







0、参考文献
[1]薛开宇《读书笔记4学习搭建自己的网络MNIST在caffe上进行训练与学习》
[2]悠望南山 http://www.cnblogs.com/NanShan2016/p/5469942.html
http://www.cnblogs.com/NanShan2016/p/5469969.html
1、准备数据库(MNIST手写字体库)
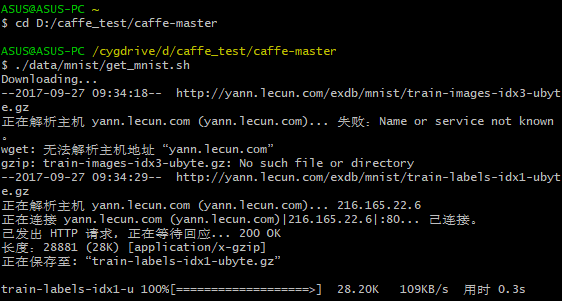
在cygdrive运行以下指令,下载数据库。
1)
$cd CAFFE_ROOT
./data/mnist/get_mnist.sh
结果:
2)
./examples/mnist/create_mnist.sh
结果:


2、载入MNIST网络并开始训练
1)找到CAFFE_ROOT/examples/mnist/lenet_train_test.prototxt
layer { //数据层
name: "mnist" //输入层的名字为mnist
type: "Data" //输入的类型为data
top: "data"
top: "label" //然后这层后面连接data和label Blob空间
include {
phase: TRAIN //训练用
}
transform_param {
scale: 0.00390625 //把输入像素灰度归一到[0,1),将1/256得到
}
data_param { //数据的参数
source: "examples/mnist/mnist_train_lmdb" //从mnist_train_lmdb中读入数据
batch_size: 64 //批次大小为64,即为了提高性能,一次处理64条数据
backend: LMDB
}
}
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
include {
phase: TEST //测试用
}
transform_param {
scale: 0.00390625
}
data_param {
source: "examples/mnist/mnist_test_lmdb"
batch_size: 100
backend: LMDB
}
}layer { //卷积层
name: "conv1"
type: "Convolution" //类型为卷积
bottom: "data"
top: "conv1" //这层前面使用data,后面生成conv1的Blob空间
param {
lr_mult: 1 //学习率调整的参数,我们设置权重学习率和运行中求解器给出的学习率一样,同时是偏置
}
param {
lr_mult: 2 //学习率的两倍
}
convolution_param { //卷积层的参数
num_output: 20 //输出单元数
kernel_size: 5 //卷积核大小
stride: 1 //步长为1 //网络允许我们用随机值初始化权重和偏置值
weight_filler {
type: "xavier" //使用xavier算法自动确定基于输入和输出神经元数量的初始规模
}
bias_filler {
type: "constant" //偏置值初始化为常数,默认为0
}
}
}
layer { //池化层
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param { //pooling层的参数
pool: MAX //pooling的方式是MAX
kernel_size: 2 //pooling的核是2×2
stride: 2 //步长是2
}
}layer { //全连接层,在某些特殊原因下看成卷积层,因此结构差不多
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer { //ReLU层,由于是元素级的操作,我们可以现场激活来节省内存
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}
layer { //然后是loss层,该softmax_loss层同时实现了SOFTMAX和多项Logistic损失,既节省了时间,同时提高了数据稳定性。它需要两块,第一块是预测,第二块是数据层提供的标签,它不产生任何输出,它做的是去计算损失函数值,在BP算法运行的时候使用,启动相对于ip2的梯度。
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
2)找到CAFFE_ROOT/examples/mnist/lenet_solver.prototxt
# 定义训练和检测数据来源
net: "examples/mnist/lenet_train_test.prototxt"
# 这里是训练的批次,设为100,迭代次数为100次,这样,就覆盖了10000张(100*100)
test_iter: 100
# 每迭代次数500次测试一次
test_interval: 500
# 学习率,动量,权重的递减
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# 学习政策inv,注意,cifar10类用固定学习率,imagenet用每步递减学习率
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# 每迭代100次显示一次
display: 100
# 最大迭代次数10000次
max_iter: 10000
# 每5000次迭代存储一次数据到电脑,名字是lenet
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
# 训练模式:GPU
solver_mode: GPU
3)找到CAFFE_ROOT/examples/mnist/train_lenet.sh
#!/usr/bin/env sh
set -e
./Build/x64/Release/caffe train --solver=D:/caffe_test/caffe-master/examples/mnist/lenet_solver.prototxt $@
4)运行train_lenet.sh
结果:


3、测试
1)在CAFFE_ROOT/examples/mnist下新建test_lenet.sh,代码如下
#!/usr/bin/env sh
set -e
./Build/x64/Release/caffe test -model=D:/caffe_test/caffe-master/examples/mnist/lenet_train_test.prototxt -weights=D:/caffe_test/caffe-master/examples/mnist/lenet_iter_10000.caffemodel $@
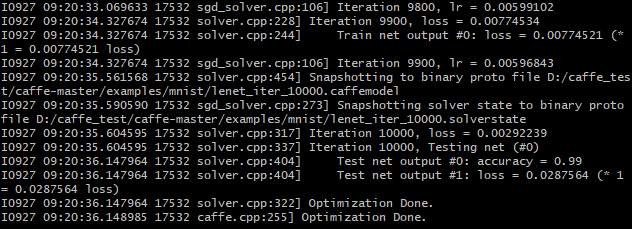
2)运行test_lenet.sh
结果:
4、总结
在设置一些文件的路径时,可以给出绝对路径,也可以给出相对路径。















 4179
4179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









