






编辑 | Happy
首发 | AIWalker
链接 | https://mp.weixin.qq.com/s/JQ5g9yn_OdjR8hi_tWc4jA

arXiv:2305.02126 , cvpr2023 , code , video
本文了一个实时&轻量图像超分方案Bicubic++,它通过下采样模块降低图像分辨率以减少计算量,在网络尾部采用X6上采样进行图像重建,同时还构建了一个三阶段训练方案。在测试集上, 所提方案比Bicubic指标高~1dB,同时推理速度~1.17ms@RTX3090、2.9ms@RTX3070 (注:fp16精度,720p输入,4K输出)。此外,Bicubic++取得了NTRIE2023-RTSR-Track2 X3超分竞赛冠军,也是所有方案中最快的,所提方案与其他轻量化方案的性能对比可参考下图。值得称道的就是,Bicubic++具有与Bicubic相当快的处理速度,故很有机会成为新的工业标准。

评价标准
由于Bicubic++是面向NTIRE2023-RTSR竞赛而设计,在正式介绍方案之前,我们先介绍了一下该竞赛的评价标准。
其中, 分别表示模型与Bicubic上采样的PSNR指标,t表示模型推理耗时(720p->4K)。此外,由于实时性要求,t必须小于30ms。计算公式就比较简单了,详细信息可参考calc_scoring.
def score(psnr, runtime, psnr_interp=31.697655):
diff = max(psnr - psnr_interp)
if diff == 0:
return 0
else:
cte = 0.1
return ((2 ** diff) * 2) / (cte * (runtime ** 0.5))
本文方案

上图给出了本文方案整体架构示意图,基于此,作者进行参数微调并尝试了不同的训练策略对最大化上述指标。
架构设计
在架构设计过程中,我们发现: 网络的速度并不直接依赖于参数量,而是与Activation相关。因此,更低分辨率的特征可以极大的降低Activation。此外,已有研究表明: 当与上采样操作协同学习时,下采样操作具有正向影响。因此,作者选择先采用stride卷积下采样,然后采用X6上采样以加速网络推理。在某种意义上讲,更低分辨率的特征提取可以认为是一种在空间上数据压缩方式,由于它与上采样协同训练,故该压缩是可逆的。
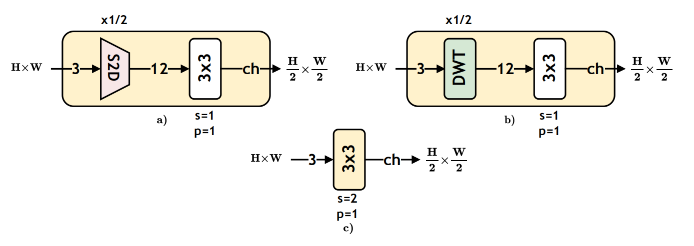
除了上面作者提到的stride卷积进行下采样外,作者还尝试了上图所提到的降采样方案,如Depth2Space、DWT。经综合考量后,最终选型stride卷积。
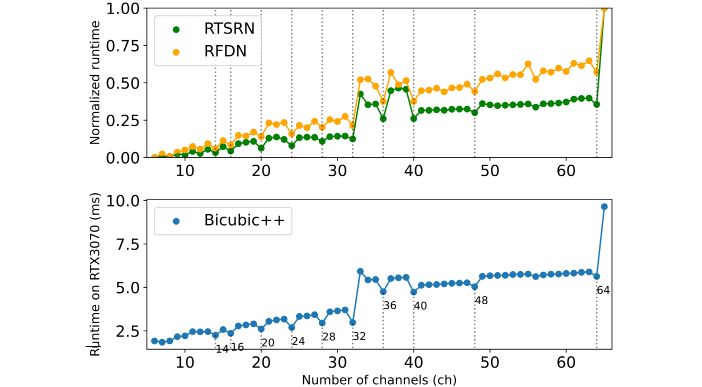
在网络结构方面,我们期望采用了最优的通道数以最大化模型推理速度。我们观测到:通道数与推理延迟并非严格的线性关系,见上图。由于可变通道数导致的延迟提升超过了其性能提升,我们决定网络通道数设置为相同通道数。结合上图同时保持算法实时性,作者将模型通道数设置为32。需要注意的是:为了得到最终的模型,作者以非最优通道数(34)模型开始,然后采用全局剪枝得到通道数为32的模型。
除此之外,作者注意到:卷积的bias项被忽视了,它会占据一定比例的整体延迟。因移除bias而导致的延迟减少要超越其导致的PSNR微弱降低。因此,作者在最终的模型中移除了bias参数。
上述发现可以概括为如下几点:
-
处理的数据量与推理延迟强相关,而非参数量; -
模块间的通道数变动会降低延迟性能; -
对于硬件来说,通道数与延迟之间存在一些 sweet spots,合理的利用可以一定程度提升模型性能; -
bias会占据一定比例的延迟耗时。
Three-stage Training Pipeline
作者构建了一个三阶段训练范式:
-
Stage1 Slim: 采用更大的通道数进行训练。此时,ch=34, m=2, R=1, DS表示stride卷积。此时所有卷积均带有bias参数。
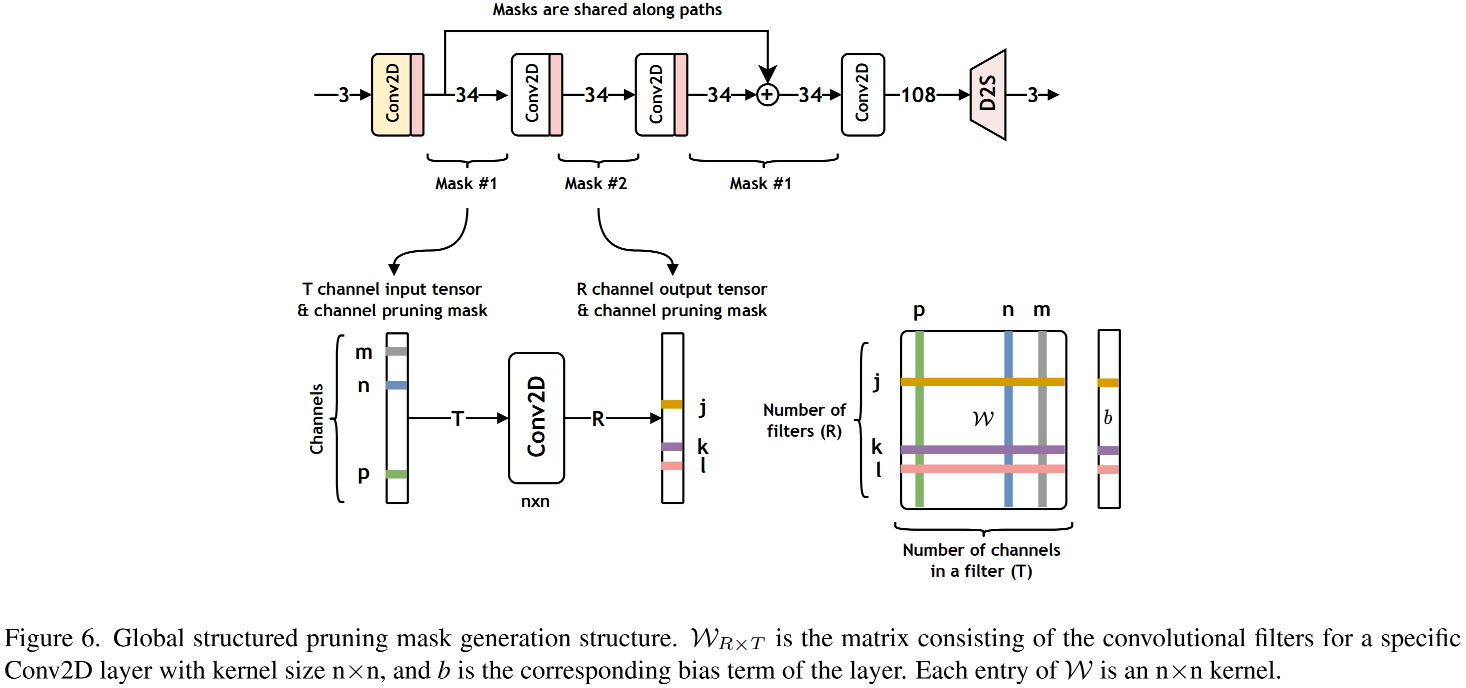
-
Stage2 Slimer: 全局结构化剪枝。基于上一步所得checkpoint参考上图执行全局结构化剪枝。需要注意的是: 此时剪枝准则并非参数大小或拟合程度,而是验证集上的PSNR指标。 -
Stage3 Slimmest: 移除卷积的bias参数项。在经过步骤二后,模型通道数从34减少到了32,加载上一步的checkpoint同时移除bias参数后对整个网络进行再次微调。
训练加速技巧
为尽可能充分利用硬件性能训练如此小的模型,所有的训练流程都需要进行适当调整。这是因为:模型前向与反向过程几乎不怎么耗时,验证集的访存反而会成为实际瓶颈。为加速验证,作者采用48张图进行验证,设置bs为8。考虑到访存瓶颈,作者在训练阶段将训练数据与验证数据均加载到RAM中已减少数据IO。
通过上述调整,1000epoch训练仅需1小时(单个Tesla V100)。此外,由于模型比较小,选择相当小的训练数据(如DIV2K)是可行的,也不会影响验证精度。
本文实验
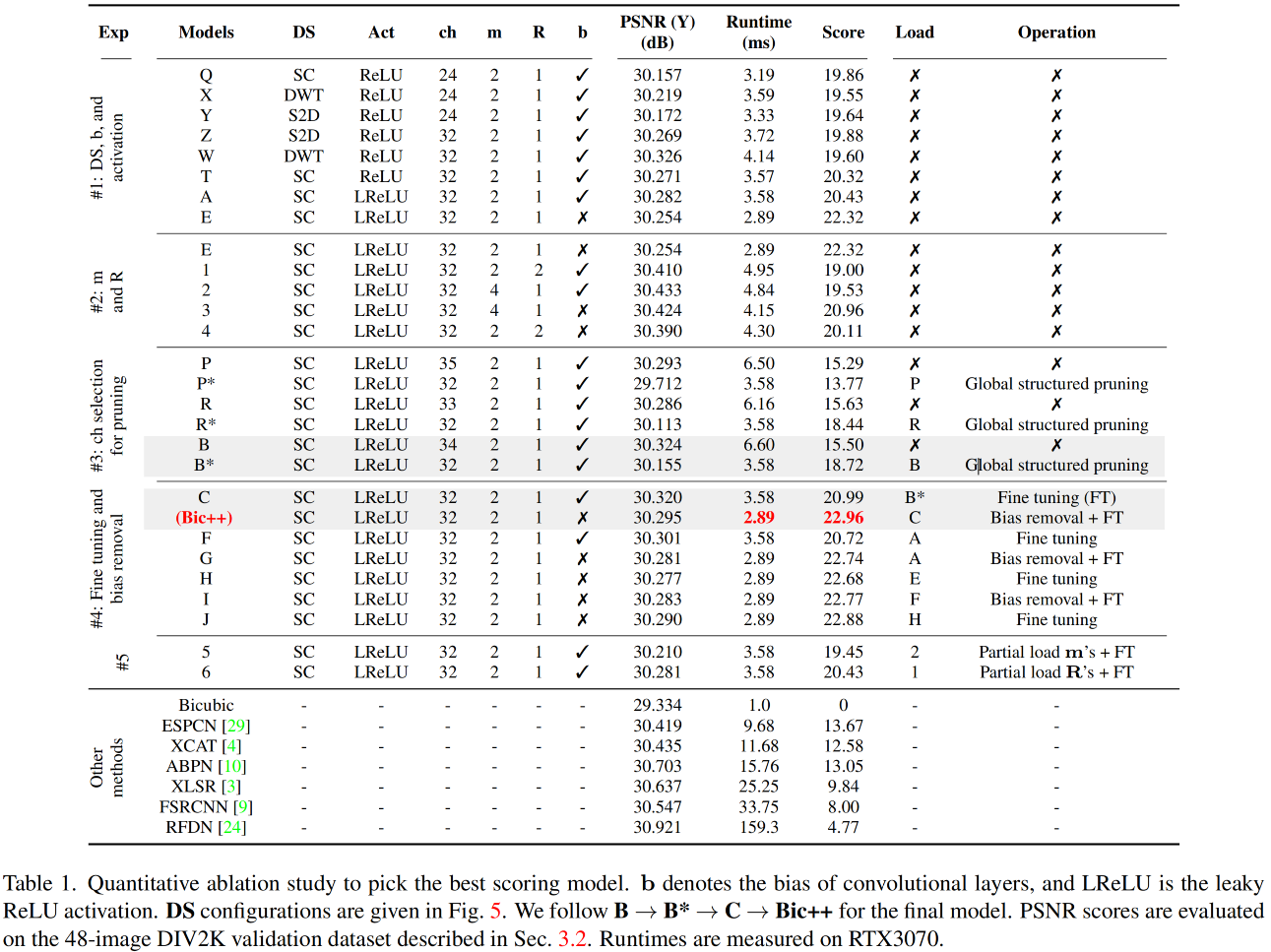
上表从不同维度对所提方案进行了消融分析,简单汇总如下:
-
对比Q-T,可以看到:stride卷积具有更优指标; -
对比T&A,可以看到:相比ReLU,LeakyReLU可以带来明显PSNR提升且耗时几乎不变; -
对比A&E,可以看到:移除bias可以取得更高得分; -
对比1-4&E,可以看到:m=2,R=1可以取得最佳得分; -
对比PRB,可以看到:基于ch=34进行剪枝可以取得最高得分.
此外,为验证所提训练方案的有效性,作者还对比了A->G, E->H, A->F->I, A->E->H->J等不同优化路线。
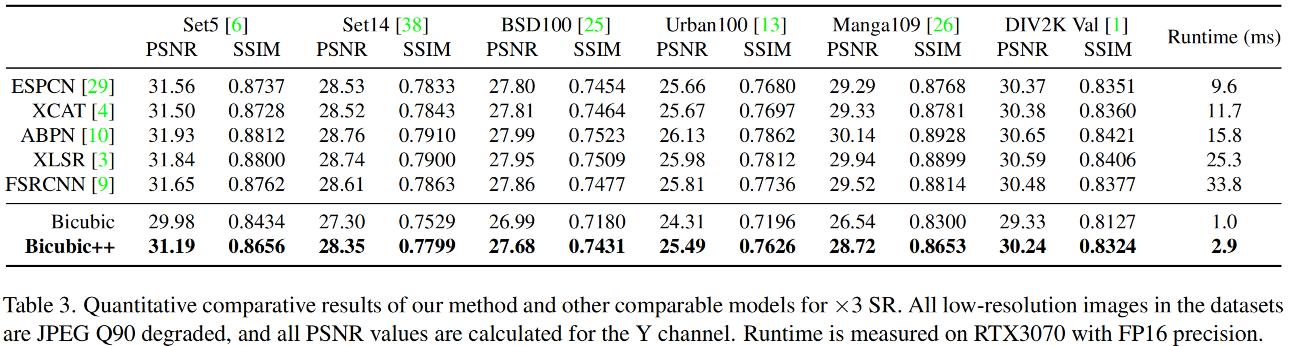

上表&图给出了所提方案同其他典型轻量化方案(如FSRCNN、ESPCN、ABPN、XLSR、SXCAT等)的客观与主观效果对比。
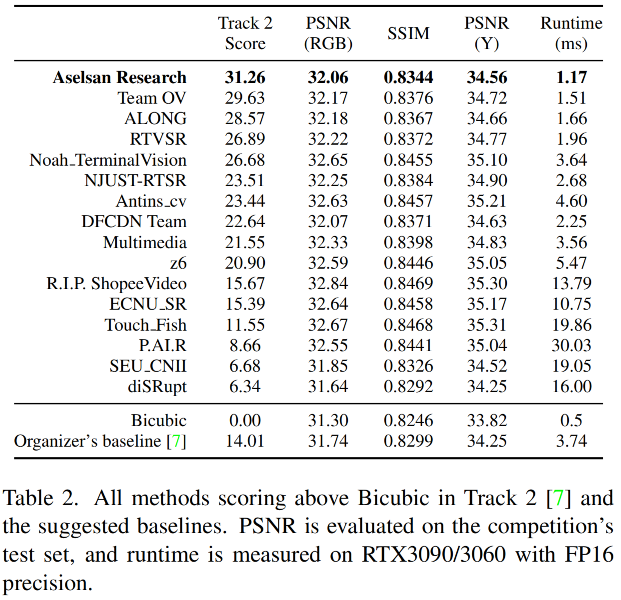

上表&图给出了所提方案在NTIRE2023-RTSR竞赛数据集上的客观指标与主观指标。很明显,Bicubic++以显著优势超过了第二名方案。
推荐阅读
-
ChatGPT聊图像超分,总结确实挺到位,哈哈 -
大核分解与注意力机制的巧妙结合,图像超分多尺度注意网络MAN -
CVPR2023 | 非局部注意力、局部自注意力、样条注意力协同助力图像复原达成新 SOTA! -
NAFNet :无需非线性激活,真“反直觉”!但复原性能也是真强! -
CVPR 2022 Oral | MLP进军底层视觉!谷歌提出MAXIM模型刷榜多个图像处理任务 -
ELAN | 比SwinIR快4倍,图像超分中更高效Transformer应用探索 -
CNN与Transformer相互促进,助力ACT进一步提升超分性能 -
CVPR2022 | Restormer: 刷新多个low-level任务指标 -
Transformer在图像复原领域的降维打击!ETH提出SwinIR:各项任务全面领先
本文由 mdnice 多平台发布
















 1072
1072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











