







分类目录:《深入理解深度学习》总目录
相关文章:
·注意力机制(AttentionMechanism):基础知识
·注意力机制(AttentionMechanism):注意力汇聚与Nadaraya-Watson核回归
·注意力机制(AttentionMechanism):注意力评分函数(AttentionScoringFunction)
·注意力机制(AttentionMechanism):Bahdanau注意力
·注意力机制(AttentionMechanism):自注意力(Self-attention)
·注意力机制(AttentionMechanism):多头注意力(MultiheadAttention)
·注意力机制(AttentionMechanism):位置编码(PositionalEncoding)
在《深入理解深度学习——注意力机制(Attention Mechanism):自注意力(Self-attention)》中,我们为了运行自注意力机制,我们需要创建三个新矩阵,即查询矩阵 Q Q Q、键矩阵 K K K和值矩阵 V V V。由于使用了《深入理解深度学习——注意力机制(Attention Mechanism):多头注意力(Multi-head Attention)》中的多头注意力层,因此我们创建了 h h h个查询矩阵、键矩阵和值矩阵。对于注意力头 i i i的查询矩阵 Q i Q_i Qi、键矩阵 K i K_i Ki和值矩阵 V i V_i Vi,可以通过将 X X X分别乘以权重矩阵 W i q W^q_i Wiq、 W i k W^k_i Wik、 W i v W^v_i Wiv而得。
下面,让我们看看带掩码的多头注意力层是如何工作的。假设传给解码器的输入句是<sos>Je vais bien。我们知道,自注意力机制将一个单词与句子中的所有单词联系起来,从而提取每个词的更多信息。但这里有一个小问题。在测试期间,解码器只将上一步生成的词作为输入。比如,在测试期间,当
t
=
2
t=2
t=2时,解码器的输入中只有[<sos>,Je],并没有任何其他词。因此,我们也需要以同样的方式来训练模型。模型的注意力机制应该只与该词之前的单词有关,而不是其后的单词。要做到这一点,我们可以掩盖后边所有还没有被模型预测的词。比如,我们想预测与<sos>相邻的单词。在这种情况下,模型应该只看到<sos>,所以我们应该掩盖<sos>后边的所有词。再比如,我们想预测Je后边的词。在这种情况下,模型应该只看到Je之前的词,所以我们应该掩盖Je后边的所有词。其他行同理,如下图所示。

像这样的掩码有助于自注意力机制只注意模型在测试期间可以使用的词。对于一个注意力头
i
i
i的注意力矩阵
Z
i
Z_i
Zi的计算方法:
Z
i
=
Softmax
(
Q
i
K
i
T
d
k
)
V
i
Z_i=\text{Softmax}(\frac{Q_iK^T_i}{\sqrt{d_k}})V_i
Zi=Softmax(dkQiKiT)Vi
需要计算带掩码的多头注意力,主要有以下几步:
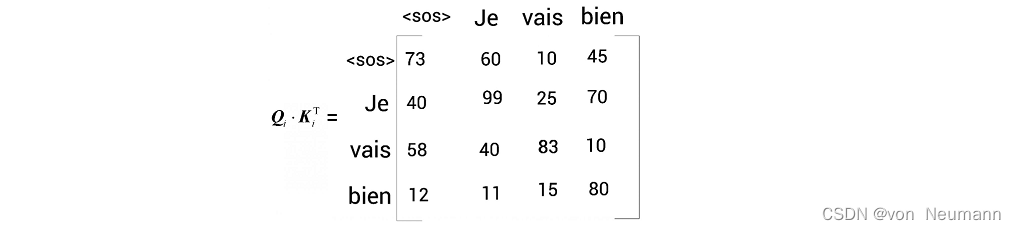
- 计算查询矩阵与键矩阵的点积。下图显示了点积结果。需要注意的是,这里使用的数值是随机的,只是为了方便理解。
- 将
Q
i
K
i
T
Q_iK^T_i
QiKiT矩阵除以键向量维度的平方根
d
k
\sqrt{d_k}
dk,假设下图是
Q
i
K
i
T
d
k
\frac{Q_iK^T_i}{\sqrt{d_k}}
dkQiKiT的结果:

- 我们对上图所得的矩阵应用Softmax函数,并将分值归一化。但在应用Softmax函数之前,我们需要对数值进行掩码转换。以矩阵的第1行为例,为了预测
<sos>后边的词,模型不应该知道<sos>右边的所有词(因为在测试时不会有这些词)。因此,如下图所示,对于第1行我们可以用 − ∞ -\infty −∞掩盖<sos>右边的所有词,第2行用 − ∞ -\infty −∞掩盖Je右边的所有词,以此类推。![[插图]掩盖右边的所有词](https://i-blog.csdnimg.cn/blog_migrate/05cbe766ce4684539c6fd48a6a74696e.png)
现在,我们可以将Softmax函数应用于前面的矩阵,并将结果与值矩阵
V
i
V_i
Vi相乘,得到最终的注意力矩阵
Z
i
Z_i
Zi。同样,我们可以计算
h
h
h个注意力矩阵,将它们串联起来,并将结果乘以新的权重矩阵
W
0
W_0
W0,即可得到最终的注意力矩阵
M
M
M:
M
=
Concatenate
(
Z
1
.
Z
2
,
⋯
.
Z
h
)
W
0
M=\text{Concatenate}(Z_1. Z_2, \cdots. Z_h)W_0
M=Concatenate(Z1.Z2,⋯.Zh)W0
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] 车万翔, 崔一鸣, 郭江. 自然语言处理:基于预训练模型的方法[M]. 电子工业出版社, 2021.
[4] 邵浩, 刘一烽. 预训练语言模型[M]. 电子工业出版社, 2021.
[5] 何晗. 自然语言处理入门[M]. 人民邮电出版社, 2019
[6] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023
[7] 吴茂贵, 王红星. 深入浅出Embedding:原理解析与应用实战[M]. 机械工业出版社, 2021.



















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











