







1:简单概念描述
假设现在有一些数据点,我们用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称为回归。训练分类器就是为了寻找最佳拟合参数,使用的是最优化算法。
这就是简单的线性回归问题,可以通过最小二乘法求解其参数,最小二乘法和最大似然估计见:http://blog.csdn.net/lu597203933/article/details/45032607。 但是当有一类情况如判断邮件是否为垃圾邮件或者判断患者癌细胞为恶性的还是良性的,这就属于分类问题了,是线性回归所无法解决的。这里以线性回归为基础,讲解logistic回归用于解决此类分类问题。
基于sigmoid函数分类:logistic回归想要的函数能够接受所有的输入然后预测出类别。这个函数就是sigmoid函数,它也像一个阶跃函数。其公式如下:

其中: z = w0x0+w1x1+….+wnxn,w为参数, x为特征
为了实现logistic回归分类器,我们可以在每个特征上乘以一个回归系数,然后把所有的结果值相加,将这个总和结果代入sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于0.5的数据被分入1类,小于0.5的数据被归入0类。所以,logistic回归也可以被看成是一种概率估计。
亦即公式表示为:

g(z)曲线为:

此时就可以对标签y进行分类了:
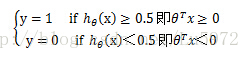
其中θTx=0 即θ0+θ1*x1+θ2*x2=0 称为决策边界即boundarydecision。
Cost function:
线性回归的cost function依据最小二乘法是最小化观察值和估计值的差平方和。即:
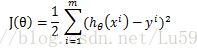
但是对于logistic回归,我们的cost fucntion不能最小化观察值和估计值的差平法和,因为这样我们会发现J(θ)为非凸函数,此时就存在很多局部极值点,就无法用梯度迭代得到最终的参数(来源于AndrewNg video)。因此我们这里重新定义一种cost function
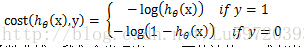
通过以上两个函数的函数曲线,我们会发现当y=1,而估计值h=1或者当y=0,而估计值h=0,即预测准确了,此时的cost就为0,,但是当预测错误了cost就会无穷大,很明显满足cost function的定义。
可以将上面的分组函数写在一起:
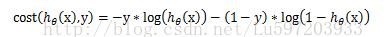
这样得到总体的损失函数J(θ)为:
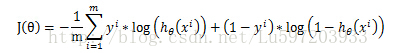
梯度上升法:基于的思想是要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。
该公式将一直被迭代执行,直到达到某个停止条件为止,比如迭代次数达到某个指定值或者算法达到某个可以允许的误差范围。
这样我们依据上面的J(θ)就可以得到梯度上升的公式:
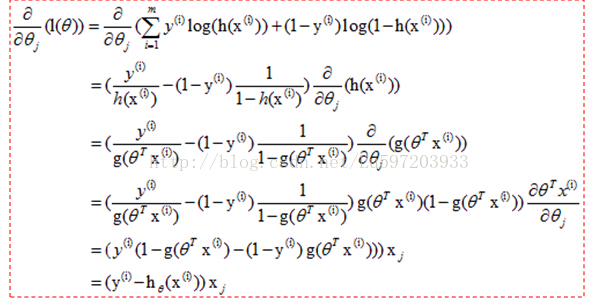
当然上图中少了个求和符号。这样就得到
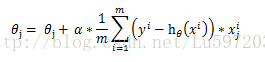
当然对于随机化的梯度迭代每次只使用一个样本进行参数更新,就为:
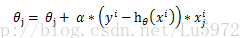
这也是下面代码中公式的来源。
例如:data=[1,2,3;4,5,6;7,8,9;10,11,12]为4个样本点,3个特征的数据集,,此时标签为[1,0,0,0],
那么用梯度上升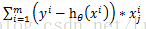
为什么要采用上面的函数作为cost function?
Andrew Ng给的解释是因为最小估计值和观察值的差平方和为非凸函数,通过函数曲线观察得到上面的cost function满足条件。
这里给出另外一种解释——最大似然估计
我们知道hθ(x)≥0.5<后面简用h>,此时y=1, 小于0.5,y=0. 那么我们就用h作为y=1发生的概率,那么当y=0时,h<0.5,此时不能用h作为y=0的概率,<因为最大似然的思想使已有的数据发生的概率最大化,小于0.5太小了>,我们可以用1-h作为y=0的概率,这样就可以作为y=0的概率了,,然后只需要最大化联合概率密度函数就可以了。
这样联合概率密度函数就可以写成:
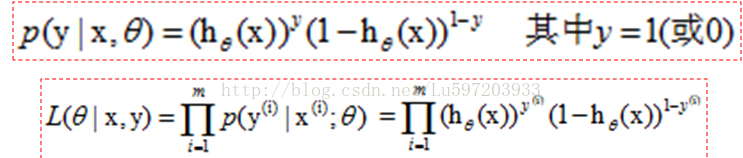
再转换成对数似然函数,就和上面给出的似然函数一致了。
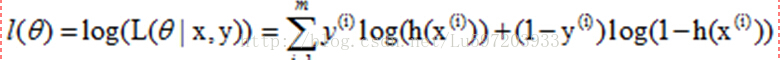
2:python代码的实现
(1) 使用梯度上升找到最佳参数
- from numpy import *
- #加载数据
- def loadDataSet():
- dataMat = []; labelMat = []
- fr = open(’testSet.txt’)
- for line in fr.readlines():
- lineArr = line.strip().split()
- dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
- labelMat.append(int(lineArr[2]))
- return dataMat, labelMat
- #计算sigmoid函数
- def sigmoid(inX):
- return 1.0/(1+exp(-inX))
- #梯度上升算法-计算回归系数
- def gradAscent(dataMatIn, classLabels):
- dataMatrix = mat(dataMatIn) #转换为numpy数据类型
- labelMat = mat(classLabels).transpose()
- m,n = shape(dataMatrix)
- alpha = 0.001
- maxCycles = 500
- weights = ones((n,1))
- for k in range(maxCycles):
- h = sigmoid(dataMatrix*weights)
- error = (labelMat - h)
- weights = weights + alpha * dataMatrix.transpose() * error
- return weights
from numpy import *
梯度上升算法-计算回归系数
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn) #转换为numpy数据类型
labelMat = mat(classLabels).transpose()
m,n = shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix*weights)
error = (labelMat - h)
weights = weights + alpha * dataMatrix.transpose() * error
return weights

(2) 画出决策边界
- #画出决策边界
- def plotBestFit(wei):
- import matplotlib.pyplot as plt
- weights = wei.getA()
- dataMat, labelMat = loadDataSet()
- dataArr = array(dataMat)
- n = shape(dataArr)[0]
- xcord1 = []; ycord1 = []
- xcord2 = []; ycord2 = []
- for i in range(n):
- if int(labelMat[i]) == 1:
- xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
- else: xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
- fig = plt.figure()
- ax = fig.add_subplot(111)
- ax.scatter(xcord1, ycord1, s = 30, c = ‘red’, marker=’s’)
- ax.scatter(xcord2, ycord2, s = 30, c = ‘green’)
- x = arange(-3.0, 3.0, 0.1)
- y = (-weights[0]- weights[1]*x)/weights[2]
- ax.plot(x, y)
- plt.xlabel(’X1’);
- plt.ylabel(’X2’);
- plt.show()
#画出决策边界
def plotBestFit(wei):
import matplotlib.pyplot as plt
weights = wei.getA()
dataMat, labelMat = loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else: xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s = 30, c = 'red', marker='s')
ax.scatter(xcord2, ycord2, s = 30, c = 'green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]- weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X1');
plt.ylabel('X2');
plt.show()

(3) 随机梯度上升算法
梯度上升算法在处理100个左右的数据集时尚可,但如果有数十亿样本和成千上万的特征,那么该方法的计算复杂度就太高了。改进方法为随机梯度上升算法,该方法一次仅用一个样本点来更新回归系数。它占用更少的计算资源,是一种在线算法,可以在数据到来时就完成参数的更新,而不需要重新读取整个数据集来进行批处理运算。一次处理所有的数据被称为批处理。
- #随机梯度上升算法
- def stocGradAscent0(dataMatrix, classLabels):
- dataMatrix = array(dataMatrix)
- m,n = shape(dataMatrix)
- alpha = 0.1
- weights = ones(n)
- for i in range(m):
- h = sigmoid(sum(dataMatrix[i] * weights))
- error = classLabels[i] - h
- weights = weights + alpha * error * dataMatrix[i]
- return weights
#随机梯度上升算法
def stocGradAscent0(dataMatrix, classLabels):
dataMatrix = array(dataMatrix)
m,n = shape(dataMatrix)
alpha = 0.1
weights = ones(n)
for i in range(m):
h = sigmoid(sum(dataMatrix[i] * weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights

(4) 改进的随机梯度上升算法
- #改进的随机梯度上升算法
- def stocGradAscent1(dataMatrix, classLabels, numInter = 150):
- dataMatrix = array(dataMatrix)
- m,n = shape(dataMatrix)
- weights = ones(n)
- for j in range(numInter):
- dataIndex = range(m)
- for i in range(m):
- alpha = 4 / (1.0+j+i) + 0.01 #alpha值每次迭代时都进行调整
- randIndex = int(random.uniform(0, len(dataIndex))) #随机选取更新
- h = sigmoid(sum(dataMatrix[randIndex] * weights))
- error = classLabels[randIndex] - h
- weights = weights + alpha * error * dataMatrix[randIndex]
- del[dataIndex[randIndex]]
- return weights
#改进的随机梯度上升算法
def stocGradAscent1(dataMatrix, classLabels, numInter = 150):
dataMatrix = array(dataMatrix)
m,n = shape(dataMatrix)
weights = ones(n)
for j in range(numInter):
dataIndex = range(m)
for i in range(m):
alpha = 4 / (1.0+j+i) + 0.01 #alpha值每次迭代时都进行调整
randIndex = int(random.uniform(0, len(dataIndex))) #随机选取更新
h = sigmoid(sum(dataMatrix[randIndex] * weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del[dataIndex[randIndex]]
return weights

注意:主要做了三个方面的改进:<1>alpha在每次迭代的时候都会调整,这会缓解数据波动或者高频波动。<2>通过随机选取样本来更新回归系数,这样可以减少周期性波动<3>增加了一个迭代参数
3:案例—从疝气病症预测病马的死亡率
(1) 处理数据中缺失值方法:

但是对于类别标签丢失的数据,我们只能采用将该数据丢弃。
(2) 案例代码
- #案例-从疝气病症预测病马的死亡率
- def classifyVector(inX, weights):
- prob = sigmoid(sum(inX*weights))
- if prob > 0.5: return 1.0
- else: return 0.0
- def colicTest():
- frTrain = open(’horseColicTraining.txt’)
- frTest = open(’horseColicTest.txt’)
- trainingSet = []; trainingLabels = []
- for line in frTrain.readlines():
- currLine = line.strip().split(’\t’)
- lineArr =[]
- for i in range(21):
- lineArr.append(float(currLine[i]))
- trainingSet.append(lineArr)
- trainingLabels.append(float(currLine[21]))
- trainWeights = stocGradAscent1(trainingSet, trainingLabels, 500)
- errorCount = 0; numTestVec = 0.0
- for line in frTest.readlines():
- numTestVec += 1.0
- currLine = line.strip().split(’\t’)
- lineArr = []
- for i in range(21):
- lineArr.append(float(currLine[i]))
- if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[21]):
- errorCount += 1
- errorRate = (float(errorCount)/numTestVec)
- print ‘the error rate of this test is: %f’ % errorRate
- return errorRate
- def multiTest():
- numTests = 10;errorSum = 0.0
- for k in range(numTests):
- errorSum += colicTest()
- print ‘after %d iterations the average error rate is: %f’ %(numTests, errorSum/float(numTests))
#案例-从疝气病症预测病马的死亡率
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
def colicTest():
frTrain = open('horseColicTraining.txt')
frTest = open('horseColicTest.txt')
trainingSet = []; trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
trainWeights = stocGradAscent1(trainingSet, trainingLabels, 500)
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr = []
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
print 'the error rate of this test is: %f' % errorRate
return errorRate
def multiTest():
numTests = 10;errorSum = 0.0
for k in range(numTests):
errorSum += colicTest()
print 'after %d iterations the average error rate is: %f' %(numTests, errorSum/float(numTests))

4:总结
Logistic回归的目的是寻找一个非线性函数sigmoid的最佳拟合参数,求解过程可以由最优化算法来完成。在最优化算法中,最常用的就是梯度上升算法,而梯度上升算法又可以简化为随机梯度上升算法。
随机梯度上升算法和梯度上升算法的效果相当,但占用更少的计算资源。此外,随机梯度是一种在线算法,可以在数据到来时就完成参数的更新,而不需要重新读取整个数据集来进行批处理运算。
注明:1:本笔记来源于书籍<机器学习实战>
2:logRegres.py文件及笔记所用数据在这下载(http://download.csdn.net/detail/lu597203933/7735821).
作者:小村长 出处:http://blog.csdn.net/lu597203933 欢迎转载或分享,但请务必声明文章出处。 (新浪微博:小村长zack, 欢迎交流!)














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









