






在机器学习的领域中,支持向量机(Support Vector Machine,简称SVM)以其独特的魅力和广泛的应用价值而备受瞩目。SVM的基本思想是通过在特征空间上找到最佳的分离超平面,以使得不同类别的样本点分开,并且距离这个超平面尽可能远。在这个过程中,样本点的作用举足轻重,它们扮演着三种不同的角色,共同构筑了SVM的坚实基石。
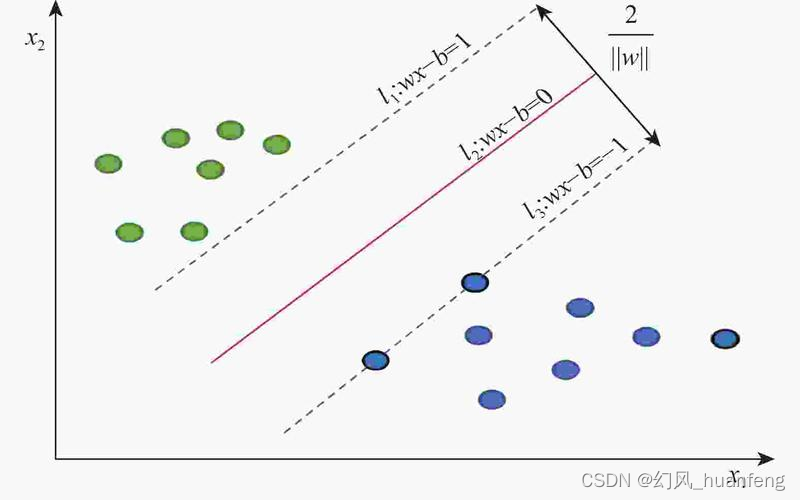
一、支持向量:模型的“基石”
支持向量,无疑是SVM中最核心、最引人注目的样本点。它们位于分类边界上,是确定最优超平面的关键因素。在模型训练过程中,支持向量通过最大化间隔的方式,帮助算法找到最佳的分类边界。换句话说,如果没有支持向量的存在,SVM将无法构建有效的分类模型。因此,我们可以将支持向量视为SVM模型的“基石”。
支持向量的重要性不仅体现在其独特的位置上,更在于其对模型性能的决定性影响。在SVM中,只有支持向量才会对分类决策产生影响,而其他样本点则被视为“背景色”,对模型的构建没有直接影响。这种特性使得SVM在处理高维数据和大规模数据集时具有显著的优势,因为它只需要关注一小部分关键样本点,而无需对所有数据进行处理。
此外,支持向量还具有强大的泛化能力。由于它们位于分类边界上,因此能够反映数据集的边界分布情况。这意味着当新的样本点出现时,SVM能够利用这些已知的支持向量来做出准确的分类决策,从而实现对新数据的良好适应。
二、边界向量:模型的“守护者”
除了支持向量外,还有一类样本点同样值得关注,那就是边界向量。它们虽然不像支持向量那样直接参与最优超平面的构建,但却对模型的性能产生着重要影响。边界向量位于分类边界附近,是支持向量与非支持向量之间的过渡区域。它们的存在为模型提供了额外的信息,有助于算法更全面地理解数据分布特性。
在SVM中,边界向量的作用主要体现在两个方面。首先,它们能够帮助算法更准确地判断新样本点的类别。由于边界向量位于分类边界附近,因此它们对新样本点的分类决策具有一定的影响力。当新样本点出现时,SVM会综合考虑其与支持向量和边界向量的距离关系,从而做出更准确的分类决策。其次,边界向量还能够提高模型的鲁棒性。由于它们位于分类边界附近,因此能够反映数据集的噪声和异常值情况。当数据集存在噪声或异常值时,SVM会利用边界向量来降低这些噪声对模型性能的影响,从而提高模型的鲁棒性。
三、非支持向量:模型的“背景色”
在SVM中,除了支持向量和边界向量外,其余的样本点被称为非支持向量。这些样本点远离分类边界,对最优超平面的构建没有直接影响。然而,它们并非毫无价值。非支持向量的存在为模型提供了丰富的背景信息,有助于算法更全面地理解数据分布特性。
虽然非支持向量在SVM的决策过程中不直接发挥作用,但它们在模型的训练和评估过程中却具有不可忽视的作用。首先,非支持向量能够作为模型的训练数据之一,为算法提供足够的信息来学习数据分布特性。其次,非支持向量还能够作为模型的测试数据之一,用于评估模型的性能和泛化能力。通过对比模型在训练集和测试集上的表现,我们可以更全面地了解模型的优缺点和改进方向。
此外,非支持向量还能够为模型提供额外的信息来源。在实际应用中,我们经常会遇到一些特殊的样本点,它们可能具有特殊的性质或特征,但却不位于分类边界上。这些样本点可以被视为非支持向量,并用于为模型提供额外的信息来源。例如,在文本分类任务中,一些特殊的词汇或短语可能具有特殊的含义或情感倾向,但却不经常出现在文本中。这些特殊的词汇或短语可以被视为非支持向量,并用于为模型提供额外的情感信息来源。















 3723
3723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











