









 本文介绍了一种名为DistriFusion的方法,通过在多个GPU上并行计算图像补丁,有效解决高分辨率图像生成的计算挑战。通过置换补丁并行性,减少通信开销,实现在8台NVIDIAA100上比单机快6.1倍,同时保持图像质量。
本文介绍了一种名为DistriFusion的方法,通过在多个GPU上并行计算图像补丁,有效解决高分辨率图像生成的计算挑战。通过置换补丁并行性,减少通信开销,实现在8台NVIDIAA100上比单机快6.1倍,同时保持图像质量。

https://arxiv.org/pdf/2402.19481.pdf
https://github.com/mit-han-lab/distrifuser
本文概述
扩散模型在合成高质量图像方面取得了巨大成功。然而,由于巨大的计算成本,利用扩散模型生成高分辨率图像仍然具有挑战性,导致交互式应用程序的延迟过高。在本文中,我们提出DistriFusion通过利用多个 GPU 的并行性来解决这个问题。我们的方法将模型输入拆分为多个块,并将每个块分配给GPU。
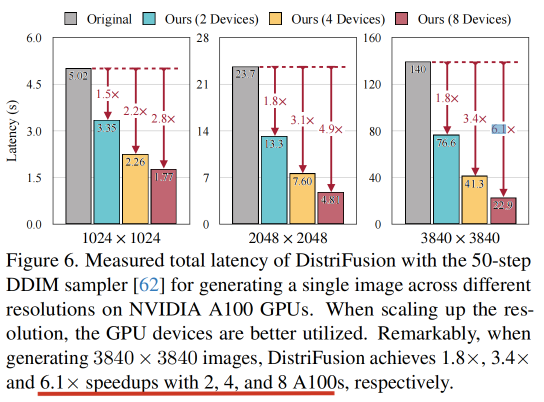
然而,这样的算法最基本实现会破坏补丁之间的交互并失去保真度,而合并这样的交互将产生巨大的通信开销。为了克服这个困境,我们观察到相邻扩散步骤的输入之间的高度相似性,并提出置换补丁并行性,它通过复用前一步计算的特征并利用扩散过程的顺序特性为当前步提供上下文信息。因此,我们的方法支持异步通信,可以通过计算进行管道化。大量实验表明,我们的方法可以应用于最新的 Stable Diffusion XL,且质量不会下降,并且与 1 台相比,8 台 NVIDIA A100 上的速度提升高达 6.1×。

本文方案
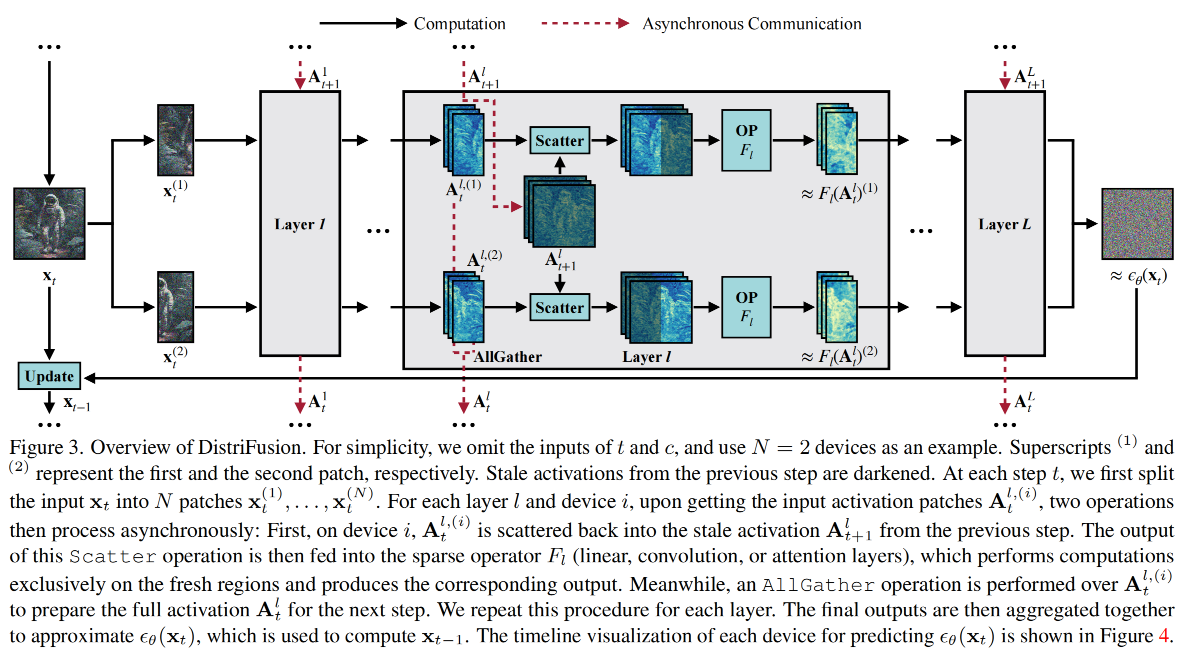
DistriFusion 的关键思想是通过将图像分割成补丁来跨设备并行计算。这可以通过以下两种方式来完成:(1)独立计算补丁并将它们拼接在一起,或者(2)在补丁之间同步通信中间激活。然而,第一种方法会导致每个补丁的边界处出现明显的差异,因为它们之间缺乏相互作用(见图 1 和图 2(b))。另一方面,第二种方法会产生过多的通信开销,从而抵消了并行处理的好处。
为了应对这些挑战,我们提出了一种新的并行范例,即置换补丁并行,它利用扩散模型的顺序性质来重叠通信和计算。我们的主要见解是重用先前扩散步骤中稍微过时或“陈旧”的激活,以促进补丁之间的交互,我们将其描述为激活位移。这是基于连续去噪步骤的输入相对相似的观察。因此,在某一层计算每个补丁的激活不依赖于其他补丁的新激活,从而允许通信隐藏在后续层的计算中。

本文实验


















 4786
4786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











