







误差的来源及降低误差的训练算法
1. 误差的来源
机器学习的泛化误差来源于三个方面:
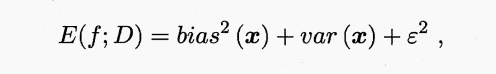
依次是偏差,方差和数据噪声。
偏差:度量了学习算法的期望预测与真实结果间的偏离程度,且是二次方的形式贡献在最后预期期望中。偏差刻画了学习算法本身的拟合能力。
方差:度量了同样大小的训练集变动时,该模型学习性能的变化,刻画了数据扰动所造成影响。
数据噪声:表达了当前模型所能达到的一个误差下界,一定程度代表了该问题本身的学习难度。
总结来说,方差偏差误差分析指出,一个算法所能达到的泛化性能,由算法本身学习能力(偏差),数据的充分性(方差)及学习任务本身难度(偏差)共同决定。
但对于一个给定的学习任务,可能数据噪声是无法改变的,因此要达到好的学习效果,及好的泛化性能,则需要使偏差较小,即能充分拟合数据,且使方差较小,即数据扰动带来的影响小。
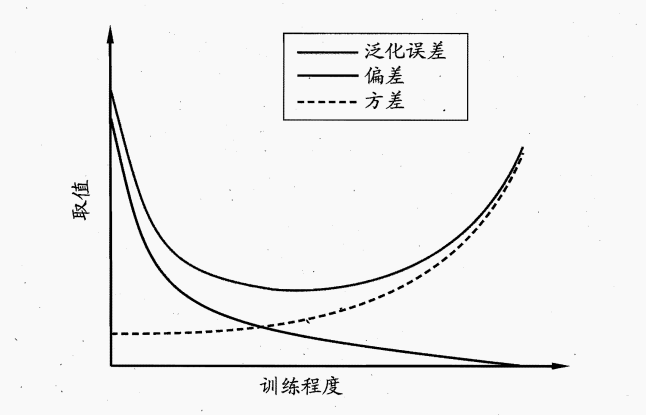
但是,偏差和方差是具有冲突的,就是所谓的偏差-方差窘境,及方差小必然会导致偏差大,而偏差小则方差就大。偏差小代表模型学习能力强,但是一旦学习能力强,则各种细节就会学习进去,导致受训练数据波动影响大。而不受数据波动影响的学习模型,则拟合能力相对来说却偏弱。
2.降低误差的训练算法
下降的方向:梯度
降低误差的算法主要工作流程分两步,确定更新方向和沿着更新方向更新的大小,及梯度和学习步长。
梯度下降,是对Loss函数求变量的偏导数,然后在原有变量的基础之上,沿着偏导数的方向下降
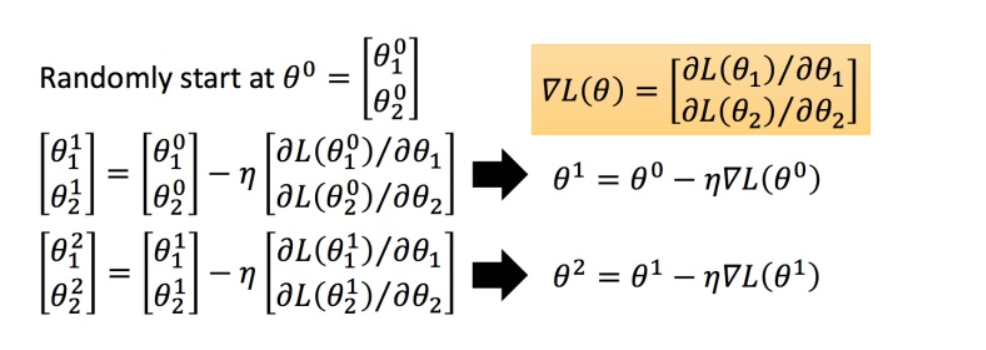
其中最后的算子就是在 $\theta^0 $ 处求偏导,以偏导为方向,乘以学习率,然后在$\theta^0 上 减 去 这 个 更 新 , 得 到 新 的 参 数 上减去这个更新,得到新的参数 上减去这个更新,得到新的参数\theta^1 $,这个新的参数处再求偏导,再乘以步长,再在这个新参数上减去这个更新,于是就得到下一次参与更新的参数,然后继续更新下去,直到更新量小于某个值,此时认为参数收敛,处于导数零点处,那么就可以停止更新了。
下降的大小:学习率
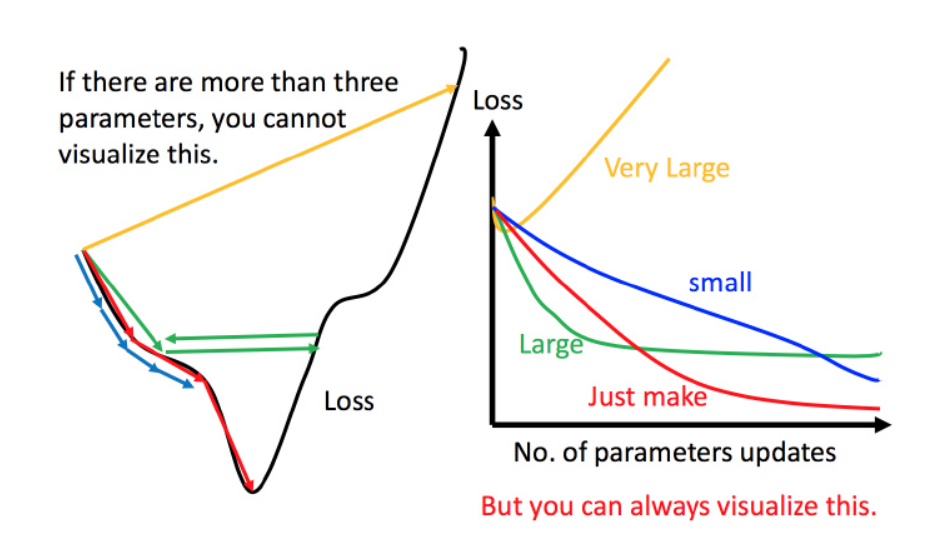
当使用固定学习率时,不同学习率对算法能否收敛很重要,如上图所示,绿色学习率导致左右震荡,无法走到谷底,红色和蓝色都能走到谷底,但蓝色需要走很久,没有红色那么快速。黄色直接跳出了山谷,就是所谓的发散了。
我们知道,调节一个仪器时,一般都是先粗调再细调,好学习率的调整也基本如此,是动态调整的,开始学习步长会大一些,但之后会自动减少。这称为自适应学习率。
3.训练技巧
这里介绍了两种训练技巧,随机梯度下降和特征缩放。
随机梯度下降相比于批梯度下降,在训练大数据集时能加快迭代速度,缺点是更新次数会很多,是一种时间换空间的做法,毕竟数据量十分庞大时做不到把所有数据都加到内存里。
特征缩放属于特征工程的内容,进行数据训练时,对同一程度上的特征进行更新,会使更新相对平衡地作用到每个特征个,更新的效率更高,收敛速度更快。
参考
1.西瓜书-周志华
2.P5 误差从哪来? (datawhalechina.github.io)
//datawhalechina.github.io/leeml-notes/#/chapter5/chapter5)

















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









