







简介
对于一直关注人工智能和机器学习快速发展的人来说,新硬件的发布总是备受期待。每一代新处理器和加速器都有可能极大地改变我们开发和部署大规模机器学习模型的方式。NVIDIA 长期处于人工智能硬件开发的最前沿,它再次凭借由 Blackwell 架构驱动的 B200 提高了标准。
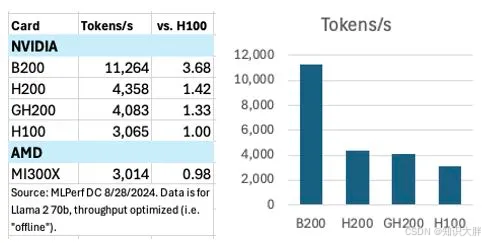
最近的 MLPerf 基准测试提供了 B200 的首批可靠数据,结果非常出色。在 Llama 2 70B 型号上运行推理时,B200 每秒可处理 11,264 个令牌,性能是 NVIDIA H100 的 3.7 倍,而 NVIDIA H100 本身不久前就改变了游戏规则。这些性能数字在 AI 和 HPC 社区引起了轰动,不仅是因为它们的原始能力,还因为它们对计算、成本效率和可访问性的未来具有重要意义。
本篇博文将深入探讨 B200 的特别之处、它与 H200 和 GH200 等其他 NVIDIA 硬件的比较,以及 FP4(4 位量化)的出现为何是实现这一非凡性能飞跃的关键。此外,我们将探讨这些进步如何使 AI 计算比以往更快、更便宜、更易于访问,并可能对各个行业产生影响。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











