







 该专栏为热销专栏榜 第88名
该专栏为热销专栏榜 第88名 本文介绍如何使用 Python-pptx 和 Llama-3 语言模型自动化创建 PowerPoint 演示文稿。通过RAG管道,从CFA考试书籍中提取信息,经过预处理后,利用Groq的llama-3模型生成结构化内容,并通过Pydantic构建提示,最终输出可执行的python-pptx代码创建幻灯片。
本文介绍如何使用 Python-pptx 和 Llama-3 语言模型自动化创建 PowerPoint 演示文稿。通过RAG管道,从CFA考试书籍中提取信息,经过预处理后,利用Groq的llama-3模型生成结构化内容,并通过Pydantic构建提示,最终输出可执行的python-pptx代码创建幻灯片。

在企业界,幻灯片随处可见,它常常被用来传达想法和成果。我个人过去 4 年一直在大型跨国公司工作,制作幻灯片是大多数人每周都会做的事情。
如果幻灯片可以有效利用时间,那就不会是一个大问题。很多人会反对这一点,但在我看来,大多数公司的幻灯片都占用了太多时间。员工本可以利用这些时间实际执行项目和构建内容。
RAG 管道
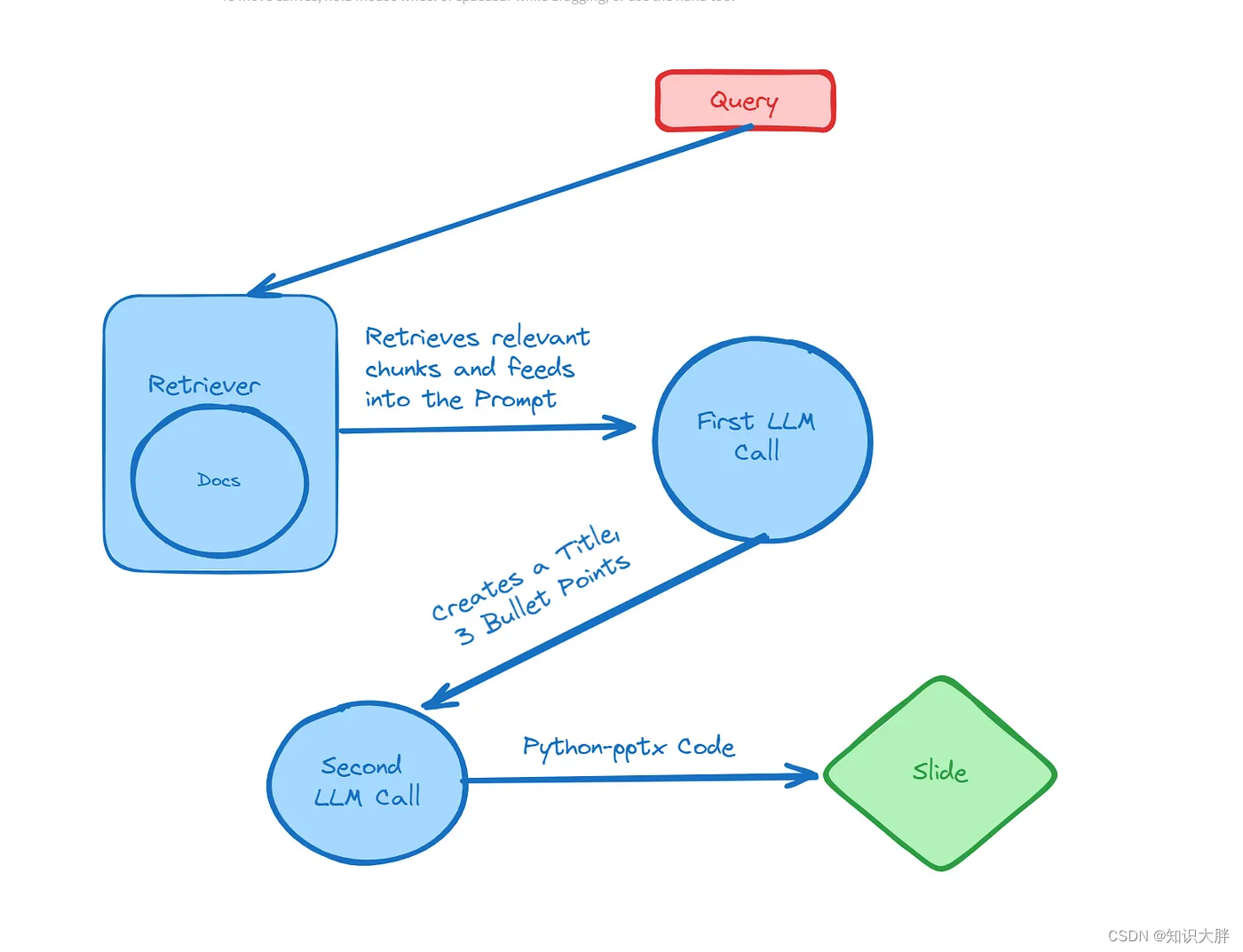
Python 有一个名为 Python-pptx 的库,允许用户以编程方式创建 PowerPoint 演示文稿。促使大型语言模型使用这个库并生成可执行代码将是第一步。
在这个管道中,我们将获取一个信息集,在本例中是一本关于 CFA 考试的书。此练习的最终目标是加载页面、提取文本并使用 LLM 生成为页面创建幻灯片的代码。
from llama_index.core import SimpleDirectoryReader
#you can use any PDF/text document for this excercise
reader
 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1614
1614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











