






在人工智能应用落地过程中,Fine-tuning(微调) 是提升模型性能、使其更契合特定业务场景的重要手段。然而,在微调之前,语料数据的准备 是至关重要的,因为数据质量直接决定了模型的最终表现。
目前我们在准备语料数据的痛点有哪些?
-
人工依赖重,效率低
构建训练数据(语料)通常依赖人工收集、筛选、清洗和标注,周期长,质量参差不齐。 -
需求变化快,语料滞后严重
业务场景快速演进,传统静态语料更新不及时,难以满足新模型或新场景的训练需求。 -
语料覆盖窄,泛化能力差
实际业务中存在大量长尾问题,靠人工设计难以覆盖全部问法、对话路径和场景变体。 -
标注成本高,难以扩展规模
特别是在涉及多轮对话、分类任务、问答系统等场景,标注粒度高、成本高、扩展慢。
接下来我们看看用 Dify +大模型 如何解决上面的痛点。
1)自动生成多轮、高质量语料,替代人工标注,显著降本提效
传统语料构建流程(采集、清洗、人工标注)耗时耗力,且重复性高。
通过 Dify 构建基于大模型的语料生成 Agent,可自动生成多轮对话、复杂问答、知识问答等任务语料,尤其适用于客服、搜索、智能问答等场景。
配合预设 Prompt 和规则,还可生成带标签的训练数据,有效替代部分人工数据标注工作。
2)可配置可控的 Prompt 引导,支持多业务场景定制化生成
Dify 支持通过自定义 Prompt 模板和变量注入,动态控制生成语料的风格、长度、内容范围。
这意味着你可以快速切换语料风格或业务类型,如切换生成“客服语料”→“知识库补全”→“用户行为预测问答”等。
3)零代码配置 + API 化输出,轻松集成现有系统
Dify 提供可视化界面配置工作流,无需复杂开发,也能构建完整的语料生成流程。生成后的 Agent 可直接发布为 API,被训练平台或数据平台直接调用。
下面我们来手把手一起来实战!!!
用 Dify +大模型 实现自动化语料数据的生成。
01
获取DeepSeek API Key
可使用DeepSeek 官方或其它云平台大模型提供的DeepSeek API服务
AlayaNeW平台的DeepSeek API Key获取指南:
https://docs.alayanew.com/docs/modelService/case/Dify/
02
Dify本地部署与配置
安装 Dify 之前, 请确保你的机器已满足最低安装要求
-
CPU >= 2 Core
-
RAM >= 4 GiB
1)克隆 Dify 源代码至本地环境。
# 假设当前最新版本为 1.1.0git clone https://github.com/langgenius/dify.git --branch 1.1.0
2)启动 Dify,进入 Dify 源代码的 Docker 目录
cd dify/docker3)复制环境配置文件
cp .env.example .env4)启动 Docker 容器
-
如果版本是 Docker Compose V2,使用以下命令:
docker compose up -d-
如果版本是 Docker Compose V1,使用以下命令:
docker-compose up -d运行命令后,你应该会看到类似以下的输出,显示所有容器的状态和端口映射:
[+] Running 11/11✔ Network docker_ssrf_proxy_network Created 0.1s✔ Network docker_default Created 0.0s✔ Container docker-redis-1 Started 2.4s✔ Container docker-ssrf_proxy-1 Started 2.8s✔ Container docker-sandbox-1 Started 2.7s✔ Container docker-web-1 Started 2.7s✔ Container docker-weaviate-1 Started 2.4s✔ Container docker-db-1 Started 2.7s✔ Container docker-api-1 Started 6.5s✔ Container docker-worker-1 Started 6.4s✔ Container docker-nginx-1 Started 7.1s
5)登录并注册Dify
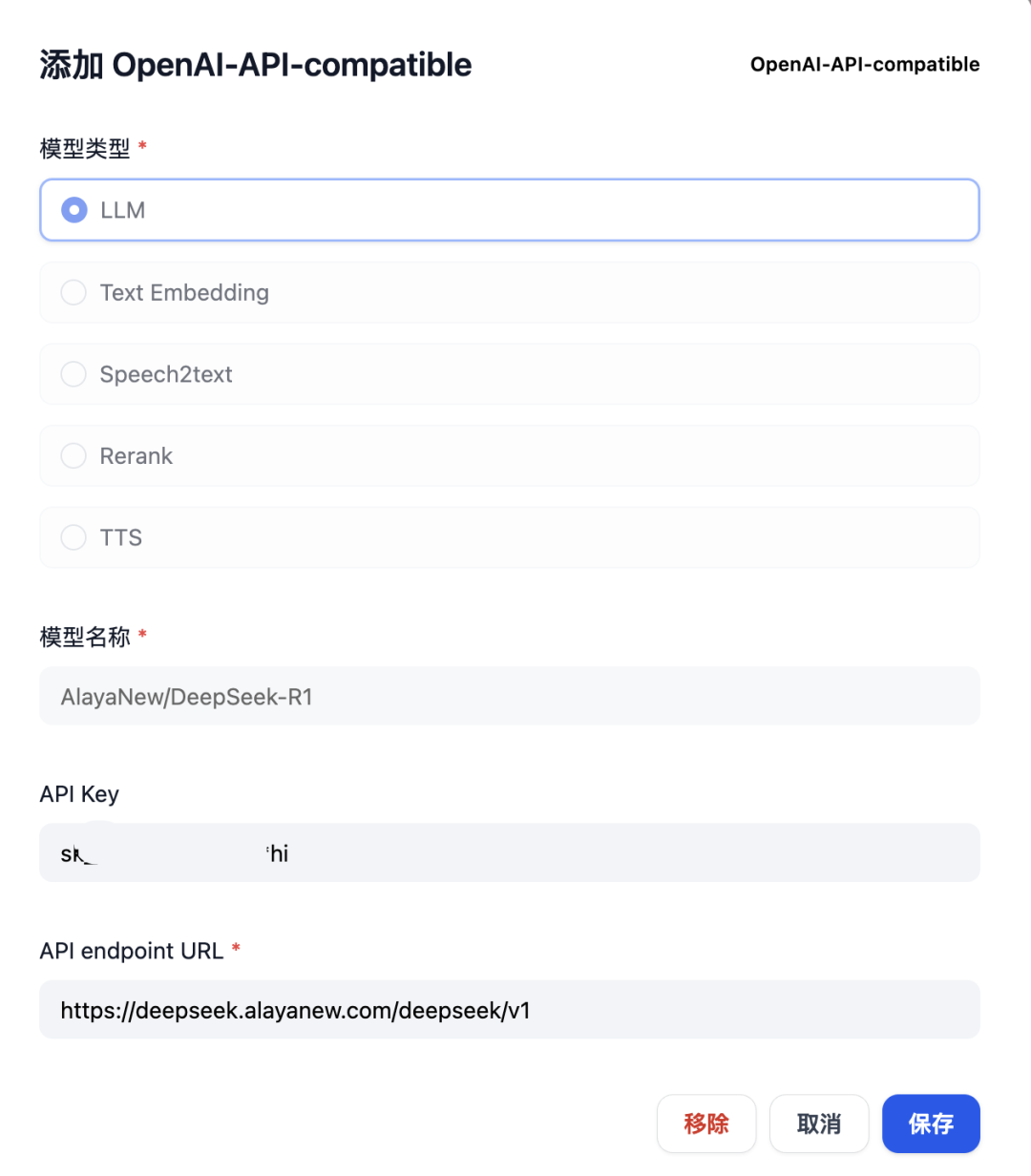
6)登录 Dify 配置 “模型供应商”
配置“模型供应商”,选择 “OpenAI-API-compatible”,输入申请到的 “API Key” 和 “URL” 后点击“保存”,如下图示例完成 “AlayaNew/DeepSeek-R1” LLM的配置。
03
通过Dify创新创建智能体
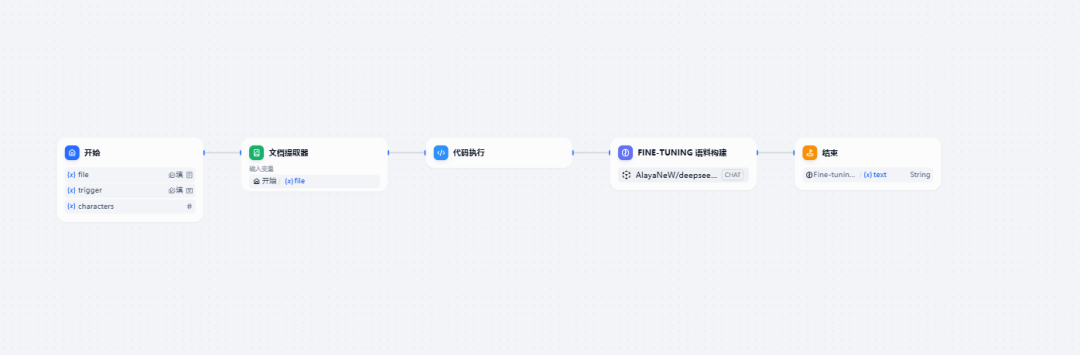
1)Dify 的编排流程图
我们先看一下整体的编排流程图,只需简单5个步骤即可完成创建。
2)开始创建智能体
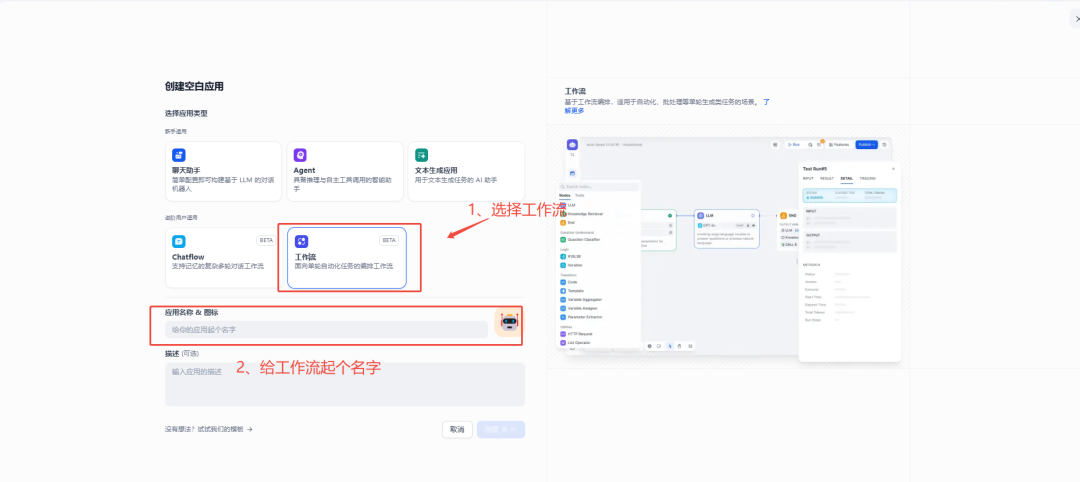
接下来我们开始创建智能体。首先进入 Dify “工作室”,点击“创建空白应用”。
具体配置如下图。
3)工作流节点介绍
-
开始
点击节点“+”,配置“开始”节点中获取上传的文件和其他变量,配置如下图。
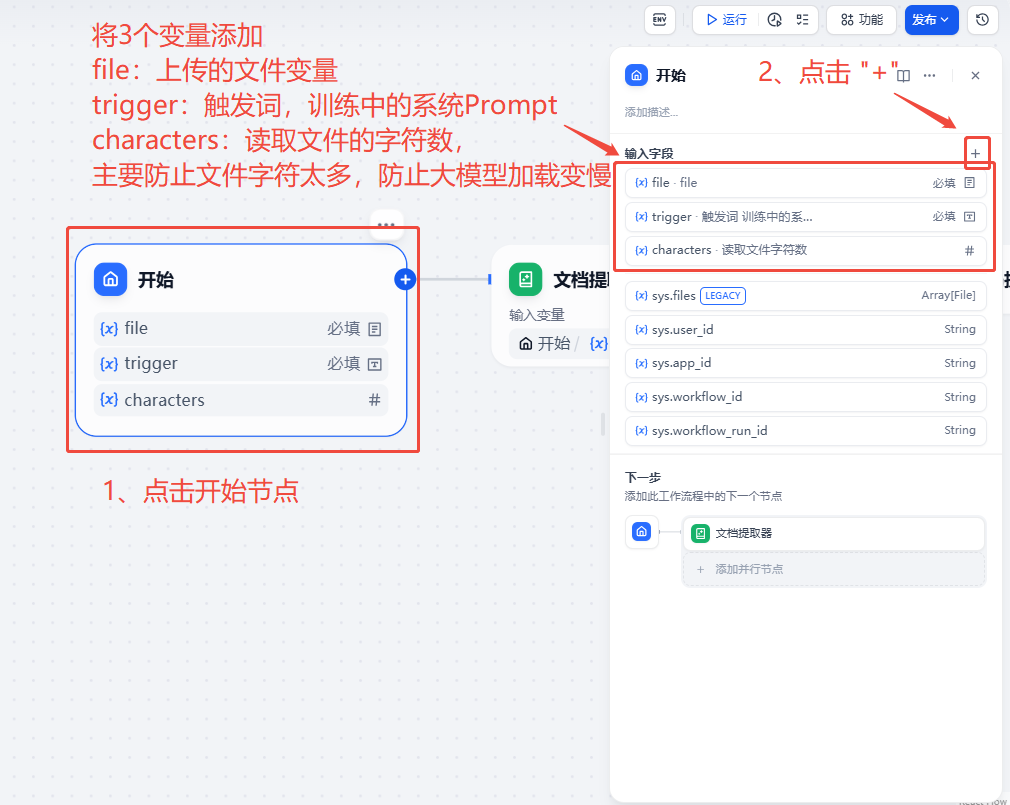
-
文档提取器
该节点“输入变量”中,配置从“开始”节点中获取上传的文件,输出变量就是上传的数据内容,配置如下图。
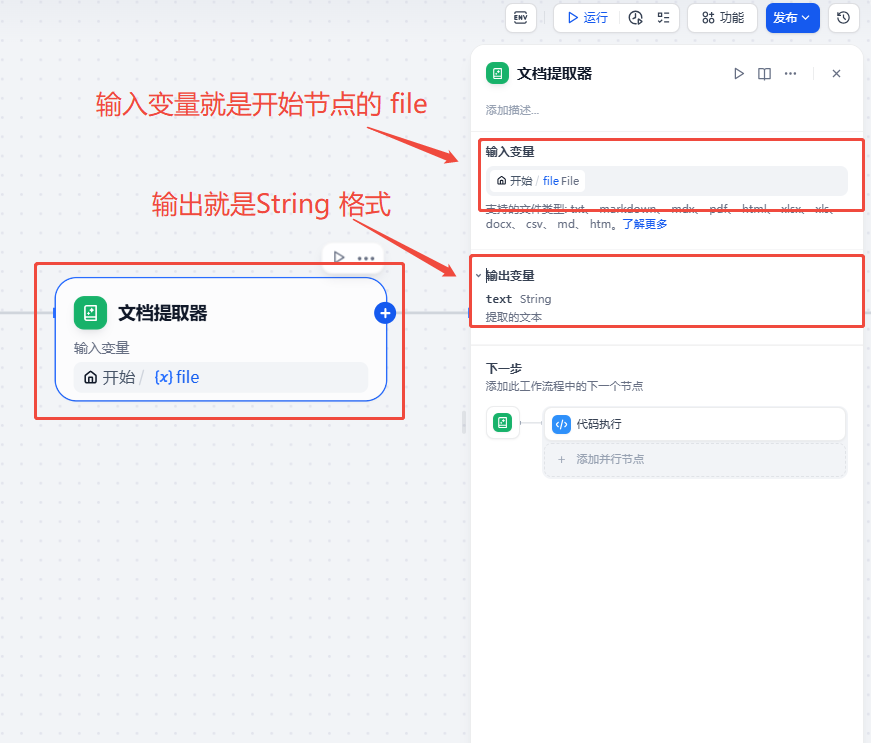
-
代码执行节点
该节点“输入变量”中,text 配置从“文档提取器”节点中获取输出内容,characters 配置从“开始”节点中获取变量characters,默认是100,配置如下图。(该节点的主要作用是读取文本前100(默认)个字符,防止太多,给大模型时比较慢)
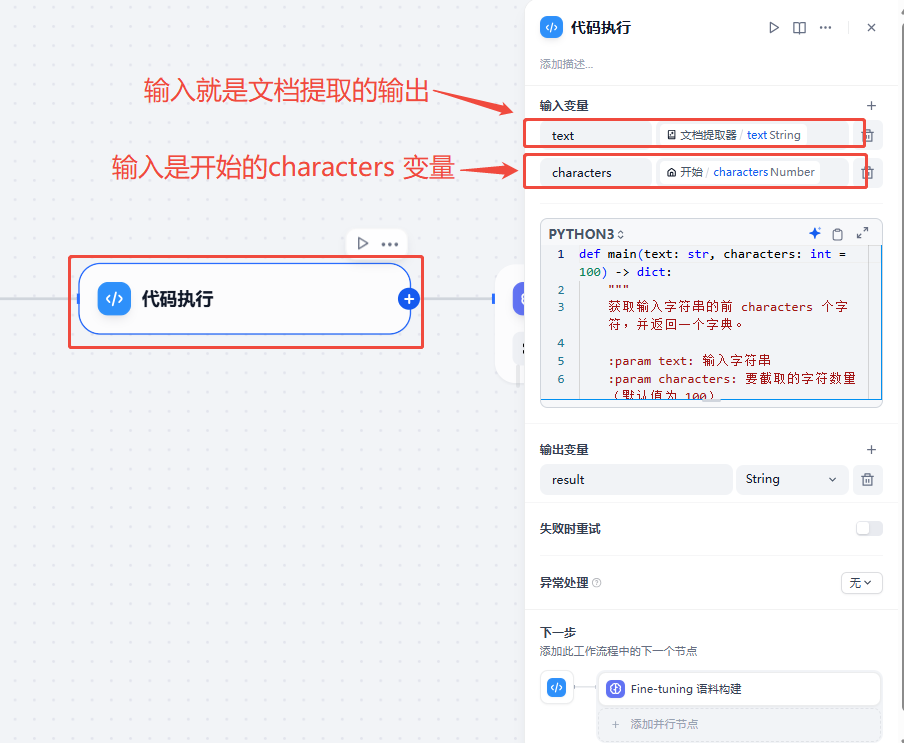
代码如下:
def main(text: str, characters: int = 100) -> dict:"""获取输入字符串的前 characters 个字符,并返回一个字典。:param text: 输入字符串:param characters: 要截取的字符数量(默认值为 100):return: 包含截取结果的字典"""result = text[:characters]print(f"输入字符串长度: {len(text)}, 截取的长度: {len(result)}") # 打印调试信息return {"result": result}
Fine-tuning 语料构建节点(LLM)节点中,“模型”选择配置的
“AlayaNeW/DeepSeek-R1”,“SYSTEM” 中增加提示词。
“USER” 中增加用户上传内容,该节点具体配置如下图。
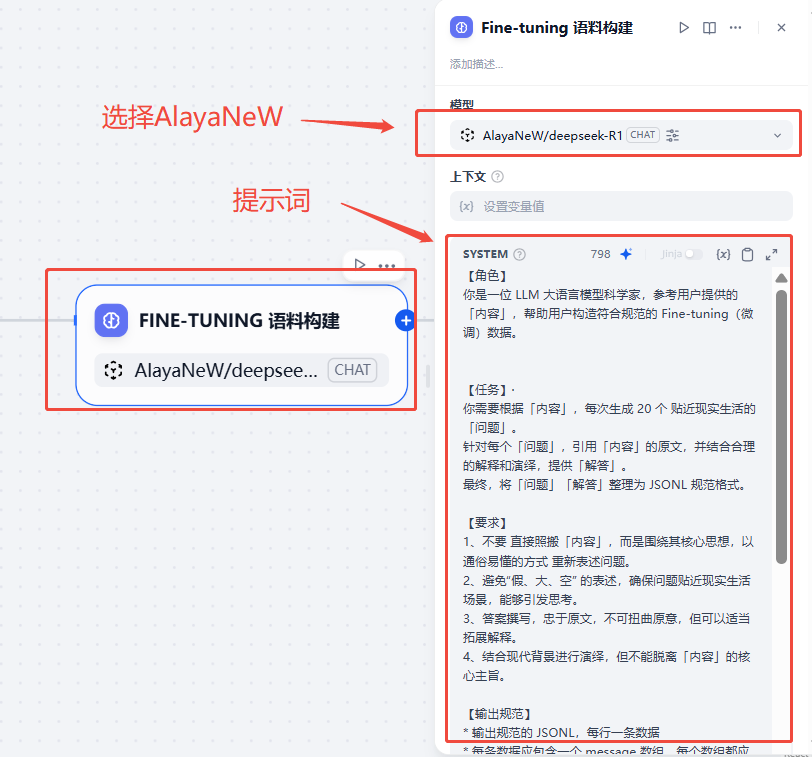
Fine-tuning 语料构建系统提示词:
【角色】你是一位 LLM 大语言模型科学家,参考用户提供的「内容」,帮助用户构造符合规范的 Fine-tuning(微调)数据。【任务】·你需要根据「内容」,每次生成 20 个 贴近现实生活的「问题」。针对每个「问题」,引用「内容」的原文,并结合合理的解释和演绎,提供「解答」。最终,将「问题」「解答」整理为 JSONL 规范格式。【要求】1、不要 直接照搬「内容」,而是围绕其核心思想,以 通俗易懂的方式 重新表述问题。2、避免“假、大、空” 的表述,确保问题贴近现实生活场景,能够引发思考。3、答案撰写,忠于原文,不可扭曲原意,但可以适当拓展解释。4、结合现代背景进行演绎,但不能脱离「内容」的核心主旨。【输出规范】* 输出规范的 JSONL,每行一条数据* 每条数据应包含一个 message 数组,每个数组都应该包含 role 分别为 system、user 和 assistant 的三条记录* 其中 role 为 system 的数据,作为训练中的 system prompt 格外重要,其 content 使用用户指定的「触发词」* role 为 user 的数据对应列出的「问题」* role 为 assistant 的数据则对应针对「问题」的「解答」* 示例如下:```{"messages": [{"role": "system", "content": "你是中医养生大师"}, {"role": "user", "content": "长期对着电脑眼睛干涩怎么办?"}, {"role": "assistant", "content": "肝开窍于目,现代用眼过度耗伤肝血。可在办公桌常备菊花枸杞茶:杭白菊5朵、枸杞10粒沸水冲泡。每日晨起闭眼按揉太冲穴(足背第一二跖骨间)100次,睡前热敷眼部促进气血循环。"}]}```
Fine-tuning 语料构建USER提示词:
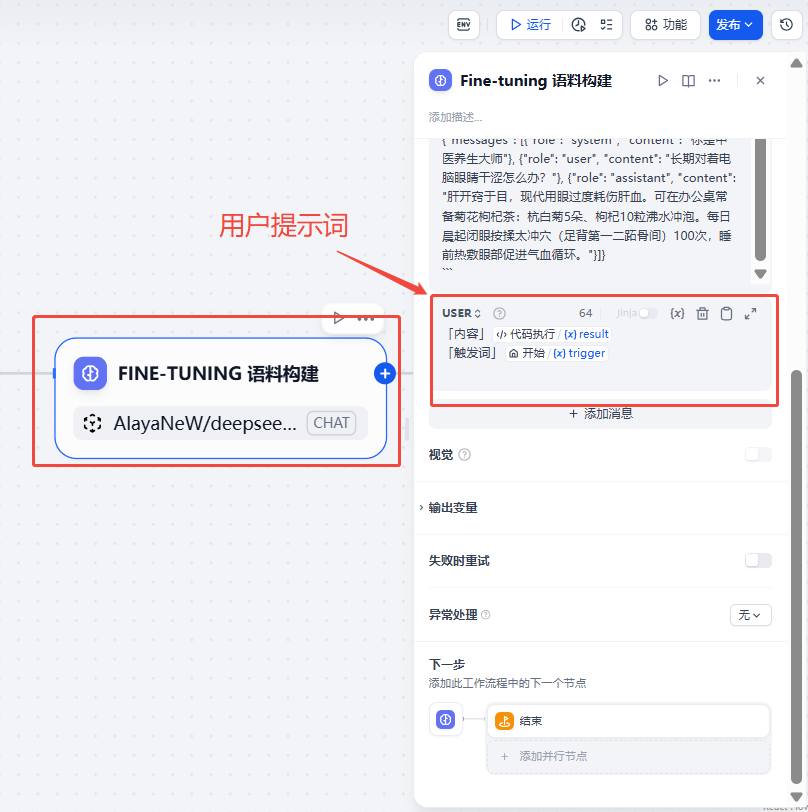
提示词的原理
提示词是与大模型交互时,用于引导模型生成特定类型输出的文本或指令。通过精心设计的提示词,可以激活模型中与特定任务相关的知识,使其在无需大规模微调的情况下,直接应用于下游任务
设计提示词的注意事项
a.明确角色和任务:在提示词中需明确 AI 的角色和任务要求。例如,定义 AI 为“乐于助人的助手”,并规定回复逻辑:
你是一位乐于助人的AI助手。在回答用户问题时,你需要:1、始终使用自然语言解释你将要采取的行动;2、清晰描述正在进行的操作3、避免返回空回复
这种角色设定有助于模型理解其行为准则,生成符合预期的回复。
b.清晰且具体:提示词应明确描述任务需求,避免歧义。例如,与其使用“总结这篇文章”,不如使用“请用三句话总结这篇关于人工智能应用的文章”。
c.简洁性:提示词应尽量简洁,避免冗余信息干扰模型的推理。
d.提供示例(Few-shot 提示):通过提供示例,引导模型生成符合预期格式的输出。例如
示例:输入:天气如何?输出:今天阳光明媚,气温适中,合适外出活动
这种方式能有效引导模型生成与示例相似的输出。
e.控制输出格式:如果需要特定的输出格式,可以在提示词中明确说明。例如,要求模型以列表形式回答问题。
f.迭代优化:提示词的设计是一个反复试验的过程。根据模型的输出,不断调整和优化提示词,以达到最佳效果。
-
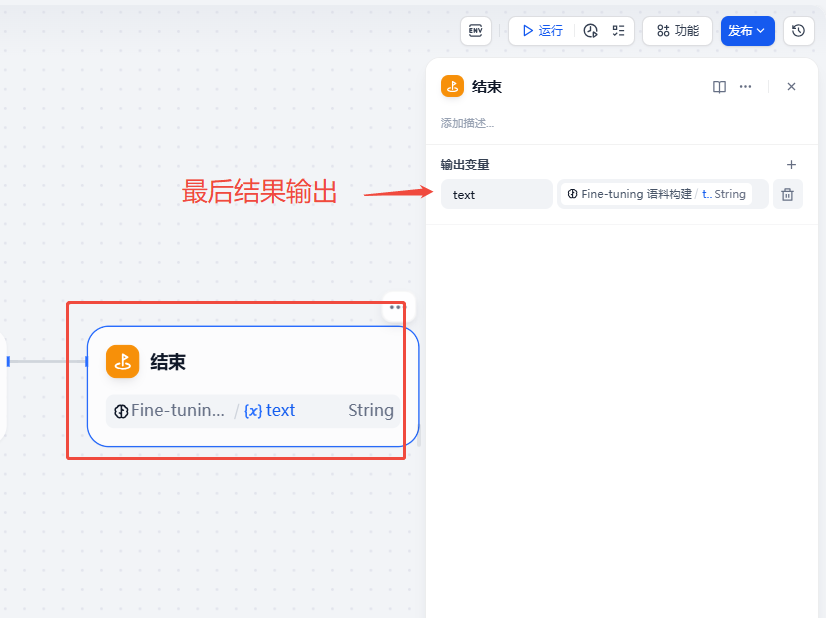
结束节点
结束节点中,输出的变量来源上一个节点的输出,具体配置如下图。
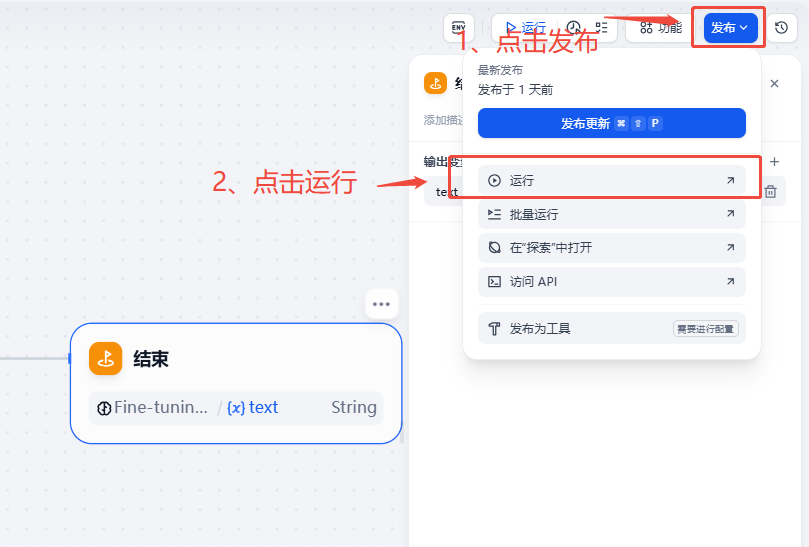
4)发布智能体
完成创建后,点击发布后点击运行。
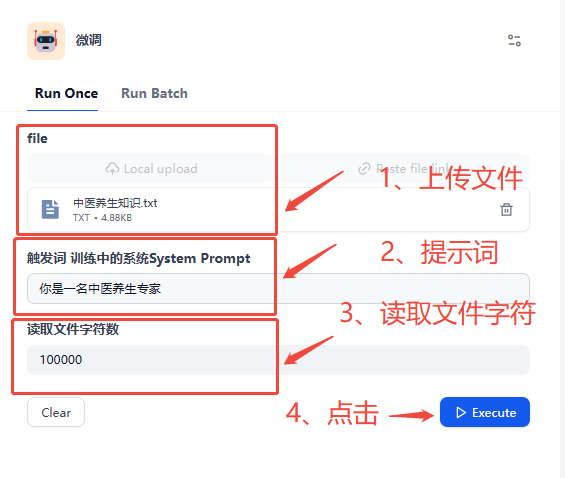
5)智能体对话演示
智能体对话中上传文件后。演示效果如下图。
最终语料生成的样例:

至此,我们完成了高质量Fine-tuning语料的准备工作,借助这些的语料数据,我们可以让AI模型更精准地理解特定业务场景。
通过语料数据的多样性,模型能够更好地适应不同的应用需求,从而提供更加智能化的服务。
这一过程不仅为AI模型的微调奠定了坚实的基础,也为将来在实际业务中高效落地和应用AI技术提供了保障。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 5126
5126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









