







 本文对比了强化学习与有监督学习,强调强化学习中的试错探索、延迟奖励、目标导向交互和时间关联数据的特点,以及智能体如何在没有即时反馈的环境下学习。
本文对比了强化学习与有监督学习,强调强化学习中的试错探索、延迟奖励、目标导向交互和时间关联数据的特点,以及智能体如何在没有即时反馈的环境下学习。
分类目录:《深入理解强化学习》总目录
通过前文的介绍,我们现在应该已经对强化学习的基本数学概念有了一定的了解。这里我们回过头来再看看一般的有监督学习和强化学习的区别。以图片分类为例,有监督学习(Supervised Learning)假设我们有大量被标注的数据且通常假设样本空间中全体样本服从一个未知分布,我们获得的每个样本都是独立地从这个分布上采样获得的,即独立同分布(Independent and Identically Distributed,IID),比如汽车、飞机、椅子这些被标注的图片,这些图片都要满足独立同分布,即它们之间是没有关联关系的。假设我们训练一个分类器,比如神经网络。为了分辨输入的图片中是汽车还是飞机,在训练过程中,需要把正确的标签信息传递给神经网络。 当神经网络做出错误的预测时,比如输入汽车的图片,它预测出来是飞机,我们就会直接告诉它,该预测是错误的,正确的标签应该是汽车。最后我们根据类似错误写出一个损失函数(Loss Function),通过反向传播(Back Propagation)来训练神经网络。所以在监督学习过程中,有两个假设:
- 输入的数据(标注的数据)都应是没有关联的。因为如果输入的数据有关联,学习器是不好学习的
- 需要告诉学习器正确的标签是什么,这样它可以通过正确的标签来修正自己的预测
在强化学习中,有监督学习的两个假设其实都不能得到满足。以雅达利(Atari) 游戏Breakout为例,如下图所示,这是一个打砖块的游戏,控制木板左右移动从而把球反弹到上面来消除砖块。在玩游戏的过程中,我们可以发现智能体得到的观测(Observation)不是独立同分布的,上一帧与下一帧间其实有非常强的连续性。我们得到的数据是相关的时间序列数据,不满足独立同分布。另外,我们并没有立刻获得反馈,游戏没有告诉我们哪个动作是正确动作。比如现在把木板往右移,这只会使得球往上或者往左一点儿,我们并不会得到即时的反馈。因此,强化学习之所以困难,是因为智能体不能得到即时的反馈,然而我们依然希望智能体在这个环境中学习。

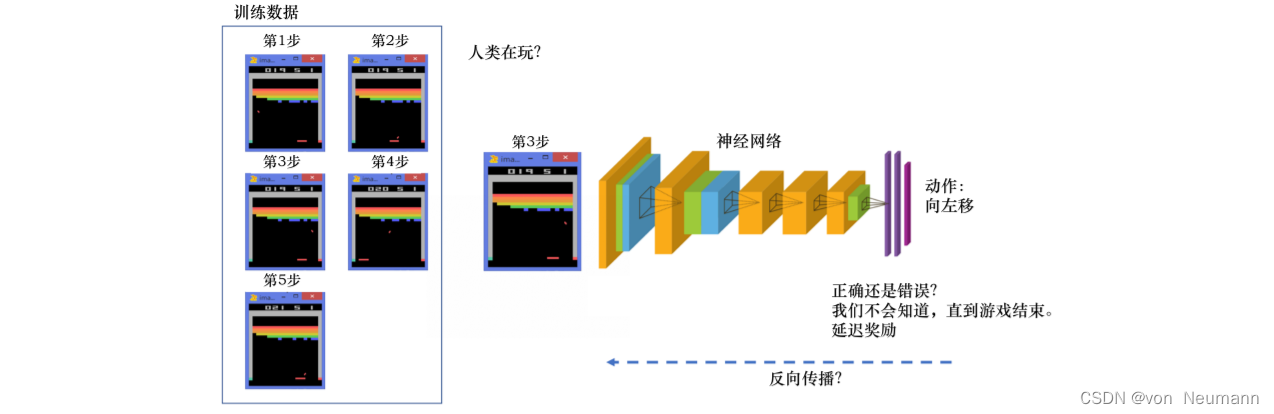
如下图所示,强化学习的训练数据就是一个玩游戏的过程。我们从第1步开始,采取一个动作,比如我们把木板往右移,接到球。第2步我们又做出动作,得到的训练数据是一个玩游戏的序列。比如现在是在第3步,我们把这个序列放进网络,希望网络可以输出一个动作,即在当前的状态应该输出往右移或者往左移。这里有个问题,我们没有标签来说明现在这个动作是正确还是错误的,必须等到游戏结束才可能知道,这个游戏可能10s后才结束。现在这个动作到底对最后游戏是否能赢有无帮助,我们其实是不清楚的。这里我们就面临延迟奖励(Delayed Reward)的问题,延迟奖励使得训练网络非常困难。
对于一般的有监督学习任务,我们的目标是找到一个最优的模型函数,使其在训练数据集上最小化一个给定的损失函数。在训练数据独立同分布的假设下,这个优化目标表示最小化模型在整个数据分布上的泛化误差(Generalization Error),用简要的公式可以概括为:
最优模型
=
arg
min
模型
E
(
特征
,
标签
)
∼
数据分布
[
损失函数
(
标签
,
模型
(
特征
)
)
]
\text{最优模型}=\arg\min_{\text{模型}} E_{(\text{特征}, \text{标签})\sim \text{数据分布}}[\text{损失函数}(\text{标签}, \text{模型}(\text{特征}))]
最优模型=arg模型minE(特征,标签)∼数据分布[损失函数(标签,模型(特征))]
相比之下,强化学习任务的最终优化目标是最大化智能体策略在和动态环境交互过程中的价值。根据上面的分析,策略的价值可以等价转换成奖励函数在策略的占用度量上的期望:
最优策略
=
arg
max
策略
E
(
状态
,
动作
)
∼
策略占用度量
[
奖励函数
(
状态
,
动作
)
]
\text{最优策略}=\arg\max_{\text{策略}} E_{(\text{状态}, \text{动作})\sim \text{策略占用度量}}[\text{奖励函数}(\text{状态}, \text{动作})]
最优策略=arg策略maxE(状态,动作)∼策略占用度量[奖励函数(状态,动作)]
观察以上两个优化公式,我们可以总结出两者的相似点和不同点:
- 有监督学习和强化学习的优化目标相似,即都是在优化某个数据分布下的一个分数值的期望。
- 二者优化的途径是不同的,有监督学习直接通过优化模型对于数据特征的输出来优化目标,即修改目标函数而数据分布不变;强化学习则通过改变策略来调整智能体和环境交互数据的分布,进而优化目标,即修改数据分布而目标函数不变。
综上所述,一般有监督学习和强化学习的范式之间的区别为:
- 有监督学习关注寻找一个模型,使其在给定数据分布下得到的损失函数的期望最小。而强化学习关注寻找一个智能体策略,使其在与动态环境交互的过程中产生最优的数据分布,即最大化该分布下一个给定奖励函数的期望。
- 强化学习输入的样本是序列数据,而不像监督学习里面样本都是独立的。
- 学习器并没有告诉我们每一步正确的动作应该是什么,学习器需要自己去发现哪些动作可以带来最多的奖励,只能通过不停地尝试来发现最有利的动作。
- 智能体获得自己能力的过程,其实是不断地试错探索(Trial-and-error Exploration)的过程。探索 (Exploration)和利用(Exploitation)是强化学习里面非常核心的问题。其中,探索指尝试一些新的动作, 这些新的动作有可能会使我们得到更多的奖励,也有可能使我们“一无所有”,而利用指采取已知的可以获得最多奖励的动作,重复执行这个动作,因为我们知道这样做可以获得一定的奖励。因此,我们需要在探索和利用之间进行权衡,这也是在监督学习里面没有的情况。
- 在强化学习过程中,没有非常强的监督者(Supervisor),只有奖励信号(Reward Signal),并且奖励信号是延迟的,即环境会在很久以后告诉我们之前我们采取的动作到底是不是有效的。因为我们没有得到即时反馈,所以智能体使用强化学习来学习就非常困难。当我们采取一个动作后,如果我们使用监督学习,我们就可以立刻获得一个指导,比如,我们现在采取了一个错误的动作,正确的动作应该是什么。而在强化学习里面,环境可能会告诉我们这个动作是错误的,但是它并没有告诉我们正确的动作是什么。而且更困难的是,它可能是在一两分钟过后告诉我们这个动作是错误的。所以这也是强化学习和监督学习不同的地方。
通过与监督学习的比较,我们可以总结出强化学习的一些特征:
- 强化学习会试错探索,它通过探索环境来获取对环境的理解。
- 强化学习智能体会从环境里面获得延迟的奖励。
- 在强化学习的训练过程中,时间非常重要,因为我们得到的是有时间关联的数据(Sequential Data), 而不是独立同分布的数据。在机器学习中,如果观测数据有非常强的关联,会使得训练非常不稳定。这也是为什么在监督学习中,我们希望数据尽量满足独立同分布,这样就可以消除数据之间的相关性。
- 智能体的动作会影响它随后得到的数据,这一点是非常重要的。在训练智能体的过程中,很多时 候我们也是通过正在学习的智能体与环境交互来得到数据的。所以如果在训练过程中,智能体不能保持稳定,就会使我们采集到的数据非常糟糕。我们通过数据来训练智能体,如果数据有问题,整个训练过程就会失败。所以在强化学习里面一个非常重要的问题就是,怎么让智能体的动作一直稳定地提升。
本文梳理了强化学习和有监督学习在范式以及思维方式上的相似点和不同点。在大多数情况下,强化学习任务往往比一般的有监督学习任务更难,因为一旦策略有所改变,其交互产生的数据分布也会随之改变,并且这样的改变是高度复杂、不可追踪的,往往不能用显式的数学公式刻画。这就好像一个混沌系统,我们无法得到其中一个初始设置对应的最终状态分布,而一般的有监督学习任务并没有这样的混沌效应。
综上所述,强化学习带来了一个独有的挑战“试探"与“开发”之间的折中权衡。为了获得大量的收益,强化学习智能体一定会更喜欢那些在过去为它有效产生过收益的动作。但为了发现这些动作,往往需要尝试从未选择过的动作。智能体必须开发已有的经验来获取收益,同时也要进行试探,使得未来可以获得更好的动作选择空间。于是两难情况产生了:无论是试探还是开发,都不能在完全没有失败的情况下进行。智能体必须尝试各种各样的动作,并且逐渐地筛选出那些最好的动作。在一个随机任务中,为了获得对收益期望的可靠估计,需要对每个动作多次尝试。这个“试探.开发”困境问题已经被数学家们深人研究了几十年,但是仍然没有解决。而就目前而言,在有监督学习和无监督学习中,至少在最简单的形式中,并不存在权衡试探和开发的问题。
强化学习的另一个关键特征是它明确地考虑了目标导向的智能体与不确定的环境交互这整个问题。而很多其他方法都是只考虑子问题,而忽视了子问题在更大情境下的适用性。举个例子,我们之前提到过机器学习的很多研究都与有监督学习有关,而没有明确说这个关系是如何发挥其作用的。其他研究人员也已经研究过针对总体目标的规划理论,但没有考虑规划在实时决策中的作用,也没有考虑规划所需的预测模型将从何而来。尽管这些方法也产生了许多有用的结果,但是它们的一个明显的局限性就是仅仅关注孤立的子问题。强化学习则从一个完整的、交互式的、目标导向的智能体出发,采取了相反的思路。所有强化学习的智能体都有一个明确的目标,即能够感知环境的各个方面,并可以选择动作来影响它们所处的环境。此外,通常规定智能体从最开始就要工作,尽管其面对的环境具有很大的不确定性。当强化学习涉及规划时,它必须处理规划和实时动作选择之间的相互影响,以及如何获取和改善环境模型的问题。当强化学习涉及有监督学习时,往往有某些特定因素可以决定对于智能体来说哪些能力是重要的,哪些不是。这时,如果要想有效地进行学习算法的研究,我们必须对重要的子问题进行单独的考虑和研究。但这些子问题必须在完整的、交互式的、目标驱动的智能体问题框架中具有明确而清晰的角色定义,即使完整智能体的各种细节暂时还不知道。
我们所提到的完整的、交互式的、目标导向的智能体并不一定是完整的有机体或机器人。这些是简单的例子,但是它们也可以是一个更大的动作系统的组成部分。在这种情况下,智能体直接与这个系统的其他部分进行交互,并间接地与系统的环境交互。一个很简单的例子就是智能体监控机器人电池的电量,并且将指令发送到机器人的控制模块去。这个智能体所处的环境就是这个机器人除电池电量以外的其他部分,以及这个机器人所处的自然环境。除了最显然的案例中的智能体及其环境外,我们还应该看得更远,从而理解强化学习框架的普遍性。
参考文献:
[1] 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 人民邮电出版社, 2022.
[2] Richard S. Sutton, Andrew G. Barto. 强化学习(第2版)[M]. 电子工业出版社, 2019
[3] Maxim Lapan. 深度强化学习实践(原书第2版)[M]. 北京华章图文信息有限公司, 2021
[4] 王琦, 杨毅远, 江季. Easy RL:强化学习教程 [M]. 人民邮电出版社, 2022


















 3149
3149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











