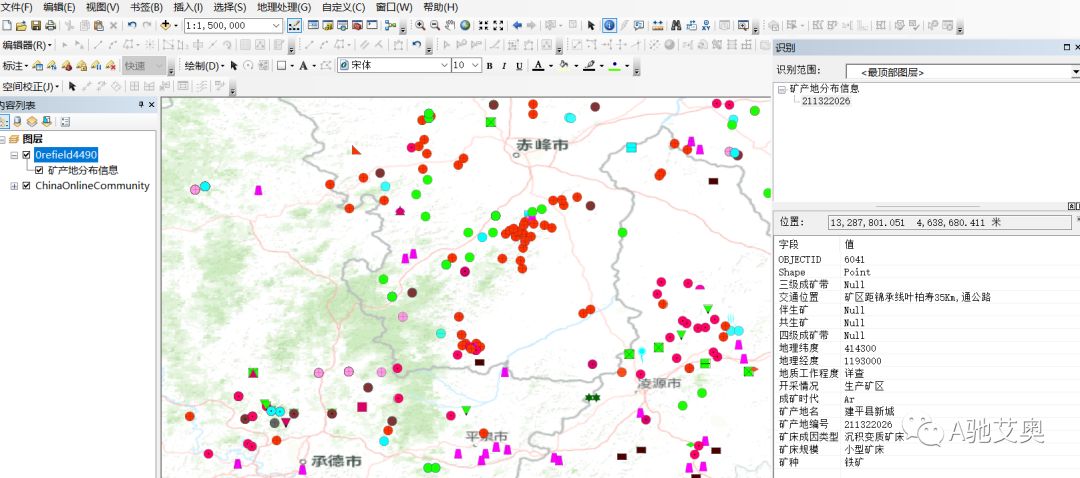
我们看一下成图的效果
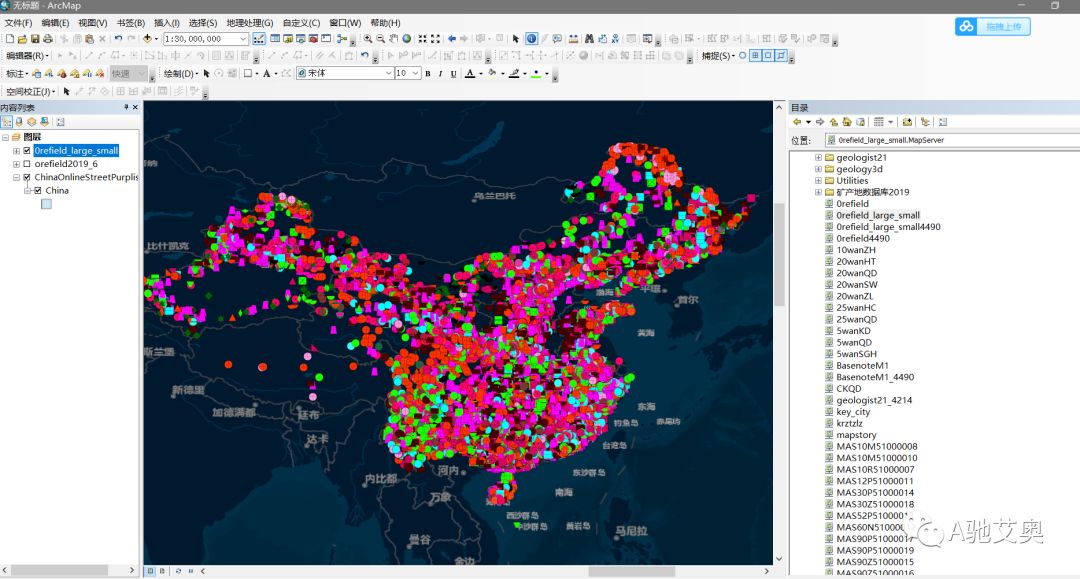
放在了ARCGIS中我们便可以在此基础上进行查询。
查询功能
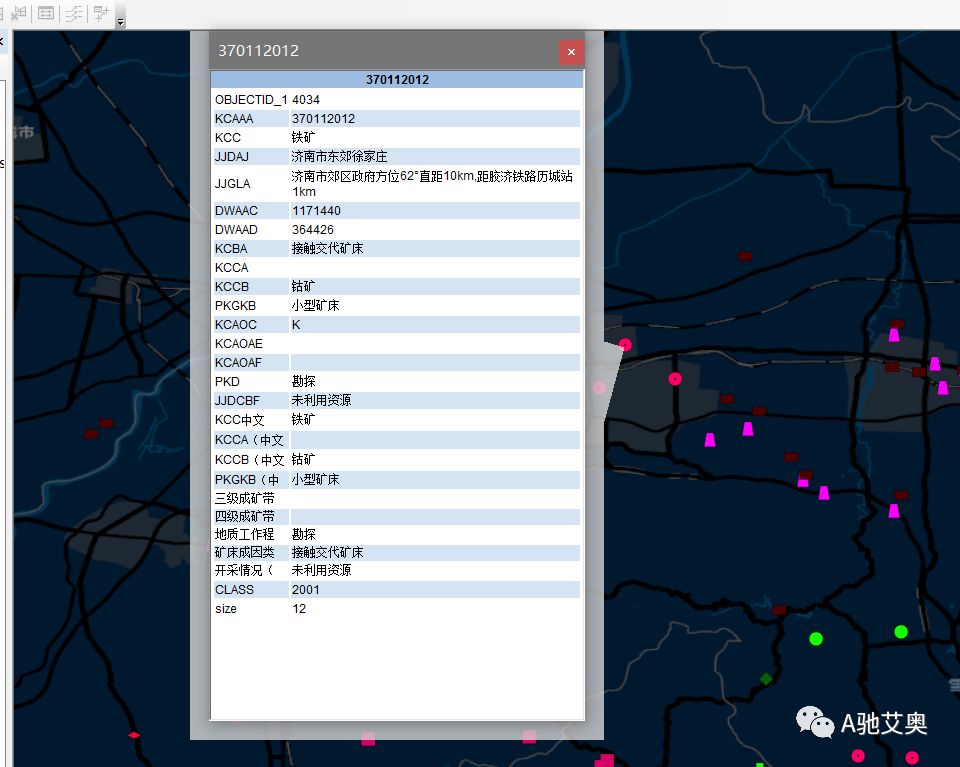
这里需要注意的是,所有的坐标系统都经过了一定脱密处理,只能以此为根源作图,但并不能把它作为严格的定位工具进行使用。
以上来源:A驰艾奥

















 206
206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









