







EM算法解高斯混合模型Gaussian Mixture Models
假设我们需要调查我们学校的男生和女生的身高分布。在校园里随便地活捉了100个男生和100个女生,他们共200个人(也就是200个身高的样本数据)。
高斯模型
你开始喊:“男的左边,女的右边,其他的站中间!”。然后你就先统计抽样得到的100个男生的身高。假设他们的身高是服从高斯分布N(u,∂)的。但是这个分布的均值u和方差∂2我们不知道,这两个参数就是我们要估计的。记作θ=[u, ∂]T。用数学的语言来说就是:在学校那么多男生(身高)中,我们独立地按照概率密度p(x|θ)(高斯分布N(u,∂)的形式)抽取100了个(身高),组成样本集X,我们想通过样本集X来估计出未知参数θ。抽到的样本集是X={x1,x2,…,xN},其中xi表示抽到的第i个人的身高,这里抽到的样本个数N就是100。用MLE解决的公式:

通过抽取得到的那100个男生的身高和已知其身高服从高斯分布,我们通过最大化其似然函数,就可以得到了对应高斯分布的参数θ=[u, ∂]T了。对于女生的身高分布也可以用同样的方法得到。
高斯混合模型
再回到例子本身,如果没有“男的左边,女的右边,其他的站中间!”这个步骤,或者说我抽到这200个人都戴了面具。那现在这200个人已经混到一起了,这时候,你从这200个人(的身高)里面随便给我指一个人(的身高),我都无法确定这个人(的身高)是男生(的身高)还是女生(的身高)。也就是说你不知道抽取的那200个人里面的每一个人到底是从男生的那个身高分布里面抽取的,还是女生的那个身高分布抽取的。用数学的语言就是,抽取得到的每个样本都不知道是从哪个分布抽取的。这个时候,对于每一个样本或者你抽取到的人,就有两个东西需要猜测或者估计的了,一是这个人是男的还是女的?二是男生和女生对应的身高的高斯分布的参数是多少? 只有当我们知道了哪些人属于同一个高斯分布的时候,我们才能够对这个分布的参数作出靠谱的预测。只有当我们对这两个分布的参数作出了准确的估计的时候,才能知道到底哪些人属于第一个分布,那些人属于第二个分布。
为了解决这个你依赖我,我依赖你的循环依赖问题,总得有一方要先打破僵局,先随便整一个值出来,然后我再根据你的变化调整我的变化,然后如此迭代着不断互相推导,最终就会收敛到一个解。
EM解高斯混合模型
在我们上面这个问题里面,我们是先随便猜一下男生(身高)的正态分布的参数:如均值和方差是多少。例如男生的均值是1米7,方差是0.1米(当然了,刚开始肯定没那么准),然后计算出每个人更可能属于第一个还是第二个正态分布中的(lz某个身高值代入男生和女生的高斯分布中,选择概率大的作为其所在分布),这个是属于Expectation一步。
有了每个人的归属,已经大概地按上面的方法将这200个人分为男生和女生两部分,我们就可以根据之前说的最大似然那样,通过这些被大概分为男生的n个人来重新估计第一个分布的参数,女生的那个分布同样方法重新估计。这个是Maximization。
然后,当我们更新了这两个分布的时候,每一个属于这两个分布的概率又变了,那么我们就再需要调整E步……如此往复,直到参数基本不再发生变化为止。
这里把每个人(样本)的完整描述看做是三元组yi={xi,zi1,zi2},其中,xi是第i个样本的观测值,对应身高,可观测值。zi1和zi2表示男生和女生这两个高斯分布中哪个被用来产生值xi,就是说这两个值标记这个人到底是男生还是女生(的身高分布产生的)。这两个值我们是不知道的,是隐含变量。确切的说,zij在xi由第j个高斯分布产生时值为1,否则为0。例如一个样本的观测值为1.8,然后他来自男生的那个高斯分布,那么我们可以将这个样本表示为{1.8, 1, 0}。如果zi1和zi2的值已知,也就是说每个人我已经标记为男生或者女生了,那么我们就可以利用上面说的最大似然算法来估计他们各自高斯分布的参数。但是它们未知,因此我们只能用EM算法。
假设已经知道这个隐含变量了,那么直接按上面说的最大似然估计求解那个分布的参数就好了。我们可以先给这个分布弄一个初始值,然后求这个隐含变量的期望,当成是这个隐含变量的已知值,那么现在就可以用最大似然求解那个分布的参数了吧,那假设这个参数比之前的那个随机的参数要好,它更能表达真实的分布,那么我们再通过这个参数确定的分布去求这个隐含变量的期望,然后再最大化,得到另一个更优的参数,……迭代,就能得到一个皆大欢喜的结果了。
迭代时咋知道新的参数的估计就比原来的好啊?这些问题在数学上是可以稳当的证明的。
[Mitchell的Machine Learning书中一个EM应用的例子]
EM算法
Jensen不等式
凸函数:优化理论中,设f是定义域为实数的函数,如果对于所有的实数x, ,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的(
,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的(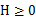 ),那么f是凸函数。如果
),那么f是凸函数。如果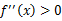 或者
或者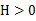 ,那么称f是严格凸函数。 当f是(严格)凹函数当且仅当-f是(严格)凸函数。比如
,那么称f是严格凸函数。 当f是(严格)凹函数当且仅当-f是(严格)凸函数。比如 是凹函数。
是凹函数。
Note: lz发现好多地方凸函数定义可能是相反的,国内外定义好像也不一样。这里只要记得,正常的碗就是凸函数!
Jensen不等式:如果f是凸函数,X是随机变量,那么 。特别地,如果f是严格凸函数,那么
。特别地,如果f是严格凸函数,那么 当且仅当
当且仅当 ,也就是说X是常量。Jensen不等式应用于凹函数时,不等号方向反向,也就是
,也就是说X是常量。Jensen不等式应用于凹函数时,不等号方向反向,也就是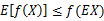 。
。
这里我们将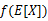 简写为
简写为 。
。
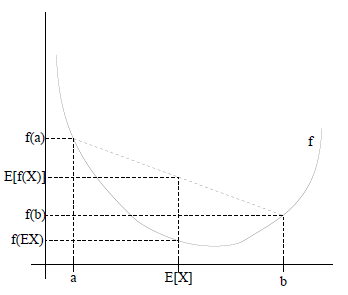
图中,实线f是凸函数,X是随机变量,有0.5的概率是a,有0.5的概率是b。(就像掷硬币一样)。X的期望值就是a和b的中值了,图中可以看到![clip_image010[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061615563561.png) 成立。
成立。
EM算法
EM问题描述
给定的训练样本是 ,样例间独立,我们想找到每个样例隐含的类别z,能使得p(x,z)最大。
,样例间独立,我们想找到每个样例隐含的类别z,能使得p(x,z)最大。
p(x,z)的最大似然估计如下:

第一步是对极大似然取对数,第二步是对每个样例的每个可能类别z求联合分布概率和。但是直接求θ一般比较困难,因为有隐藏变量z存在,但是一般确定了z后,求解就容易了。竟然不能直接最大化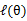 ,我们可以不断地建立
,我们可以不断地建立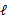 的下界(E步),然后优化下界(M步)[E步固定
的下界(E步),然后优化下界(M步)[E步固定
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}