







一、配置
1、 从http://code.google.com/p/tesseract-ocr/downloads/list下载tesseract-ocr-3.02-vs2008、tesseract-ocr-3.02.eng.tar、tesseract-ocr-3.02.02.tar、leptonica-1.68-win32-lib-include-dirs相关文件;
2、 将所有文件存放在D:\BulidFolder文件夹下并解压缩;


3、 下载tesseract-ocr-setup-3.02.02.exe,安装到d盘,生成目录Tesseract-OCR。
4、 将ccmain文件夹下的equationdetect.cpp文件中的static const STRING kCharsToEx[] = {"'", "`","\"", "\\", ",", ".", "〈", "〉", "《", "》", "」", "「", ""};修改成static const STRING kCharsToEx[] = {"'", "`","\"", "\\", ",",".","<", ">", "<<",">>", ""};(注:不改动编译时始终出错,其它方法暂未发现,3.01版本中没有此文件,编译3.01不用对源文件作任何修改)。
5、 打开D:\OCR\code\tesseract-ocr\vs2008的tesseract.sln,重新编译整个Solution;
二、训练新的语言包
Tesseract是一个开源的OCR(Optical Character Recognition,光学字符识别)引擎,可以识别多种格式的图像文件并将其转换成文本,目前已支持60多种语言(包括中文)。 Tesseract最初由HP公司开发,后来由Google维护,目前发布在Googel Project上。地址为http://code.google.com/p/tesseract-ocr/。
使用默认的语言库识别
1.安装Tesseract
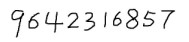
3. 打开命令行,定位到Tesseract-OCR目录,输入命令:
- tesseract.exe number.jpg result -l eng
tesseract.exe number.jpg result -l eng
其中result表示输出结果文件txt名称,eng表示用以识别的语言文件为英文。
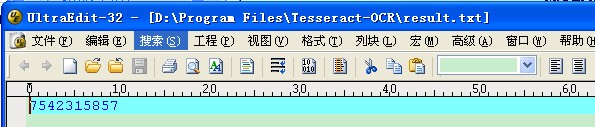
3. 打开Tesseract-OCR目录下的result.txt文件,看到识别的结果为7542315857,有3个字符识别错误,识别率还不是很高,那有没有什么方法来提供识别率呢?
其实Tesseract提供了一套训练样本的方法,用以生成自己所需的识别语言库。下面介绍一下具体训练样本的方法。
训练样本
1.下载工具jTessBoxEditor. http://sourceforge.net/projects/vietocr/files/jTessBoxEditor/,这个工具是用来训练样本用的,由于该工具是用JAVA开发的,需要安装JAVA虚拟机才能运行。
2. 获取样本图像。用画图工具绘制了5张0-9的文样本图像(当然样本越多越好),如下图所示:
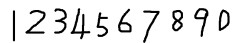
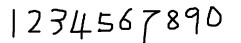
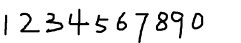
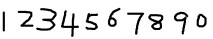
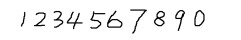
3.合并样本图像。运行jTessBoxEditor工具,在点击菜单栏中Tools--->Merge TIFF。在弹出的对话框中选择样本图像(按Shift选择多张),合并成num.font.exp0.tif文件。4.生成Box File文件。打开命令行,执行命令:
- tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox
tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox
生成的BOX文件为num.font.exp0.box,BOX文件为Tessercat识别出的文字和其坐标。
注:Make Box File的命令格式为:
- tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
其中lang为语言名称,fontname为字体名称,num为序号,可以随便定义。
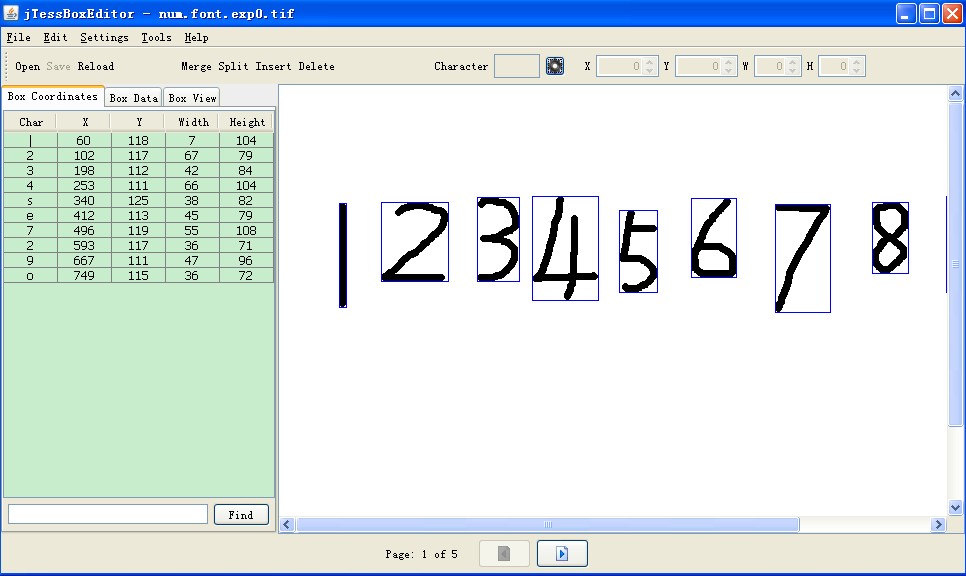
5.文字校正。运行jTessBoxEditor工具,打开num.font.exp0.tif文件(必须将上一步生成的.box和.tif样本文件放在同一目录),如下图所示。可以看出有些字符识别的不正确,可以通过该工具手动对每张图片中识别错误的字符进行校正。校正完成后保存即可。
6.定义字体特征文件。Tesseract-OCR3.01以上的版本在训练之前需要创建一个名称为font_properties.txt的字体特征文件。
font_properties不含有BOM头,文件内容格式如下:
- <fontname> <italic> <bold> <fixed> <serif> <fraktur>
<fontname> <italic> <bold> <fixed> <serif> <fraktur>
其中fontname为字体名称,必须与[lang].[fontname].exp[num].box中的名称保持一致。<italic> 、<bold> 、<fixed> 、<serif>、 <fraktur>的取值为1或0,表示字体是否具有这些属性。
这里在样本图片所在目录下创建一个名称为font_properties的文件,用记事本打开,输入以下下内容:
- font 0 0 0 0 0
font 0 0 0 0 0这里全取值为0,表示字体不是粗体、斜体等等。
7.生成语言文件。在样本图片所在目录下创建一个批处理文件,输入如下内容。
- rem 执行改批处理前先要目录下创建font_properties文件
- echo Run Tesseract for Training..
- tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
- echo Compute the Character Set..
- unicharset_extractor.exe num.font.exp0.box
- mftraining -F font_properties.txt -U unicharset -O num.unicharset num.font.exp0.tr
- echo Clustering..
- cntraining.exe num.font.exp0.tr
- echo Rename Files..
- rename normproto num.normproto
- rename inttemp num.inttemp
- rename pffmtable num.pffmtable
- rename shapetable num.shapetable
- echo Create Tessdata..
- combine_tessdata.exe num.
rem 执行改批处理前先要目录下创建font_properties文件
echo Run Tesseract for Training..
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp0.box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.
将批处理通过命令行执行。执行后的结果如下:
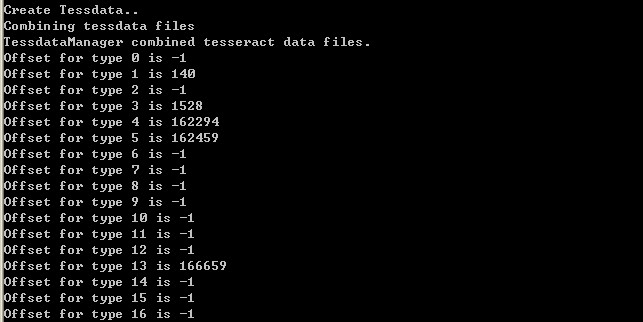
需确认打印结果中的Offset 1、3、4、5、13这些项不是-1。这样,一个新的语言文件就生成了。
num.traineddata便是最终生成的语言文件,将生成的num.traineddata拷贝到Tesseract-OCR-->tessdata目录下。可以用它来进行字符识别了。
使用训练后的语言库识别
用训练后的语言库识别number.jpg文件, 打开命令行,定位到Tesseract-OCR目录,输入命令:
- tesseract.exe number.jpg result -l eng
tesseract.exe number.jpg result -l eng
识别结果如如图所示,可以看到识别率提高了不少。通过自定义训练样本,可以进行图形验证码、车牌号码识别等。感兴趣的朋友可以研究研究。

三、结合C++使用
1. 直接调用图片
#include "strngs.h"
#include "baseapi.h"
#pragma comment(lib,"libtesseract302d.lib")
tesseract::TessBaseAPI api;
api.Init(NULL, "eng", tesseract::OEM_DEFAULT); //初始化,设置语言包,中文简体:chi_sim;英文:eng;也可以自己训练语言包
//api.SetVariable( "tessedit_char_whitelist", "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz" );
STRING text_out;
if (!api.ProcessPages("kaze.tif", NULL, 0, &text_out))
{
//AfxMessageBox("tesseract 处理出现异常");
return 0;
}
cout<<text_out.string();
cout<<UTF8ToGBK(text_out.string()).c_str();
2. 直接调用文本
// tess.cpp:
// Recognize text on an image using Tesseract API and print it to the screen
// Usage: ./tess image.png
#include <tesseract/baseapi.h>
#include <tesseract/strngs.h>
#include <iostream>
int main(int argc, char** argv)
{
if (argc != 2)
{
std::cout << "Please specify the input image!" << std::endl;
return -1;
}
const char* lang = "eng";
const char* filename = argv[1];
//新建tess基类
tesseract::TessBaseAPI tess;
//初始化
tess.Init(NULL, lang, tesseract::OEM_DEFAULT);
//设置识别模式
tess.SetPageSegMode(tesseract::PSM_SINGLE_BLOCK);
FILE* fin = fopen(filename, "rb");
if (fin == NULL)
{
std::cout << "Cannot open " << filename << std::endl;
return -1;
}
fclose(fin);
STRING text;
//进行识别
if (!tess.ProcessPages(filename, NULL, 0, &text))
{
std::cout << "Error during processing." << std::endl;
return -1;
}
else
std::cout << text.string() << std::endl;
return 0;
}
2. 结合OpencCV使用
// tesscv.cpp:
// Using Tesseract API with OpenCV
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <tesseract/baseapi.h>
#include <iostream>
int main(int argc, char** argv)
{
// Usage: tesscv image.png
if (argc != 2)
{
std::cout << "Please specify the input image!" << std::endl;
return -1;
}
// Load image
cv::Mat im = cv::imread(argv[1]);
if (im.empty())
{
std::cout << "Cannot open source image!" << std::endl;
return -1;
}
cv::Mat gray;
cv::cvtColor(im, gray, CV_BGR2GRAY);
// ...other image pre-processing here...
// Pass it to Tesseract API
tesseract::TessBaseAPI tess;
tess.Init(NULL, "eng", tesseract::OEM_DEFAULT);
tess.SetPageSegMode(tesseract::PSM_SINGLE_BLOCK);
tess.SetImage((uchar*)gray.data, gray.cols, gray.rows, 1, gray.cols);
// Get the text
char* out = tess.GetUTF8Text();
std::cout << out << std::endl;
return 0;
}















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









