







 超级会员免费看
超级会员免费看
 本文介绍了如何使用spaCy开发信息提取(IE)管道,并将结果存储到Neo4j数据库中,涉及共指消解、关系抽取等步骤。作者展示了如何将spaCy的组件整合到管道中,利用Rebel模型进行关系提取,并通过WikiData API进行实体链接。最终,将提取的数据存储为图形数据,以利于后续分析。
本文介绍了如何使用spaCy开发信息提取(IE)管道,并将结果存储到Neo4j数据库中,涉及共指消解、关系抽取等步骤。作者展示了如何将spaCy的组件整合到管道中,利用Rebel模型进行关系提取,并通过WikiData API进行实体链接。最终,将提取的数据存储为图形数据,以利于后续分析。
了解如何使用 spaCy 实施定制的信息提取管道并将结果存储在 Neo4j 中
自从我第一次涉足自然语言处理以来,信息提取 (IE) 管道在我心中占有特殊的位置。信息提取 (IE) 管道从文本等非结构化数据中提取结构化数据。互联网以各种文章和其他内容格式的形式提供了大量信息。然而,虽然您可能会阅读新闻或订阅多个播客,但实际上不可能跟踪每天发布的所有新信息。即使您可以手动阅读所有最新的报告和文章,构建数据以便您可以使用您喜欢的工具轻松查询和汇总数据,也将是极其繁琐和劳动密集型的。我绝对不想把那当作我的工作。幸运的是,
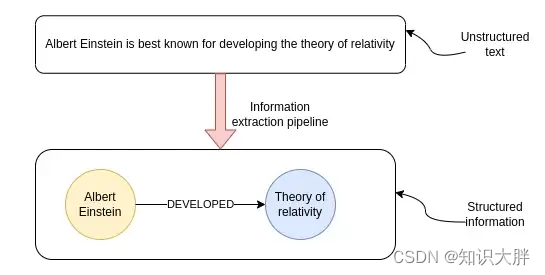
虽然我已经实现并撰写了有关 IE 管道的文章,但我注意到开源 NLP 模型的许多新进展,尤其是围绕spaCy的进展。后来我了解到,我将在这篇文章中使用的大多数模型都被简单地包装为一个 spaCy 组件,如果你愿意,你可以使用其他库。然而,由于 spaCy 是我使用过的第一个 NLP 库,我决定在 spaCy 中实现 IE 管道,以此来感谢开发人员制作了如此出色且易于上手的工具。
随着时间的推移,我对 IE 管道中的步骤的看法一直保持不变。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2774
2774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











