







10. EM算法(Expectation Maximization)
本章主要内容:
- 凸集,凸函数,凹集,凹函数的概念
- Jensen’s inequality
- KL散度(相对熵)
- EM算法两步迭代过程与收敛性证明
- 广义EM算法与狭义EM算法
10.1 EM算法公式以及算法收敛性证明
E
x
p
e
c
t
a
t
i
o
n
M
a
x
i
m
i
z
a
t
i
o
n
(
E
M
)
\color{red}Expectation\;Maximization (EM)
ExpectationMaximization(EM)算法,中文名字叫做“期望最大”算法。是用来解决
具
有
隐
变
量
的
混
合
模
型
的
高
斯
分
布
\color{red}具有隐变量的混合模型的高斯分布
具有隐变量的混合模型的高斯分布。对于简单的问题,可以直接得出参数的解析解,比如:MLE(极大似然估计(例子)):
p
(
x
∣
θ
)
p(x|\theta)
p(x∣θ)。我们想要求解的结果就是:
θ
M
L
E
=
arg
max
θ
log
p
(
x
∣
θ
)
.
(10.1.1)
\theta_{MLE} = \arg\max_{\theta}\log p(x|\theta).\tag{10.1.1}
θMLE=argθmaxlogp(x∣θ).(10.1.1)
其中
log
p
(
x
∣
θ
)
\log p(x|\theta)
logp(x∣θ)称为对数似然函数。一旦问题变得复杂,就不是这么简单了,特别是引入了隐变量之后,此时我们要用上EM算法(例子)。
10.1.1 EM算法简述
-
假设有如下数据:
- X X X:observed data
- Z Z Z:unobserved data(latent variable),分布为 q ( z ) q(z) q(z)
- ( X , Z ) (X,Z) (X,Z):complete data
- θ \theta θ:parameter
-
EM算法的目的是解决具有隐变量的参数估计(MLE、MAP)问题。因此对MLE引入隐变量得EM的基本表达式是: θ ( t + 1 ) = a r g max θ ∫ z log p ( x , z ∣ θ ) ⋅ p ( z ∣ x , θ ( t ) ) d z . (10.1.2) \color{red}\theta^{(t+1)}=arg\underset{\theta}{\max} \int_z \log p(x,z|\theta)\cdot p(z|x,\theta^{(t)})dz.\tag{10.1.2} θ(t+1)=argθmax∫zlogp(x,z∣θ)⋅p(z∣x,θ(t))dz.(10.1.2)
其中:- θ ( t ) \theta^{(t)} θ(t)表示 t t t时刻的参数;
- p ( z ∣ x , θ ( t ) ) p(z|x,\theta^{(t)}) p(z∣x,θ(t))是后验;
- log p ( x , z ∣ θ ) \log p(x,z|\theta) logp(x,z∣θ)是完整数据,对数联合概率。
-
EM算法是一种迭代的算法,我们的目标是求:
θ ( t + 1 ) = arg max θ ∫ z p ( x , z ∣ θ ) p ( z ∣ x , θ ( t ) ) d z = arg max θ E z ∼ p ( z ∣ x , θ ( t ) ) [ log p ( x , z ∣ θ ) ] (10.1.3) \color{red}\begin{array}{l}\theta^{(t+1)} &= \arg\underset{\theta}{\max} \int_z p(x,z|\theta)p(z|x,\theta^{(t)})dz \\ &= \arg\underset{\theta}{\max}\; \mathbb{E}_{z \sim p(z|x,\theta^{(t)})}[\log p(x,z|\theta)]\end{array}\tag{10.1.3} θ(t+1)=argθmax∫zp(x,z∣θ)p(z∣x,θ(t))dz=argθmaxEz∼p(z∣x,θ(t))[logp(x,z∣θ)](10.1.3)
EM算法的目标:找到一个更新的参数 θ \theta θ,使得 log p ( x , z ∣ θ ) \log p(x,z|\theta) logp(x,z∣θ)出现的概率更大。 -
E M 算 法 ( 公 式 ( 10.1.3 ) ) 分 为 两 步 \color{red}EM算法(公式(10.1.3))分为两步 EM算法(公式(10.1.3))分为两步:
- 第一步是E:求出期望;
固定 θ ( t ) \theta^{(t)} θ(t),改变 q ( z ) q(z) q(z),使得 K L ( q ( z ) ∣ ∣ p ( z ∣ x , θ ) ) = − ∫ z q ( z ) l o g p ( z ∣ x , θ ) q ( z ) d z = 0 {KL(q(z)||p(z|x,\theta ))}={-\int _{z}q(z)log\; \frac{p(z|x,\theta )}{q(z)}\mathrm{d}z}=0 KL(q(z)∣∣p(z∣x,θ))=−∫zq(z)logq(z)p(z∣x,θ)dz=0,因此: log p ( x ∣ θ ( t ) ) = ∫ z q ( z ) l o g p ( x , z ∣ θ ) q ( z ) d z = E L B O . \color{red}\log\; p(x|\theta ^{(t)})={\int _{z}q(z)log\; \frac{p(x,z|\theta )}{q(z)}\mathrm{d}z}=ELBO. logp(x∣θ(t))=∫zq(z)logq(z)p(x,z∣θ)dz=ELBO.
- 第二步是M:将期望最大化。
固定 q ( z ) q(z) q(z),极大化 θ ( t + 1 ) = arg max θ E z ∼ P ( z ∣ x , θ ( t ) ) [ log P ( x , z ∣ θ ) ] \color{red}\theta^{(t+1)} = \arg\underset{\theta}{\max} \mathbb{E}_{z\sim P(z|x,\theta^{(t)})}\left[ \log P(x,z|\theta) \right] θ(t+1)=argθmaxEz∼P(z∣x,θ(t))[logP(x,z∣θ)]
更深入的了解:EM算法的实例
可以从下图理解:其中 F ( . . . ) F(...) F(...)表示 l o w b o u n d low\; bound lowbound,为 E L B O ELBO ELBO。

- 第一步是E:求出期望;
10.2 从ELBO+KL Divergence角度进行EM算法公式推导
10.2.1 概述
-
回顾
机器学习的模型实际上就可以看成是一堆的参数。极大似然估计的思想是求解:
θ M L E = log P ( x ∣ θ ) (10.2.1) \theta_{MLE} = \log P(x|\theta)\tag{10.2.1} θMLE=logP(x∣θ)(10.2.1)
其中:- X X X为observed data;
- Z Z Z为latent data,分布为 q ( z ) q(z) q(z);
- ( X , Z ) (X,Z) (X,Z)为complete data;
- θ \theta θ为parameter。
对于 具 有 隐 变 量 的 混 合 模 型 的 高 斯 分 布 \color{red}具有隐变量的混合模型的高斯分布 具有隐变量的混合模型的高斯分布,EM公式就被我们描述为:
θ ( t + 1 ) = arg max θ ∫ z log P ( x , z ∣ θ ) P ( z ∣ x , θ ( t ) ) d z . (10.2.2) \theta^{(t+1)} = \arg\max_{\theta} \int_z \log P(x,z|\theta)P(z|x,\theta^{(t)}) dz.\tag{10.2.2} θ(t+1)=argθmax∫zlogP(x,z∣θ)P(z∣x,θ(t))dz.(10.2.2) -
EM算法的步骤
EM算法可以被我们分解成E-step和M-step两个部分。- E(Expectation)-step: P ( z ∣ x , θ ( t ) ) ⟶ E z ∼ P ( z ∣ x , θ ( t ) ) [ log P ( x , z ∣ θ ) ] \color{red}P(z|x,\theta^{(t)}) \longrightarrow \mathbb{E}_{z\sim P(z|x,\theta^{(t)})}\left[ \log P(x,z|\theta) \right] P(z∣x,θ(t))⟶Ez∼P(z∣x,θ(t))[logP(x,z∣θ)]
- M(Maximization)-step:
θ
(
t
+
1
)
=
arg
max
θ
E
z
∼
P
(
z
∣
x
,
θ
(
t
)
)
[
log
P
(
x
,
z
∣
θ
)
]
\color{red}\theta^{(t+1)} = \arg\underset{\theta}{\max} \mathbb{E}_{z\sim P(z|x,\theta^{(t)})}\left[ \log P(x,z|\theta) \right]
θ(t+1)=argθmaxEz∼P(z∣x,θ(t))[logP(x,z∣θ)]
上一章已经证明了EM算法的收敛性,即:
log P ( x ∣ θ ( t + 1 ) ) ≥ log P ( x ∣ θ ( t ) ) \log P(x|\theta^{(t+1)}) \geq \log P(x|\theta^{(t)}) logP(x∣θ(t+1))≥logP(x∣θ(t))
本节的目标就是推导EM算法公式(10.2.2)究竟是怎么来的。
10.2.2 从ELBO+KL散度的角度推到EM步骤
-
E ( E x p e c t a t i o n ) − s t e p : K L = 0 , log p ( x ∣ θ t ) = E L B O \color{blue}E(Expectation)-step:\;KL=0,\; \log\; p(x|\theta ^{t})=ELBO E(Expectation)−step:KL=0,logp(x∣θt)=ELBO
对 log p ( x ∣ θ ) \log\; p(x|\theta ) logp(x∣θ)进行处理:
log p ( x ∣ θ ) = log p ( x , z ∣ θ ) − log p ( z ∣ x , θ ) = log p ( x , z ∣ θ ) q ( z ) − log p ( z ∣ x , θ ) q ( z ) ( q ( z ) ≠ 0 ) . (10.2.3) \begin{aligned}\log\; p(x|\theta )&=\log\; p(x,z|\theta )- \log\; p(z|x,\theta )\\ &=\log\; \frac{p(x,z|\theta )}{q(z)}-\log\; \frac{p(z|x,\theta )}{q(z)}\; \; (q(z)\neq 0).\end{aligned}\tag{10.2.3} logp(x∣θ)=logp(x,z∣θ)−logp(z∣x,θ)=logq(z)p(x,z∣θ)−logq(z)p(z∣x,θ)(q(z)=0).(10.2.3)
公式(10.2.3)引入一个关于 z 的 概 率 分 布 为 q ( z ) \color{blue}z的概率分布为q(z) z的概率分布为q(z),然后式子两边同时求对 q ( z ) q(z) q(z)的期望
左 边 = ∫ z q ( z ) ⋅ l o g p ( x ∣ θ ) d z = l o g p ( x ∣ θ ) ∫ z q ( z ) d z = l o g p ( x ∣ θ ) . (10.2.4) 左边=\int _{z}q(z)\cdot log\; p(x|\theta )\mathrm{d}z=log\; p(x|\theta )\int _{z}q(z)\mathrm{d}z=log\; p(x|\theta ).\tag{10.2.4} 左边=∫zq(z)⋅logp(x∣θ)dz=logp(x∣θ)∫zq(z)dz=logp(x∣θ).(10.2.4)
右 边 = ∫ z q ( z ) l o g p ( x , z ∣ θ ) q ( z ) d z ⏟ E L B O ( e v i d e n c e l o w e r b o u n d ) − ∫ z q ( z ) l o g p ( z ∣ x , θ ) q ( z ) d z ⏟ K L ( q ( z ) ∣ ∣ p ( z ∣ x , θ ) ) . (10.2.5) 右边=\underset{ELBO(evidence\; lower\; bound)}{\underbrace{\int _{z}q(z)log\; \frac{p(x,z|\theta )}{q(z)}\mathrm{d}z}}\underset{KL(q(z)||p(z|x,\theta ))}{\underbrace{-\int _{z}q(z)log\; \frac{p(z|x,\theta )}{q(z)}\mathrm{d}z}}.\tag{10.2.5} 右边=ELBO(evidencelowerbound) ∫zq(z)logq(z)p(x,z∣θ)dzKL(q(z)∣∣p(z∣x,θ)) −∫zq(z)logq(z)p(z∣x,θ)dz.(10.2.5)
因此我们得出 l o g p ( x ∣ θ ) = E L B O + K L ( q ( z ) ∣ ∣ p ( z ∣ x , θ ) ) \color{red}log\; p(x|\theta )=ELBO+KL(q(z)||p(z|x,\theta )) logp(x∣θ)=ELBO+KL(q(z)∣∣p(z∣x,θ)):-
由于KL散度恒 ≥ 0 \geq0 ≥0,因此 log p ( x ∣ θ ) ≥ E L B O \color{red}\log\; p(x|\theta )\geq ELBO logp(x∣θ)≥ELBO,则 E L B O 就 是 似 然 函 数 log p ( x ∣ θ ) 的 下 界 \color{blue}ELBO就是似然函数\log\; p(x|\theta )的下界 ELBO就是似然函数logp(x∣θ)的下界。
-
当 log p ( x ∣ θ ) = E L B O \color{red}\log\; p(x|\theta )=ELBO logp(x∣θ)=ELBO,就必须有 K L ( q ( z ) ∣ ∣ p ( z ∣ x , θ ) ) = 0 KL(q(z)||p(z|x,\theta ))=0 KL(q(z)∣∣p(z∣x,θ))=0,根据 KL散度的定义, 也就是 q ( z ) = p ( z ∣ x , θ ) \color{blue}q(z)=p(z|x,\theta ) q(z)=p(z∣x,θ)。

-
在每次迭代中取:
q ( z ) = p ( z ∣ x , θ ( t ) ) (10.2.6) \color{red}q(z)=p(z|x,\theta ^{(t)})\tag{10.2.6} q(z)=p(z∣x,θ(t))(10.2.6)
就可以保证 l o g p ( x ∣ θ t ) log\; p(x|\theta ^{t}) logp(x∣θt)与 E L B O ELBO ELBO相等。也就是当 θ = θ ( t ) 时 , l o g p ( x ∣ θ t ) \theta =\theta ^{(t)}时,log\; p(x|\theta ^{t}) θ=θ(t)时,logp(x∣θt)取 E L B O ELBO ELBO:
log p ( x ∣ θ ( t ) ) = ∫ z p ( z ∣ x , θ ( t ) ) l o g p ( x , z ∣ θ ( t ) ) p ( z ∣ x , θ ( t ) ) d z ⏟ E L B O − ∫ z p ( z ∣ x , θ ( t ) ) l o g p ( z ∣ x , θ ( t ) ) p ( z ∣ x , θ ( t ) ) d z ⏟ = 0 = E L B O . (10.2.7) \begin{aligned}\log\; p(x|\theta ^{(t)})&=\underset{ELBO}{\underbrace{\int _{z}p(z|x,\theta ^{(t)})log\; \frac{p(x,z|\theta ^{(t)})}{p(z|x,\theta ^{(t)})}\mathrm{d}z}}\underset{=0}{\underbrace{-\int _{z}p(z|x,\theta ^{(t)})log\; \frac{p(z|x,\theta ^{(t)})}{p(z|x,\theta ^{(t)})}\mathrm{d}z}} \\&=ELBO\end{aligned}.\tag{10.2.7} logp(x∣θ(t))=ELBO ∫zp(z∣x,θ(t))logp(z∣x,θ(t))p(x,z∣θ(t))dz=0 −∫zp(z∣x,θ(t))logp(z∣x,θ(t))p(z∣x,θ(t))dz=ELBO.(10.2.7)
-
-
M ( M a x i m i z a t i o n ) − s t e p : E L B O 与 log p ( x ∣ θ ) \color{blue}M(Maximization)-step:ELBO与\log\; p(x|\theta ) M(Maximization)−step:ELBO与logp(x∣θ)
- 根据公式(10.2.7)可得: l o g p ( x ∣ θ ) log\; p(x|\theta ) logp(x∣θ)与ELBO都是关于 θ \theta θ的函数,且满足 l o g p ( x ∣ θ ) ≥ E L B O log\; p(x|\theta )\geq ELBO logp(x∣θ)≥ELBO,也就是说 log p ( x ∣ θ ) 的 图 像 总 是 在 E L B O 的 图 像 的 上 面 \color{blue}\log\; p(x|\theta )的图像总是在ELBO的图像的上面 logp(x∣θ)的图像总是在ELBO的图像的上面。
- 对于
q
(
z
)
q(z)
q(z),我们取
q
(
z
)
=
p
(
z
∣
x
,
θ
t
)
q(z)=p(z|x,\theta ^{t})
q(z)=p(z∣x,θt),这也就保证了只有在
θ
=
θ
(
t
)
时
l
o
g
p
(
x
∣
θ
)
\theta =\theta ^{(t)}时log\; p(x|\theta )
θ=θ(t)时logp(x∣θ)与
E
L
B
O
ELBO
ELBO才会相等,因此:
使
E
L
B
O
取
极
大
值
的
θ
(
t
+
1
)
一
定
能
使
得
log
p
(
x
∣
θ
(
t
+
1
)
)
≥
l
o
g
p
(
x
∣
θ
(
t
)
)
\color{blue}使ELBO取极大值的\theta ^{(t+1)}一定能使得\log\; p(x|\theta ^{(t+1)})\geq log\; p(x|\theta ^{(t)})
使ELBO取极大值的θ(t+1)一定能使得logp(x∣θ(t+1))≥logp(x∣θ(t))。该过程如下图所示:

通过上图,观察ELBO取极大值的过程:
θ ( t + 1 ) = a r g m a x θ E L B O = a r g m a x θ ∫ z p ( z ∣ x , θ ( t ) ) l o g p ( x , z ∣ θ ) p ( z ∣ x , θ ( t ) ) d z = a r g m a x θ ∫ z p ( z ∣ x , θ ( t ) ) l o g p ( x , z ∣ θ ) d z − a r g m a x θ ∫ z p ( z ∣ x , θ ( t ) ) p ( z ∣ x , θ ( t ) ) d z ⏟ 与 θ 无 关 = a r g m a x θ ∫ z p ( z ∣ x , θ ( t ) ) l o g p ( x , z ∣ θ ) d z = a r g m a x θ E z ∣ x , θ ( t ) [ l o g p ( x , z ∣ θ ) ] (10.2.8) \begin{array}{ll}\theta ^{(t+1)}&=\underset{\theta }{argmax}ELBO =\underset{\theta }{argmax}\int _{z}p(z|x,\theta ^{(t)})log\; \frac{p(x,z|\theta )}{p(z|x,\theta ^{(t)})}\mathrm{d}z\\ &=\underset{\theta }{argmax}\int _{z}p(z|x,\theta ^{(t)})log\; p(x,z|\theta )\mathrm{d}z-\underset{与\theta 无关}{\underbrace{\underset{\theta }{argmax}\int _{z}p(z|x,\theta ^{(t)})p(z|x,\theta ^{(t)})\mathrm{d}z}}\\ &={\color{Red}{\underset{\theta }{argmax}\int _{z}p(z|x,\theta ^{(t)})log\; p(x,z|\theta )\mathrm{d}z}} \\ &={\color{Red}{\underset{\theta }{argmax}E_{z|x,\theta ^{(t)}}[log\; p(x,z|\theta )]}}\end{array}\tag{10.2.8} θ(t+1)=θargmaxELBO=θargmax∫zp(z∣x,θ(t))logp(z∣x,θ(t))p(x,z∣θ)dz=θargmax∫zp(z∣x,θ(t))logp(x,z∣θ)dz−与θ无关 θargmax∫zp(z∣x,θ(t))p(z∣x,θ(t))dz=θargmax∫zp(z∣x,θ(t))logp(x,z∣θ)dz=θargmaxEz∣x,θ(t)[logp(x,z∣θ)](10.2.8)
其中 θ ( t ) 在 每 次 arg max θ 的 时 候 是 常 量 \color{blue}\theta^{(t)}在每次\arg\underset{\theta}{\max}的时候是常量 θ(t)在每次argθmax的时候是常量, θ 才 是 变 量 \color{blue}\theta才是变量 θ才是变量。因此: E M 算 法 的 一 个 想 法 是 让 E L B O 不 断 的 增 加 , 使 log P ( X ∣ θ ) 不 断 变 大 {\color{red} EM算法的一个想法是让ELBO不断的增加,使\log P(X|\theta)不断变大} EM算法的一个想法是让ELBO不断的增加,使logP(X∣θ)不断变大的一种攀爬的迭代方法。
10.3 从ELBO+Jensen不等式的角度推导EM算法
- Jensen不等式
对于一个凹函数 f ( x ) f(x) f(x),对于 t ∈ [ 0 , 1 ] t\in [0,1] t∈[0,1],存在 c = t a + ( 1 − t ) b , ϕ = t f ( a ) + ( 1 − t ) f ( b ) c=ta+(1-t)b,\;\phi =tf(a)+(1-t)f(b) c=ta+(1−t)b,ϕ=tf(a)+(1−t)f(b)。凹函数恒有 f ( c ) ≥ ϕ f(c)\geq \phi f(c)≥ϕ, 也就是: f ( t a + ( 1 − t ) b ) ≥ t f ( a ) + ( 1 − t ) f ( b ) . (10.3.1) \color{blue}f(ta+(1-t)b)\geq tf(a)+(1-t)f(b).\tag{10.3.1} f(ta+(1−t)b)≥tf(a)+(1−t)f(b).(10.3.1)

如上图,当 t = 1 2 t=\frac{1}{2} t=21时有 f ( a 2 + b 2 ) ≥ f ( a ) 2 + f ( b ) 2 f(\frac{a}{2}+\frac{b}{2})\geq \frac{f(a)}{2}+\frac{f(b)}{2} f(2a+2b)≥2f(a)+2f(b)。 可以理解为:
先 求 期 望 再 求 函 数 恒 ≥ ‾ 先 求 函 数 再 求 期 望 \color{red}先求期望再求函数\underline{恒\geq} 先求函数再求期望 先求期望再求函数恒≥先求函数再求期望
即函数值的期望大于等于期望的函数值:
E [ f ( x ) ] ≤ f ( E [ x ] ) (10.3.2) \color{red}E[f(x)] \le f(E[x])\tag{10.3.2} E[f(x)]≤f(E[x])(10.3.2) -
应
用
J
e
n
s
e
n
不
等
式
导
出
E
M
算
法
\color{blue}应用Jensen不等式导出EM算法
应用Jensen不等式导出EM算法
-
E
(
E
x
p
e
c
t
a
t
i
o
n
)
−
s
t
e
p
:
log
p
(
x
∣
θ
(
t
)
)
=
E
L
B
O
\color{blue}E(Expectation)-step: \log\; p(x|\theta ^{(t)})=ELBO
E(Expectation)−step:logp(x∣θ(t))=ELBO:
l o g p ( x ∣ θ ) = l o g ∫ z p ( x , z ∣ θ ) d z = l o g ∫ z p ( x , z ∣ θ ) q ( z ) ⋅ q ( z ) d z = l o g E q ( z ) [ p ( x , z ∣ θ ) q ( z ) ] ≥ E q ( z ) [ l o g p ( x , z ∣ θ ) q ( z ) ] ⏟ E L B O (10.3.3) \begin{aligned}log\; p(x|\theta) &=log\int _{z}p(x,z|\theta )\mathrm{d}z =log\int _{z}\frac{p(x,z|\theta )}{q(z)}\cdot q(z)\mathrm{d}z\\ &=log\; E_{q(z)}[\frac{p(x,z|\theta )}{q(z)}] \geq \underset{ELBO}{\underbrace{E_{q(z)}[log\frac{p(x,z|\theta )}{q(z)}]}}\end{aligned}\tag{10.3.3} logp(x∣θ)=log∫zp(x,z∣θ)dz=log∫zq(z)p(x,z∣θ)⋅q(z)dz=logEq(z)[q(z)p(x,z∣θ)]≥ELBO Eq(z)[logq(z)p(x,z∣θ)](10.3.3)
根据 J e n s e n I n e q u a l i t y \color{red}Jensen\;Inequality JensenInequality的定义,当 P ( x , z ∣ θ ) q ( z ) = C \color{red}\frac{P(x,z|\theta)}{q(z)} = C q(z)P(x,z∣θ)=C时可以取得等号。此处的 E z ∼ q ( z ) [ log P ( x , z ∣ θ ) q ( z ) ] \mathbb{E}_{z\sim q(z)}\left[ \log \frac{P(x,z|\theta)}{q(z)} \right] Ez∼q(z)[logq(z)P(x,z∣θ)]是 ∫ z q ( z ) log P ( x , z ∣ θ ) q ( z ) d z \int_z q(z) \log \frac{P(x,z|\theta)}{q(z)}dz ∫zq(z)logq(z)P(x,z∣θ)dz,也就是之前在KL Divergence角度进行分析时得到的ELBO(公式(10.2.6))。
-
M
(
M
a
x
i
m
i
z
a
t
i
o
n
)
−
s
t
e
p
:
E
L
B
O
与
log
p
(
x
∣
θ
)
\color{blue}M(Maximization)-step:ELBO与\log\; p(x|\theta )
M(Maximization)−step:ELBO与logp(x∣θ)
当取等时,可以达到最大,即:
p ( x , z ∣ θ ) q ( z ) = C ⇒ q ( z ) = p ( x , z ∣ θ ) C ⇒ ∫ z q ( z ) d z = ∫ z 1 C p ( x , z ∣ θ ) d z ⇒ 1 = 1 C ∫ z p ( x , z ∣ θ ) d z ⇒ C = p ( x ∣ θ ) . (10.3.4) \begin{aligned}&\frac{p(x,z|\theta )}{q(z)}=C\\ \Rightarrow& q(z)=\frac{p(x,z|\theta )}{C}\\ \Rightarrow& \int _{z}q(z)\mathrm{d}z=\int _{z}\frac{1}{C}p(x,z|\theta )\mathrm{d}z\\ \Rightarrow& 1=\frac{1}{C}\int _{z}p(x,z|\theta )\mathrm{d}z\\ \Rightarrow& C=p(x|\theta )\end{aligned}.\tag{10.3.4} ⇒⇒⇒⇒q(z)p(x,z∣θ)=Cq(z)=Cp(x,z∣θ)∫zq(z)dz=∫zC1p(x,z∣θ)dz1=C1∫zp(x,z∣θ)dzC=p(x∣θ).(10.3.4)
将 C C C代入 q ( z ) = p ( x , z ∣ θ ) C q(z)=\frac{p(x,z|\theta )}{C} q(z)=Cp(x,z∣θ)得:
q ( z ) = p ( x , z ∣ θ ) p ( x ∣ θ ) = p ( z ∣ x , θ ) . (10.3.5) {\color{Red}{q(z)=\frac{p(x,z|\theta )}{p(x|\theta )}=p(z|x,\theta )}}.\tag{10.3.5} q(z)=p(x∣θ)p(x,z∣θ)=p(z∣x,θ).(10.3.5)
q ( z ) q(z) q(z)就是后验概率,当 q ( z ) = p ( z ∣ x ∣ θ ) \color{red}q(z)=p(z|x|\theta ) q(z)=p(z∣x∣θ)时取等号时:
l o g p ( x ∣ θ ) = E q ( z ) [ l o g p ( x , z ∣ θ ) q ( z ) ] ⏟ E L B O . (10.3.6) log\; p(x|\theta )= \underset{ELBO}{\underbrace{E_{q(z)}[log\frac{p(x,z|\theta )}{q(z)}] }}.\tag{10.3.6} logp(x∣θ)=ELBO Eq(z)[logq(z)p(x,z∣θ)].(10.3.6)
因此在迭代更新过程中取 q ( z ) = p ( z ∣ x , θ t ) q(z)=p(z|x,\theta ^{t}) q(z)=p(z∣x,θt)。接下来的推导如公式(10.2.7)和公式(10.2.8),最终得到:
θ ( t + 1 ) = a r g max θ ∫ z log P ( x , z ∣ θ ) ⋅ P ( z ∣ x , θ ( t ) ) d z . (10.3.7) \color{red}\theta^{(t+1)}=arg\underset{\theta}{\max} \int_z \log P(x,z|\theta)\cdot P(z|x,\theta^{(t)})dz.\tag{10.3.7} θ(t+1)=argθmax∫zlogP(x,z∣θ)⋅P(z∣x,θ(t))dz.(10.3.7)
-
E
(
E
x
p
e
c
t
a
t
i
o
n
)
−
s
t
e
p
:
log
p
(
x
∣
θ
(
t
)
)
=
E
L
B
O
\color{blue}E(Expectation)-step: \log\; p(x|\theta ^{(t)})=ELBO
E(Expectation)−step:logp(x∣θ(t))=ELBO:
总结
最后梳理一下EM算法的实现思想。我们的目标是使 P ( X ∣ θ ) P(X|\theta) P(X∣θ)似然函数值最大。但是,直接优化非常的难。所以需要优化下降的方法。对于,每一个 θ ( t ) \theta^{(t)} θ(t)时,计算得到下界为: E Z ∼ Q ( Z ) [ log P ( X , Z ∣ θ ) P ( Z ∣ X , θ ( t ) ) ] \mathbb{E}_{Z\sim Q(Z)}\left[ \log \frac{P(X,Z|\theta)}{P(Z|X,\theta^{(t)})} \right] EZ∼Q(Z)[logP(Z∣X,θ(t))P(X,Z∣θ)],令这个值最大就得到了想要求得的 θ ( t + 1 ) \theta^{(t+1)} θ(t+1)。然后,按这个思路,不断的进行迭代。
EM算法的步骤
EM算法可以被我们分解成E-step和M-step两个部分。
- 输 入 \color{blue}输入 输入:
观察到的数据 x = ( x 1 , x 2 , . . . x n ) x=(x_{1},x_{2},...x_{n}) x=(x1,x2,...xn),联合分布函数 p ( x , z ; θ ) p(x,z;\theta) p(x,z;θ),条件分布 p ( z ∣ x , θ ) p(z|x,\theta) p(z∣x,θ),最大迭代次数J。- 算 法 步 骤 \color{blue}算法步骤 算法步骤:
- 随机初始化模型参数 θ \theta θ的初值 θ 0 \theta_0 θ0。
- j = 1 , 2 , . . . , J j=1,2,...,J j=1,2,...,J 开始EM算法迭代。
- E(Expectation)-step( P ( z ∣ x , θ ( t ) ) ⟶ E z ∼ P ( z ∣ x , θ ( t ) ) [ log P ( x , z ∣ θ ) ] \color{red}P(z|x,\theta^{(t)}) \longrightarrow \mathbb{E}_{z\sim P(z|x,\theta^{(t)})}\left[ \log P(x,z|\theta) \right] P(z∣x,θ(t))⟶Ez∼P(z∣x,θ(t))[logP(x,z∣θ)])
计算联合分布的条件概率期望:
- q i ( z i ) = p ( z i ∣ x i , θ j ) q_{i}(z_{i})=p(z_{i}|x_{i},\theta_{j}) qi(zi)=p(zi∣xi,θj)
- E L B O ( θ , θ j ) = E z ∼ P ( z ∣ x , θ ( t ) ) [ log P ( x , z ∣ θ ) ] = ∑ i = 1 n ∑ z i q i ( z i ) l o g p ( x i , z i ; θ ) q i ( z i ) ELBO(\theta,\theta_{j})=\mathbb{E}_{z\sim P(z|x,\theta^{(t)})}\left[ \log P(x,z|\theta) \right]= \sum_{i=1}^{n}{\sum_{z_{i}}^{}{q_{i}(z_{i})log\frac{p(x_{i},z_{i};\theta)}{q_{i}(z_{i})}}} ELBO(θ,θj)=Ez∼P(z∣x,θ(t))[logP(x,z∣θ)]=∑i=1n∑ziqi(zi)logqi(zi)p(xi,zi;θ)
- M(Maximization)-step: θ ( t + 1 ) = arg max θ E z ∼ P ( z ∣ x , θ ( t ) ) [ log P ( x , z ∣ θ ) ] \color{red}\theta^{(t+1)} = \arg\underset{\theta}{\max} \mathbb{E}_{z\sim P(z|x,\theta^{(t)})}\left[ \log P(x,z|\theta) \right] θ(t+1)=argθmaxEz∼P(z∣x,θ(t))[logP(x,z∣θ)]
极大化ELBO,得到 θ j + 1 \theta_{j+1} θj+1:
- θ ( t + 1 ) = arg max θ E z ∼ P ( z ∣ x , θ ( t ) ) [ log P ( x , z ∣ θ ) ] \theta^{(t+1)} = \arg\underset{\theta}{\max} \mathbb{E}_{z\sim P(z|x,\theta^{(t)})}\left[ \log P(x,z|\theta) \right] θ(t+1)=argθmaxEz∼P(z∣x,θ(t))[logP(x,z∣θ)]
- 如果 θ j + 1 \theta_{j+1} θj+1已经收敛,则算法结束。否则继续进行E步和M步进行迭代。
- 输 出 \color{blue}输出 输出: 模型参数 θ \theta θ。

10.4 EM算法的收敛性
EM算法的求解过程是 θ ( t ) ⟶ θ ( t + 1 ) \theta^{(t)} \longrightarrow \theta^{(t+1)} θ(t)⟶θ(t+1),因此迭代是: log P ( x ∣ θ ( t ) ) → log P ( x ∣ θ ( t + 1 ) ) \log P(x|\theta^{(t)})\to \log P(x|\theta^{(t+1)}) logP(x∣θ(t))→logP(x∣θ(t+1)),若要收敛,则需要证明 P ( x ∣ θ ( t ) ) ≤ P ( x ∣ θ ( t + 1 ) ) \color{red}P(x|\theta ^{(t)})\leq P(x|\theta ^{(t+1)}) P(x∣θ(t))≤P(x∣θ(t+1))。证明如下:
-
引 出 不 等 式 \color{blue}引出不等式 引出不等式
对 P ( x ∣ θ ) P(x|\theta) P(x∣θ)加入隐变量,,利用全概率公式( P ( A , B ) = P ( B ∣ A ) P ( A ) P(A,B)=P(B|A)P(A) P(A,B)=P(B∣A)P(A))可以写成:
log P ( x ∣ θ ) = log P ( x , z ∣ θ ) P ( z ∣ x , θ ) = log P ( x , z ∣ θ ) − log P ( z ∣ x , θ ) . (10.1.4) \log P(x|\theta)=\log {P(x,z|\theta)\over P(z|x,\theta)}=\log P(x,z|\theta)-\log P(z|x,\theta).\tag{10.1.4} logP(x∣θ)=logP(z∣x,θ)P(x,z∣θ)=logP(x,z∣θ)−logP(z∣x,θ).(10.1.4)
接下来在公式两边同时求关于 P ( z ∣ x , θ ( t ) ) \color{blue}P(z|x,\theta^{(t)}) P(z∣x,θ(t))的期望:- 左边
左 边 = ∫ z P ( z ∣ x , θ ( t ) ) ⋅ log P ( x ∣ θ ) d z = log P ( x ∣ θ ) ∫ z P ( z ∣ x , θ ( t ) ) d z = log P ( x ∣ θ ) . (10.1.5) \begin{array}{ll} 左边& = \int_z P(z|x,\theta^{(t)})\cdot \log P(x|\theta)dz\\ & = \log P(x|\theta)\int_z P(z|x,\theta^{(t)})dz\\ & = \log P(x|\theta).\tag{10.1.5} \end{array} 左边=∫zP(z∣x,θ(t))⋅logP(x∣θ)dz=logP(x∣θ)∫zP(z∣x,θ(t))dz=logP(x∣θ).(10.1.5) - 右边
右 边 = ∫ z P ( z ∣ x , θ ( t ) ) ⋅ log P ( x , z ∣ θ ) d z ⏟ Q ( θ , θ ( t ) ) − ∫ z P ( z ∣ x , θ ( t ) ) ⋅ log P ( z ∣ x , θ ) d z ⏟ H ( θ , θ ( t ) ) . (10.1.6) \begin{array}{l}右边&=\underbrace{\int_z P(z|x,\theta^{(t)})\cdot \log P(x,z|\theta)dz}_{Q(\theta,\theta^{(t)})}-\underbrace{\int_z P(z|x,\theta^{(t)})\cdot \log P(z|x,\theta)dz}_{H(\theta,\theta^{(t)})}\\\end{array}.\tag{10.1.6} 右边=Q(θ,θ(t)) ∫zP(z∣x,θ(t))⋅logP(x,z∣θ)dz−H(θ,θ(t)) ∫zP(z∣x,θ(t))⋅logP(z∣x,θ)dz.(10.1.6)
因此证明 log P ( x ∣ θ ( t ) ) ≤ log P ( x ∣ θ ( t + 1 ) ) \log P(x|\theta^{(t)}) \le \log P(x|\theta^{(t+1)}) logP(x∣θ(t))≤logP(x∣θ(t+1)):
l o g P ( x ∣ θ ( t ) ) − l o g P ( x ∣ θ ( t + 1 ) ) = [ Q ( θ ( t ) , θ ( t ) ) − Q ( θ ( t + 1 ) , θ ( t ) ) ] − [ H ( θ ( t ) , θ ( t ) ) − H ( θ ( t + 1 ) , θ ( t ) ) ] ≤ 0 log\; P(x|\theta ^{(t)})-log\; P(x|\theta ^{(t+1)})=[Q(\theta ^{(t)},\theta ^{(t)})-Q(\theta ^{(t+1)},\theta ^{(t)})]-[H(\theta ^{(t)},\theta ^{(t)})-H(\theta ^{(t+1)},\theta ^{(t)})]\le0 logP(x∣θ(t))−logP(x∣θ(t+1))=[Q(θ(t),θ(t))−Q(θ(t+1),θ(t))]−[H(θ(t),θ(t))−H(θ(t+1),θ(t))]≤0
相当于证明:
Q ( θ ( t ) , θ ( t ) ) − H ( θ ( t ) , θ ( t ) ) ≤ Q ( θ ( t + 1 ) , θ ( t ) ) − H ( θ ( t + 1 ) , θ ( t ) ) . (10.1.7) \color{red}Q(\theta^{(t)},\theta^{(t)})-H(\theta^{(t)},\theta^{(t)}) \le Q(\theta^{(t+1)},\theta^{(t)})-H(\theta^{(t+1)},\theta^{(t)}).\tag{10.1.7} Q(θ(t),θ(t))−H(θ(t),θ(t))≤Q(θ(t+1),θ(t))−H(θ(t+1),θ(t)).(10.1.7)
- 左边
-
证 明 Q ( θ ( t + 1 ) , θ ( t ) ) ≥ Q ( θ ( t ) , θ ( t ) ) \color{blue}证明Q(\theta^{(t+1)},\theta^{(t)}) \ge Q(\theta^{(t)},\theta^{(t)}) 证明Q(θ(t+1),θ(t))≥Q(θ(t),θ(t))
写出 Q ( θ ( t ) , θ ( t ) ) Q(\theta^{(t)},\theta^{(t)}) Q(θ(t),θ(t))和 Q ( θ ( t + 1 ) , θ ( t ) ) Q(\theta^{(t+1)},\theta^{(t)}) Q(θ(t+1),θ(t))的形式:
Q ( θ ( t ) , θ ( t ) ) = ∫ z P ( z ∣ x , θ ( t ) ) ⋅ log P ( x , z ∣ θ ( t ) ) d z Q ( θ ( t + 1 ) , θ ( t ) ) = ∫ z P ( z ∣ x , θ ( t ) ) ⋅ log P ( x , z ∣ θ ( t + 1 ) ) d z . (10.1.8) Q(\theta^{(t)},\theta^{(t)})=\int_z P(z|x,\theta^{(t)})\cdot \log P(x,z|\theta^{(t)})dz\\ Q(\theta^{(t+1)},\theta^{(t)})=\int_z P(z|x,\theta^{(t)})\cdot \log P(x,z|\theta^{(t+1)})dz.\tag{10.1.8} Q(θ(t),θ(t))=∫zP(z∣x,θ(t))⋅logP(x,z∣θ(t))dzQ(θ(t+1),θ(t))=∫zP(z∣x,θ(t))⋅logP(x,z∣θ(t+1))dz.(10.1.8)
根据EM算法的定义:
θ ( t + 1 ) = a r g max θ ∫ z log P ( x , z ∣ θ ) ⋅ P ( z ∣ x , θ ( t ) ) d z \color{red}\theta^{(t+1)}=arg\underset{\theta}{\max} \int_z \log P(x,z|\theta)\cdot P(z|x,\theta^{(t)})dz θ(t+1)=argθmax∫zlogP(x,z∣θ)⋅P(z∣x,θ(t))dz
所以很明显:
Q ( θ ( t + 1 ) , θ ( t ) ) ≥ Q ( θ ( t ) , θ ( t ) ) . (10.1.9) \color{blue}Q(\theta^{(t+1)},\theta^{(t)}) \ge Q(\theta^{(t)},\theta^{(t)}).\tag{10.1.9} Q(θ(t+1),θ(t))≥Q(θ(t),θ(t)).(10.1.9) -
证 明 H ( θ ( t + 1 ) , θ ( t ) ) ≤ H ( θ ( t ) , θ ( t ) ) \color{blue}证明H(\theta^{(t+1)},\theta^{(t)}) \le H(\theta^{(t)},\theta^{(t)}) 证明H(θ(t+1),θ(t))≤H(θ(t),θ(t))
根据 Q Q Q 的结论,接下来需要证明 H ( θ ( t + 1 ) , θ ( t ) ) ≤ H ( θ ( t ) , θ ( t ) ) H(\theta^{(t+1)},\theta^{(t)}) \le H(\theta^{(t)},\theta^{(t)}) H(θ(t+1),θ(t))≤H(θ(t),θ(t))
H ( θ ( t + 1 ) , θ ( t ) ) − H ( θ ( t ) , θ ( t ) ) = ∫ z P ( z ∣ x , θ ( t ) ) ⋅ log P ( z ∣ x , θ ( t + 1 ) ) d z − ∫ z P ( z ∣ x , θ ( t ) ) ⋅ log P ( z ∣ x , θ ( t ) ) d z = ∫ z P ( z ∣ x , θ ( t ) ) ⋅ [ log P ( z ∣ x , θ ( t + 1 ) ) − log P ( z ∣ x , θ ( t ) ) ] d z = ∫ z P ( z ∣ x , θ ( t ) ) ⋅ log P ( z ∣ x , θ ( t + 1 ) ) P ( z ∣ x , θ ( t ) ) d z \begin{array}{ll} &\ \ \ \ \ H(\theta^{(t+1)},\theta^{(t)}) - H(\theta^{(t)},\theta^{(t)})\\ &=\int_z P(z|x,\theta^{(t)})\cdot \log P(z|x,\theta^{(t+1)})dz-\int_z P(z|x,\theta^{(t)})\cdot \log P(z|x,\theta^{(t)})dz\\ &=\int_z P(z|x,\theta^{(t)})\cdot [\log P(z|x,\theta^{(t+1)})-\log P(z|x,\theta^{(t)})]dz\\ &=\int_z P(z|x,\theta^{(t)})\cdot \log {P(z|x,\theta^{(t+1)})\over P(z|x,\theta^{(t)})}dz\\ \end{array} H(θ(t+1),θ(t))−H(θ(t),θ(t))=∫zP(z∣x,θ(t))⋅logP(z∣x,θ(t+1))dz−∫zP(z∣x,θ(t))⋅logP(z∣x,θ(t))dz=∫zP(z∣x,θ(t))⋅[logP(z∣x,θ(t+1))−logP(z∣x,θ(t))]dz=∫zP(z∣x,θ(t))⋅logP(z∣x,θ(t))P(z∣x,θ(t+1))dz-
利
用
K
L
D
i
v
e
r
g
e
n
c
e
来
证
明
\color{blue}利用KL\;Divergence来证明
利用KLDivergence来证明:
K L D i v e r g e n c e \color{blue}KL\;Divergence KLDivergence的定义:两个概率分布 P ( x ) P(x) P(x)和 Q ( x ) Q(x) Q(x)的 K L 散 度 KL散度 KL散度的定义为 D K L ( P ∣ ∣ Q ) = E x ∼ P [ l o g P ( x ) Q ( x ) ] . (10.1.10) D_{KL}(P||Q)=E_{x\sim P}[log\frac{P(x)}{Q(x)}].\tag{10.1.10} DKL(P∣∣Q)=Ex∼P[logQ(x)P(x)].(10.1.10)
因为KL散度是恒 ≥ 0 \geq 0 ≥0的,则:
∫ z P ( z ∣ x , θ ( t ) ) ⋅ log P ( z ∣ x , θ ( t + 1 ) ) P ( z ∣ x , θ ( t ) ) d z = − K L ( P ( z ∣ x , θ ( t ) ) ∥ P ( z ∣ x , θ ( t + 1 ) ) ) < 0 (10.1.11) \int_z P(z|x,\theta^{(t)})\cdot \log {P(z|x,\theta^{(t+1)})\over P(z|x,\theta^{(t)})}dz= -KL(P(z|x,\theta^{(t)}) \Vert P(z|x,\theta^{(t+1)})) < 0\tag{10.1.11} ∫zP(z∣x,θ(t))⋅logP(z∣x,θ(t))P(z∣x,θ(t+1))dz=−KL(P(z∣x,θ(t))∥P(z∣x,θ(t+1)))<0(10.1.11)
所以 H ( θ ( t + 1 ) , θ ( t ) ) ≤ H ( θ ( t ) , θ ( t ) ) \color{blue}H(\theta^{(t+1)},\theta^{(t)}) \le H(\theta^{(t)},\theta^{(t)}) H(θ(t+1),θ(t))≤H(θ(t),θ(t))。 -
利
用
J
e
n
s
e
n
不
等
式
来
证
明
\color{blue}利用Jensen 不等式来证明
利用Jensen不等式来证明:
J e n s e n 不 等 式 \color{blue}Jensen 不等式 Jensen不等式的定义:若 f ( x ) f(x) f(x)是convex function(凸函数) 则
E [ f ( x ) ] ≥ f ( E [ x ] ) . (10.1.12) \color{red}E[f(x)] \ge f(E[x]).\tag{10.1.12} E[f(x)]≥f(E[x]).(10.1.12)
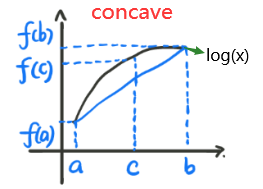
由于 l o g ( x ) log(x) log(x)为concave function(凹函数),则
E [ log x ] ≤ log E [ x ] . (10.1.13) \color{red}E[\log x] \le \log E[x].\tag{10.1.13} E[logx]≤logE[x].(10.1.13)
因此:
H ( θ ( t + 1 ) , θ ( t ) ) − H ( θ ( t ) , θ ( t ) ) = ∫ z P ( z ∣ x , θ ( t ) ) ⋅ log P ( z ∣ x , θ ( t + 1 ) ) P ( z ∣ x , θ ( t ) ) d z ≤ log ∫ z P ( z ∣ x , θ ( t ) ) ⋅ P ( z ∣ x , θ ( t + 1 ) ) P ( z ∣ x , θ ( t ) ) d z = log ∫ z P ( z ∣ x , θ ( t + 1 ) ) d z = log 1 = 0 \begin{array}{ll}&\ \ \ \ \ H(\theta^{(t+1)},\theta^{(t)}) - H(\theta^{(t)},\theta^{(t)})\\ &=\int_z P(z|x,\theta^{(t)})\cdot \log {P(z|x,\theta^{(t+1)})\over P(z|x,\theta^{(t)})}dz\\ &\le \log \int_z P(z|x,\theta^{(t)})\cdot {P(z|x,\theta^{(t+1)})\over P(z|x,\theta^{(t)})}dz\\ &=\log \int_z P(z|x,\theta^{(t+1)})dz\\ &=\log 1 =0 \end{array} H(θ(t+1),θ(t))−H(θ(t),θ(t))=∫zP(z∣x,θ(t))⋅logP(z∣x,θ(t))P(z∣x,θ(t+1))dz≤log∫zP(z∣x,θ(t))⋅P(z∣x,θ(t))P(z∣x,θ(t+1))dz=log∫zP(z∣x,θ(t+1))dz=log1=0
所以 H ( θ ( t + 1 ) , θ ( t ) ) ≤ H ( θ ( t ) , θ ( t ) ) \color{blue}H(\theta^{(t+1)},\theta^{(t)}) \le H(\theta^{(t)},\theta^{(t)}) H(θ(t+1),θ(t))≤H(θ(t),θ(t))。
由 K L D i v e r g e n c e \color{red}KL\;Divergence KLDivergence和 J e n s e n 不 等 式 \color{red}Jensen 不等式 Jensen不等式可知:
H ( θ ( t + 1 ) , θ ( t ) ) − H ( θ ( t ) , θ ( t ) ) ≤ 0. (10.1.14) \color{blue}H(\theta^{(t+1)},\theta^{(t)}) - H(\theta^{(t)},\theta^{(t)}) \le0.\tag{10.1.14} H(θ(t+1),θ(t))−H(θ(t),θ(t))≤0.(10.1.14)根据公式(10.1.9)和公式(10.1.14)可得:
Q ( θ ( t ) , θ ( t ) ) − H ( θ ( t ) , θ ( t ) ) ≤ Q ( θ ( t + 1 ) , θ ( t ) ) − H ( θ ( t + 1 ) , θ ( t ) ) (10.1.7) Q(\theta^{(t)},\theta^{(t)})-H(\theta^{(t)},\theta^{(t)}) \le Q(\theta^{(t+1)},\theta^{(t)})-H(\theta^{(t+1)},\theta^{(t)})\tag{10.1.7} Q(θ(t),θ(t))−H(θ(t),θ(t))≤Q(θ(t+1),θ(t))−H(θ(t+1),θ(t))(10.1.7)
则EM算法的收敛性:
log P ( x ∣ θ ( t ) ) ≤ log P ( x ∣ θ ( t + 1 ) ) . (10.1.15) \color{red}\log P(x|\theta^{(t)}) \le \log P(x|\theta^{(t+1)}).\tag{10.1.15} logP(x∣θ(t))≤logP(x∣θ(t+1)).(10.1.15)
证毕。 -
利
用
K
L
D
i
v
e
r
g
e
n
c
e
来
证
明
\color{blue}利用KL\;Divergence来证明
利用KLDivergence来证明:
-
其他定理
另外还有其他定理保证了EM的算法收敛性。首先对于 θ ( i ) ( i = 1 , 2 , ⋯ ) \theta ^{(i)}(i=1,2,\cdots ) θ(i)(i=1,2,⋯)序列和其对应的对数似然序列 L ( θ ( t ) ) = l o g p ( x ∣ θ ( t ) ) ( t = 1 , 2 , ⋯ ) L(\theta ^{(t)})=log\; p(x|\theta ^{(t)})(t=1,2,\cdots ) L(θ(t))=logp(x∣θ(t))(t=1,2,⋯)有如下定理:- 如果 p ( x ∣ θ ) \color{blue}p(x|\theta ) p(x∣θ)有上界,则 L ( θ ( t ) ) = l o g p ( x ∣ θ ( t ) ) L(\theta ^{(t)})=log\; p(x|\theta ^{(t)}) L(θ(t))=logp(x∣θ(t))收敛到某一值 L ∗ L^* L∗;
- 在函数 Q ( θ , θ ′ ) Q(\theta,\theta^{'}) Q(θ,θ′)与 L ( θ ) L(\theta ) L(θ)满足一定条件下,由EM算法得到的参数估计序列 θ ( t ) \theta ^{(t)} θ(t)的收敛值 θ ∗ \theta ^{*} θ∗是 L ( θ ) L(\theta ) L(θ)的稳定点。
10.5 再回首
接下来的内容是:
- 从狭义的EM推广到广义的EM
- 证明狭义EM是EM的一个特例
- 介绍真正的EM
本节主要介绍EM算法的由来。
- E M 是 一 种 算 法 , 不 是 模 型 \color{red}EM是一种算法,不是模型 EM是一种算法,不是模型,有点像梯度下降(GD)。
-
E
M
主
要
是
为
了
解
决
生
成
模
型
,
并
且
是
概
率
生
成
模
型
\color{red}EM主要是为了解决生成模型,并且是概率生成模型
EM主要是为了解决生成模型,并且是概率生成模型。
-
假设有以下数据:
- X X X:Observed Variable ⟶ \longrightarrow ⟶ X = { x i } i = 1 N X=\{ x_i \}_{i=1}^N X={xi}i=1N;
- Z Z Z:Latent Variable ⟶ \longrightarrow ⟶ Z = { Z i } i = 1 N Z=\{ Z_i \}_{i=1}^N Z={Zi}i=1N;
- ( X , Z ) (X,Z) (X,Z):Complete Model;
- θ \theta θ:Model Parameter。
EM算法的目标是得到一个参数 θ ^ \hat{\theta} θ^,来推导出 X X X,也就是 P ( X ∣ θ ) P(X|\theta) P(X∣θ)。实际上是假设使用MLE:
θ ^ = arg max θ P ( X ∣ θ ) = arg max θ ∏ i = 1 N P ( x i ∣ θ ) = arg max θ ∑ i = 1 N log P ( x i ∣ θ ) (10.4.1) \begin{array}{ll} \hat{\theta} &= \arg\max_{\theta} P(X|\theta) \\ & = \arg\max_{\theta} \prod_{i=1}^N P(x_i|\theta) \\ & = \arg\max_{\theta} \sum_{i=1}^N \log P(x_i|\theta) \end{array}\tag{10.4.1} θ^=argmaxθP(X∣θ)=argmaxθ∏i=1NP(xi∣θ)=argmaxθ∑i=1NlogP(xi∣θ)(10.4.1) -
实际观察的输入空间 X \mathcal{X} X分布 P ( X ) P(X) P(X)是非常复杂。可能什么规律都找不出来,这时引入了一个隐变量 Z Z Z,这个变量中包含了已有的一些归纳总结,引入了内部结构。假设存在一个隐变量 z z z能够生成 x x x。即:
P ( x ) = ∫ z P ( x , z ) d z . (10.4.2) P(x)=\int_z P(x,z)dz.\tag{10.4.2} P(x)=∫zP(x,z)dz.(10.4.2)
-
10.6 广义EM
- EM算法是为了解决参数估计问题,也就是learning问题:
θ ^ = arg max θ P ( x ∣ θ ) . (10.5.1) \hat{\theta} = \arg\max_{\theta} P(x|\theta).\tag{10.5.1} θ^=argθmaxP(x∣θ).(10.5.1)
P ( x ∣ θ ) P(x|\theta) P(x∣θ)可能会非常的复杂。在生成模型的思路中,假设一个隐变量 Z Z Z。有了这个生成模型的假设后,就可以引入一些潜在归纳出的结构进去。通过 P ( x ) = P ( x , z ) P ( z ∣ x ) P(x) = \frac{P(x,z)}{P(z|x)} P(x)=P(z∣x)P(x,z),就可以把问题具体化了。
这里说明一下,我们习惯用的表达是 log P ( x ∣ θ ) \log P(x|\theta) logP(x∣θ),但是也有的文献中使用 P ( x ; θ ) P(x;\theta) P(x;θ)或者 P θ ( x ) P_\theta(x) Pθ(x)。这三种表达方式代表的意义是等价的。
-
引出隐变量
把隐变量 q ( z ) ( q ( z ) ≠ 0 ) q(z)(q(z)\ne 0) q(z)(q(z)=0)代入:
l o g p ( x ∣ θ ) = ∫ z q ( z ) l o g p ( x , z ∣ θ ) q ( z ) d z − ∫ z q ( z ) l o g p ( z ∣ x , θ ) q ( z ) d z = E L B O + K L ( q ∣ ∣ p ) . (10.5.1) \color{red}log\; p(x|\theta )=\int _{z}q(z)log\; \frac{p(x,z|\theta )}{q(z)}\mathrm{d}z-\int _{z}q(z)log\; \frac{p(z|x,\theta )}{q(z)}\mathrm{d}z=ELBO+KL(q||p).\tag{10.5.1} logp(x∣θ)=∫zq(z)logq(z)p(x,z∣θ)dz−∫zq(z)logq(z)p(z∣x,θ)dz=ELBO+KL(q∣∣p).(10.5.1)
其中 q = q ( z ) , p = p ( z ∣ x , θ ) \color{blue}q=q(z),p=p(z|x,\theta ) q=q(z),p=p(z∣x,θ):
{ E L B O = L ( q , θ ) = E q ( z ) [ log P ( x , z ∣ θ ) q ( z ) ] K L ( q ∥ p ) = ∫ q ( z ) ⋅ log q ( z ) P ( z ∣ x , θ ) d z . (10.5.2) \begin{cases}\color{blue} ELBO=L(q,\theta)=E_{q(z)}[\log {P(x,z|\theta)\over q(z)} ]\\ \color{blue}KL(q\Vert p)=\int q(z)\cdot \log{q(z)\over P(z|x,\theta)}dz \end{cases}.\tag{10.5.2} {ELBO=L(q,θ)=Eq(z)[logq(z)P(x,z∣θ)]KL(q∥p)=∫q(z)⋅logP(z∣x,θ)q(z)dz.(10.5.2)
因为 K L ≥ 0 KL \ge 0 KL≥0,所以 log P ( x ∣ θ ) ≥ L ( q , θ ) \log P(x|\theta) \ge L(q,\theta) logP(x∣θ)≥L(q,θ);当 q = p q=p q=p时, K L = 0 KL=0 KL=0。 -
求解 p p p和 θ \theta θ
在10.2节中假定 q ( z ) = P ( z ∣ x , θ ) \color{red}q(z)=P(z|x,\theta) q(z)=P(z∣x,θ) ,但实际上 P ( z ∣ x , θ ( t ) ) 是 i n t r a c t a b l e \color{red}P(z|x,\theta^{(t)})是intractable P(z∣x,θ(t))是intractable的,如果生成模型较复杂,则无法求出 P ( z ∣ x , θ ( t ) ) P(z|x,\theta^{(t)}) P(z∣x,θ(t))。因此 q q q无法直接取到 p p p ,需要进行优化,逐渐接近 p p p。- 先固定
θ
\theta
θ
固定的 θ \theta θ, q q q越接近 p p p,则 K L ( q ∣ ∣ p ) KL(q||p) KL(q∣∣p)越小,由于 log P ( x ∣ θ ) \log P(x|\theta) logP(x∣θ)不变,所以 E L B O ELBO ELBO将越大。此时,就要求 q q q的最大值:
q ^ = a r g min q K L ( q ∥ p ) = a r g max q L ( q , θ ) . (10.5.3) \hat q = arg\underset{q}{\min} KL(q\Vert p)=arg\underset{q}{\max} L(q,\theta).\tag{10.5.3} q^=argqminKL(q∥p)=argqmaxL(q,θ).(10.5.3) - 再固定
q
q
q
当 q q q被我们求出来以后,我们就可以将 q q q固定了,再来求解 θ \theta θ:
θ ^ = arg max θ L ( q ^ , θ ) . (10.5.4) \hat{\theta} = \arg\max_{\theta} L(\hat{q},\theta).\tag{10.5.4} θ^=argθmaxL(q^,θ).(10.5.4)
广 义 的 E M 算 法 基 本 思 路 \color{blue}广义的EM算法基本思路 广义的EM算法基本思路:
E − s t e p : q ( t + 1 ) = a r g m a x q L ( q , θ ( t ) ) M − s t e p : θ ( t + 1 ) = a r g m a x q L ( q ( t + 1 ) , θ ) . (10.5.5) \color{red}E-step:q^{(t+1)}=\underset{q}{argmax}\; L(q,\theta^{(t)})\\ M-step:\theta^{(t+1)}=\underset{q}{argmax}\; L(q^{(t+1)},\theta).\tag{10.5.5} E−step:q(t+1)=qargmaxL(q,θ(t))M−step:θ(t+1)=qargmaxL(q(t+1),θ).(10.5.5) - 先固定
θ
\theta
θ
-
注
再次观察一下ELBO:
E L B O = L ( q , θ ) = E q ( z ) [ log P ( x , z ∣ θ ) q ( z ) ] = E q [ log P ( x , z ) − log q ( z ) ] = E q [ log P ( x , z ) ] − E q [ log q ( z ) ] = E q [ log P ( x , z ) ] + H [ q ( z ) ] (10.5.6) \begin{array}{ll} ELBO=L(q,\theta)& = E_{q(z)}[\log {P(x,z|\theta)\over q(z)} ]\\&=E_q[\log P(x,z)-\log q(z)]\\ &=E_q[\log P(x,z)]-E_q[\log q(z)]\\ &=E_q[\log P(x,z)]+H[q(z)] \end{array}\tag{10.5.6} ELBO=L(q,θ)=Eq(z)[logq(z)P(x,z∣θ)]=Eq[logP(x,z)−logq(z)]=Eq[logP(x,z)]−Eq[logq(z)]=Eq[logP(x,z)]+H[q(z)](10.5.6)
θ ( t + 1 ) = a r g max θ E p ( z ∣ x , θ ( t ) ) [ log P ( x , z ∣ θ ) ] (10.5.7) \theta^{(t+1)}=arg\underset{\theta}{\max} E_{p(z|x,\theta^{(t)})}[\log P(x,z|\theta)]\tag{10.5.7} θ(t+1)=argθmaxEp(z∣x,θ(t))[logP(x,z∣θ)](10.5.7)
公式(10.5.7)是之前讲的狭义EM算法的M-step,对比公式(10.5.7)和公式(10.5.6)(广义EM算法的M-Step),会发现ELBO中最后那个 H ( q ( z ) ) H(q(z)) H(q(z))竟然不见了。这是为什么?因为在M-step中, q ( z ) 已 经 是 假 设 固 定 了 , 显 然 H [ q ( z ) ] 就 是 一 个 定 值 \color{blue}q(z)已经是假设固定了,显然H[q(z)]就是一个定值 q(z)已经是假设固定了,显然H[q(z)]就是一个定值,并且与优化目标 θ \theta θ之间并没有关系,所以就被省略掉了。-
广
义
的
E
M
算
法
\color{blue}广义的EM算法
广义的EM算法:
E − s t e p : q ( t + 1 ) = a r g m a x q L ( q , θ ( t ) ) M − s t e p : θ ( t + 1 ) = a r g m a x q L ( q ( t + 1 ) , θ ) (10.5.8) \color{red}\begin{aligned}E-step&:q^{(t+1)}=\underset{q}{argmax}\; L(q,\theta^{(t)})\\ M-step&:\theta^{(t+1)}=\underset{q}{argmax}\; L(q^{(t+1)},\theta)\end{aligned}\tag{10.5.8} E−stepM−step:q(t+1)=qargmaxL(q,θ(t)):θ(t+1)=qargmaxL(q(t+1),θ)(10.5.8) -
狭
义
的
E
M
算
法
\color{blue}狭义的EM算法
狭义的EM算法:
E − s t e p : P ( z ∣ x , θ ( t ) ) ⟶ E z ∼ P ( z ∣ x , θ ( t ) ) [ log P ( x , z ∣ θ ) ] M − s t e p : θ ( t + 1 ) = arg max θ E z ∼ P ( z ∣ x , θ ( t ) ) [ log P ( x , z ∣ θ ) ] (10.5.9) \color{red}\begin{aligned}E-step&:\color{red}P(z|x,\theta^{(t)}) \longrightarrow \mathbb{E}_{z\sim P(z|x,\theta^{(t)})}\left[ \log P(x,z|\theta) \right]\\ M-step&:\theta^{(t+1)} = \arg\underset{\theta}{\max} \mathbb{E}_{z\sim P(z|x,\theta^{(t)})}\left[ \log P(x,z|\theta) \right]\end{aligned}\tag{10.5.9} E−stepM−step:P(z∣x,θ(t))⟶Ez∼P(z∣x,θ(t))[logP(x,z∣θ)]:θ(t+1)=argθmaxEz∼P(z∣x,θ(t))[logP(x,z∣θ)](10.5.9)
两 者 的 差 异 \color{blue}两者的差异 两者的差异:狭义EM算法是广义EM算法的特例——狭义EM算法直接令 q ( z ) = p ( z ∣ x , θ ) q(z)=p(z|x,θ) q(z)=p(z∣x,θ),当然这种情况下 p ( z ∣ x , θ ) p(z|x,θ) p(z∣x,θ)是可求解的,这时只需要求解 θ θ θ。对于广义EM算法, p ( z ∣ x , θ ) p(z|x,θ) p(z∣x,θ)是不可求解的,因此需要求解 θ θ θ和 q ( z ) q(z) q(z),当 q ( z ) q(z) q(z)确定后信息熵 H [ q ( z ) ] H[q(z)] H[q(z)]就随之确定。
-
广
义
的
E
M
算
法
\color{blue}广义的EM算法
广义的EM算法:
10.7 EM的变种
- SMO与GD
上节推广出广义EM算法:
E − s t e p : q ( t + 1 ) = a r g m a x q L ( q , θ ( t ) ) M − s t e p : θ ( t + 1 ) = a r g m a x q L ( q ( t + 1 ) , θ ) . (10.6.1) \color{red}\begin{aligned}E-step&:q^{(t+1)}=\underset{q}{argmax}\; L(q,\theta^{(t)})\\ M-step&:\theta^{(t+1)}=\underset{q}{argmax}\; L(q^{(t+1)},\theta).\end{aligned}\tag{10.6.1} E−stepM−step:q(t+1)=qargmaxL(q,θ(t)):θ(t+1)=qargmaxL(q(t+1),θ).(10.6.1)- 因为 两 步 都 是 m a x \color{red}两步都是max 两步都是max,所以也称为MM算法。
- 这两步方法也是
坐
标
上
升
法
\color{red}坐标上升法
坐标上升法(SMO,固定部分坐标,优化其他坐标,再⼀遍⼀遍的迭代)。
SMO算法采用的也是坐标上升法。
- 梯度下降法(SG)与坐标上升法(SMO).
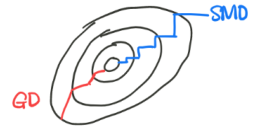
坐标上升法的优化方向基本是恒定不变的,而梯度下降法的优化方向是随着梯度方向而不断发生改变的。
- EM算法的变形
如果在 EM 框架中,⽆法求解 z z z后验概率,那么需要采⽤⼀些变种的 EM 来估算这个后验:- 如果E-Step采用 基 于 平 均 场 的 V I \color{red}基于平均场的VI 基于平均场的VI,则称为VBEM/VEM;
- 采用 蒙 特 卡 洛 采 样 法 \color{red}蒙特卡洛采样法 蒙特卡洛采样法求后验,称为:基于蒙特卡洛的EM(MCEM)。















 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









