







目录
2、均方差损失(Mean Square Error Loss)
一、概念
1、定义
全卷积网络(Fully Convolutional Networks,FCN)是一种用于语义分割的深度学习网络模型。传统的卷积神经网络(CNN)常用于图像分类任务,但是对于像素级别的语义分割任务,需要输出每个像素的类别标签,CNN的全连接层并不能处理不同输入尺寸的图像,因此不能直接用于语义分割。
FCN通过将全连接层替换为全卷积层,实现了端到端的像素级别的语义分割。FCN的网络结构由编码器和解码器组成。编码器用于提取图像的高级语义信息,解码器用于将编码器的特征图上采样到原始图像大小,并输出每个像素的类别标签。
具体而言,FCN的编码器部分通常使用预训练的卷积神经网络,如VGG16或ResNet等,这些网络在大规模图像分类数据集上进行了训练,并且能够提取图像的高级语义特征。然后,在编码器的最后几个卷积层上添加了1x1卷积层,将通道数缩减为要分割的类别数。
解码器部分通常由反卷积层和跳跃连接(skip connection)组成。反卷积层通过上采样操作将编码器的特征图恢复到原始图像大小,同时进行细化和增强特征。跳跃连接是指将编码器的低级特征图与解码器的相应层特征图进行连接,这样可以将更多的细节信息传递到解码器,提高分割精度。
最后,使用softmax函数对解码器输出进行标签分类,得到每个像素的类别预测。FCN使用交叉熵损失函数来优化网络参数,并使用反向传播算法进行训练。
FCN的训练过程包括两个阶段:预训练和微调。预训练是在大规模图像分类数据集上对编码器进行训练,微调是在带有标注的语义分割数据集上对整个网络进行训练。
FCN是一种基于全卷积网络的语义分割模型,通过引入编码器和解码器的结构,实现了像素级别的语义分割任务。通过预训练和微调阶段的训练,FCN能够学习到图像的语义信息,并输出每个像素的类别标签,从而实现准确的语义分割。
2、详解
首个端对端的针对像素级预测的全卷积网络。使用分类网络作为骨干网络,全卷积的含义是将分类网络中的全连接层替换成了全卷积层。

通过一系列的卷积下采样得到最终的特征层,最终特征层的通道数是21,因为当初主流数据集为PASCAL VOC,该数据集有20个类别加上1个背景。得到最终特征层之后,对其进行上采样,恢复为原图大小的特征图,其中通道数为21。针对上采样之后的特征图的每一个像素,在21个通道上有21个值,对这21个值进行Softmax处理,就可以得到该像素针对每一个类别的预测概率,取概率最大的类别作为该像素的预测类别。
二、FCN结构
1、Convolutionalization
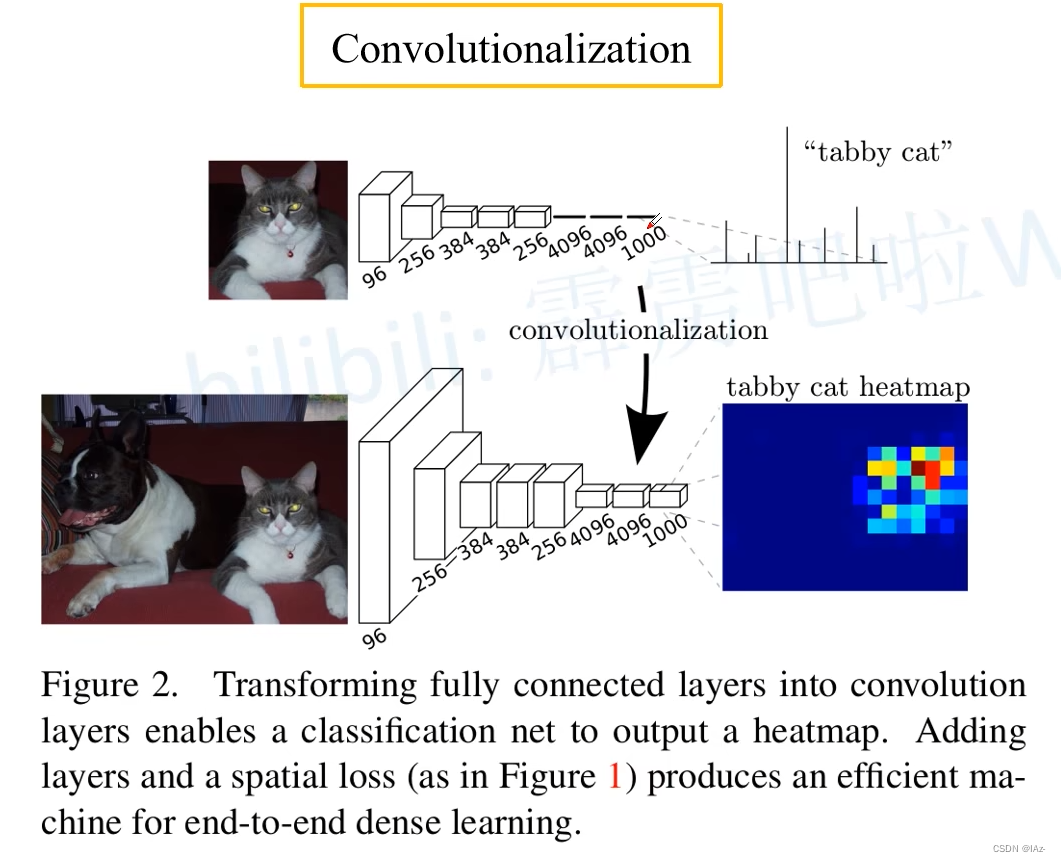
在分类网络中的最后三个全连接层对应着输出,输入一张图片,通过分类网络最后得到一个针对1000个类别的预测值,这一千个预测值通过Softmax处理后,就可以得到1000个类别的概率。 对于全连接层,要求输入节点个数是固定的,在训练过程中如果输入节点个数变化就会报错。
全局池化层可以支持输入任意尺寸的图片。全局池化层是在1x1卷积之后的,1x1卷积不改变特征图尺寸大小,无所谓输入图片的尺寸大小。
如果将最后三个全连接层全部替换为卷积层,对网络输入大小就无限制了。将全连接层的权重转化到卷积层中,就是对应Convolutionlization的过程。
采用卷积层之后,且输入图片大小大于224x224,则最终得到的特征层的高度和宽度是大于1的,并不是之前的1x1x1000的向量。大于1之后,对应的1000个通道里,每个通道的数据就是2维的,就可以可视化每个通道的数据,就可以得到heatmap图。
2、处理过程
 以VGG-16-D模型为例,从输入大小为224x224的图片经卷积池化操作之后,下采样32倍到7x7大小,然后依次通过三个全连接层,前两个全连接层对应的是4096个节点,最后一个节点对应的是1000个节点。
以VGG-16-D模型为例,从输入大小为224x224的图片经卷积池化操作之后,下采样32倍到7x7大小,然后依次通过三个全连接层,前两个全连接层对应的是4096个节点,最后一个节点对应的是1000个节点。
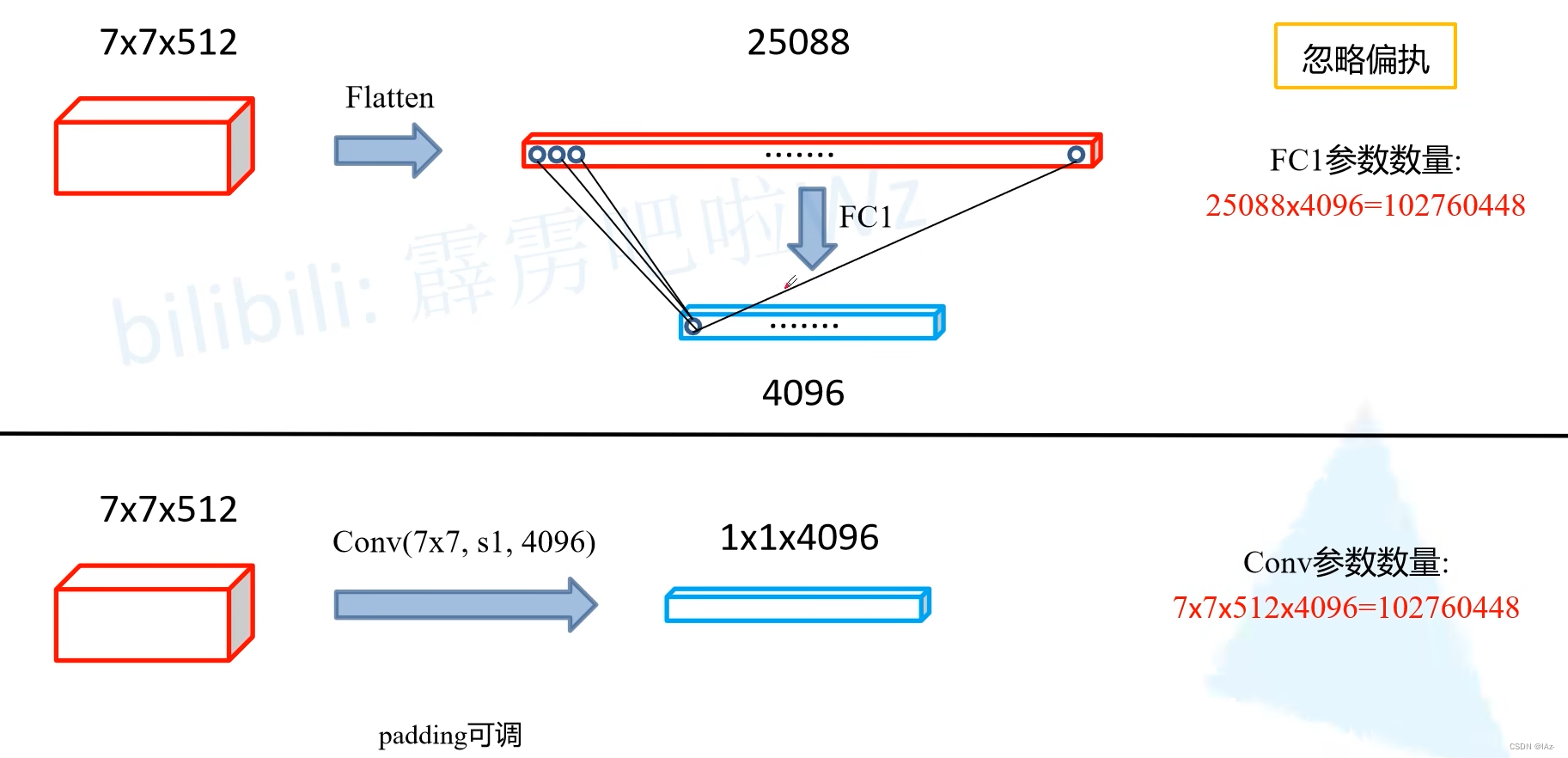
Convolutionalization过程
- 在分类网中得到[7x7x512]的特征图,首先将其进行Flatten展平处理,得到长度为[1x1x25088]的特征向量,通过全连接层FC1之后会得到一个[1x1x4096]的向量。对于全连接层FC1,展平处理后输出的每一个节点需要与全连接层输入的每一个节点进行全连接,则在忽略偏置b的情况下,FC1的参数数量为25088x4096=102760448个。
- 不使用全连接层,直接使用卷积核大小为[7x7x512],步距为1,4096个卷积核的卷积层,此时一个卷积层的参数量为7x7x512x4096=102760448个。
则此时全连接层和卷积层的参数量相同,全连接层中一个节点所对应的一系列参数与卷积层中的一个卷积核的参数相同,计算方式也相同,则直接将全连接层中每一个节点对应的权重进行ReShape处理,就能直接复制给卷积层使用。
假设padding为0,卷积核大小为[7x7],输出的是[1x1x4096]的特征图。
3、FCN-32S

- 原论文中所对应的源码在backbone的第一个卷积层处将padding设置成了100,论文中的解释是为了让FCN网络适应不同大小的图片。如果不去设定padding=100,当输入图片大小小于192x192时,通过VGG网络的backbone,在第一个全连接层之前,特征图的高和宽就会小于7x7,就导致FC6中padding=0,[7x7]大小的卷积层报错,无法进行卷积运算。更极端的情况是输入图片小于为32x32,而对于分类网络通常会将图片大小下采样32倍,则此时在backbone中就会报错。
- 作者给出padding=100的方法解决此类问题,但是在现如今的视角下看,通常只有极少数情况才会对小于32x32的图片进行语义分割工作,padding=100是没有必要的。
- 则对FCN6中[7x7]的卷积层进行padding=3操作,是可以对任意高宽大于32x32的图片进行训练的。而padding=100之后首先会增大网络计算量,其次在上采样之后会进行一定的裁剪。
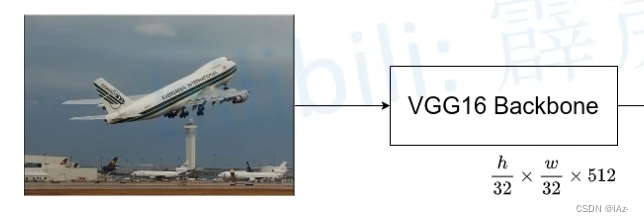
在FCN-32S中的VGG-16 backbone对应的是从图片输入到全连接层之前的位置,对应的是7x7x512的输出,将之后的第一个和第二个全连接层进行Convolutionalization处理,转换为FC6和FC7。
通过分类网络会将图片的高和宽下采样32倍,则输入一张图片之后,通过backbone得到的输出特征图大小为,h和w对应原图的高和宽。
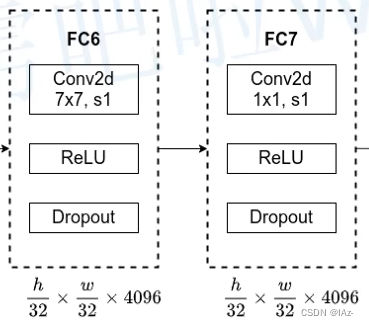
通过将FC6的padding设定为3,通过FC6之后是不会改变特征图的高和宽的,又使用了4096个卷积核,则经FC6得到的输出大小为。
- padding=3时,width_out=width_in。
而FC7对应的卷积核大小[1x1],步距为1,则输出特征矩阵的shape也不会发生变化。
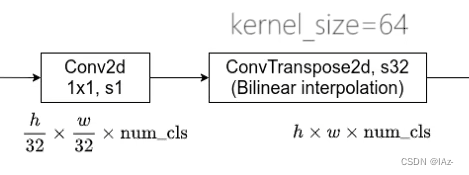
之后加上两个层结构,第一个为[1x1]的卷积层,步距为1,卷积核个数num_cls与分类的类别个数相同, 且包含背景,如使用PASCOL VOC数据集则此时num_cls=21。
再通过一个转置卷积,步距32,即上采样32倍,之后特征图就会恢复到原图大小。
原论文中使用双线性插值的参数初始化转置卷积的参数,通过上采样之后,特征图大小就变为,也就是针对每一个像素有num_cls个参数,对它进行softmax处理之后得到每一个像素的预测类别。
VGG-16 backbone与FC6、FC7部分直接使用VGG-16的权重,仅仅在后边加上了[1x1]卷积层和转置卷积层。
notes:
- 转置卷积在原论文中将学习参数冻结了,意味着等同于一个简单的双线性插值,可以直接使用深度学习框架中提供的双线性插值方法将特征图还原。
- 作者通过实验发现冻结参数与不冻结参数效果没有太大差别,由于不需要训练权重则可以加速训练过程。
- 使用转置卷积效果一般的原因可能是上采样率太大。
4、FCN-16S
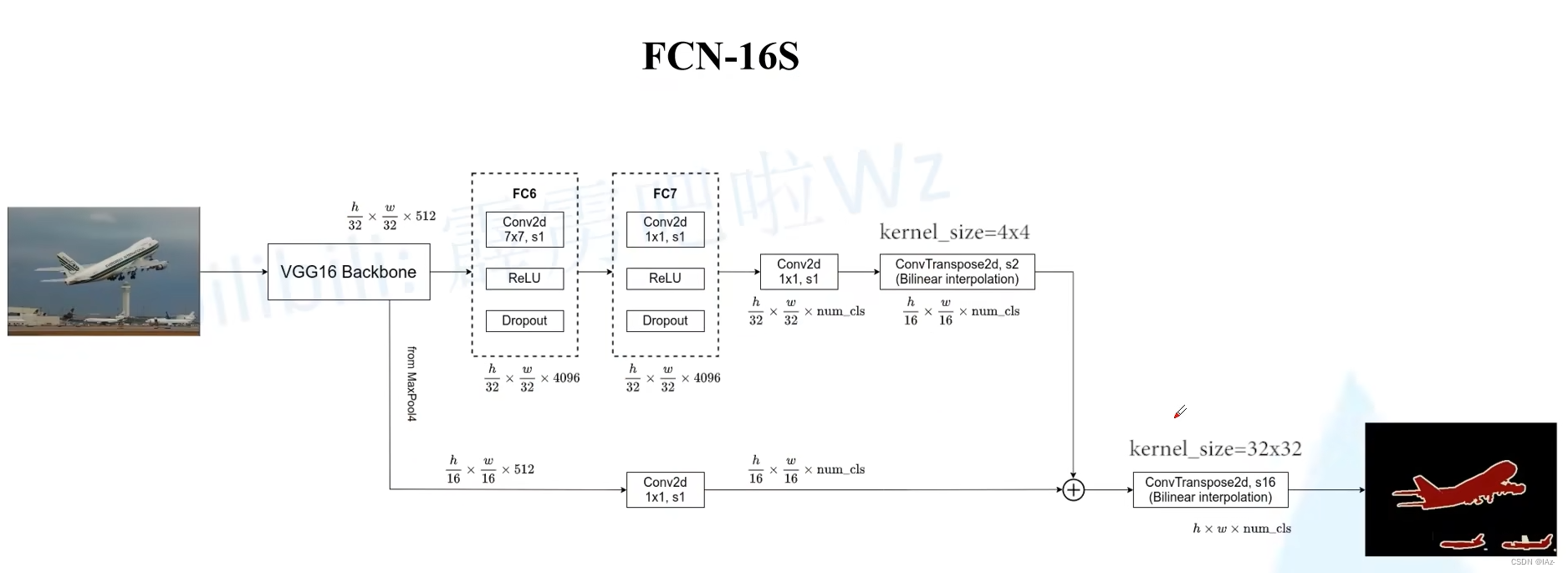
对于FCN-16S的结构中,VGG16 backbone、FC6和FC7都是不变的。
在FCN-16S中,FC7后的转置卷积上采样2倍。通过该转置卷积之后特征图高宽变为和
,
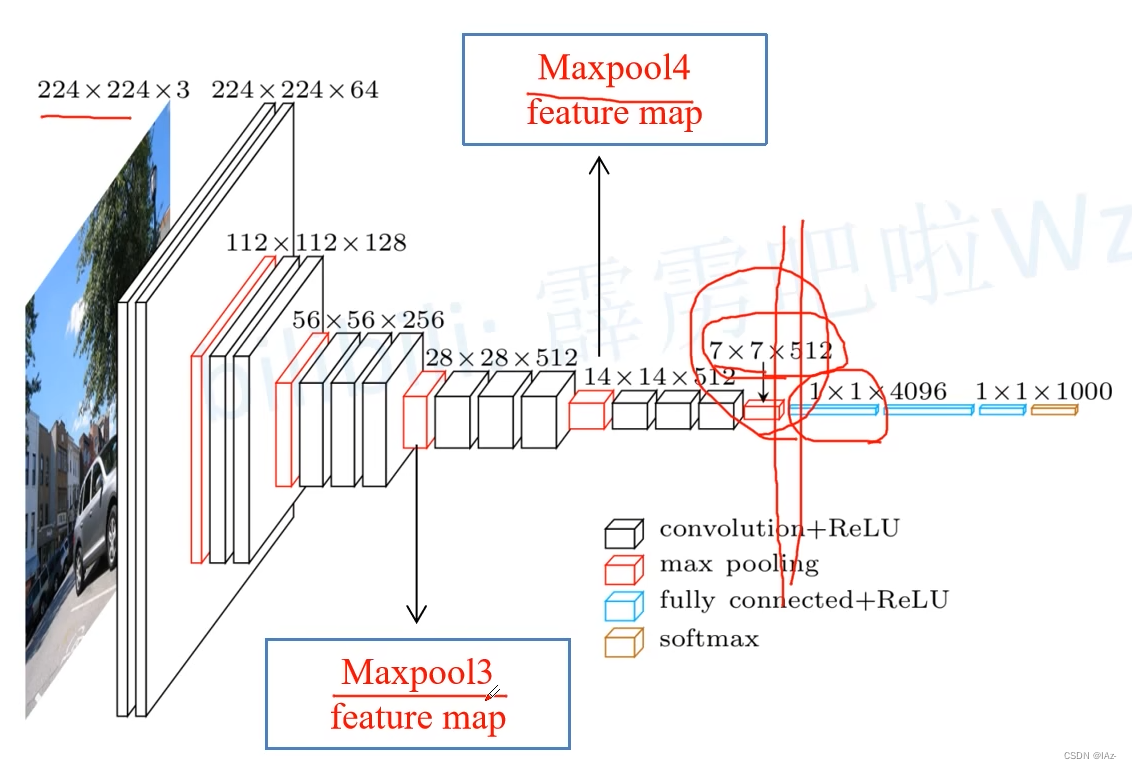
额外使用MaxPool4输出的特征图,输出的特征图大小为, 在VGG-16 backbone中,MaxPool3的下采样率是原图像高宽的
,通过MaxPool4的下采样率是原图像的
。
在MaxPool4输出的特征图后边接上一个大小[1x1],步距为1,卷积核个数为num_cls的卷积层,得到大小的特征图。
此时两者得到的特征图大小相等,进行相加操作,之后通过一个转置卷积上采样16倍,就可以得到原图像的大小。
FCN-16S中融合了来自MaxPool4的特征图信息。
5、FCN-8S
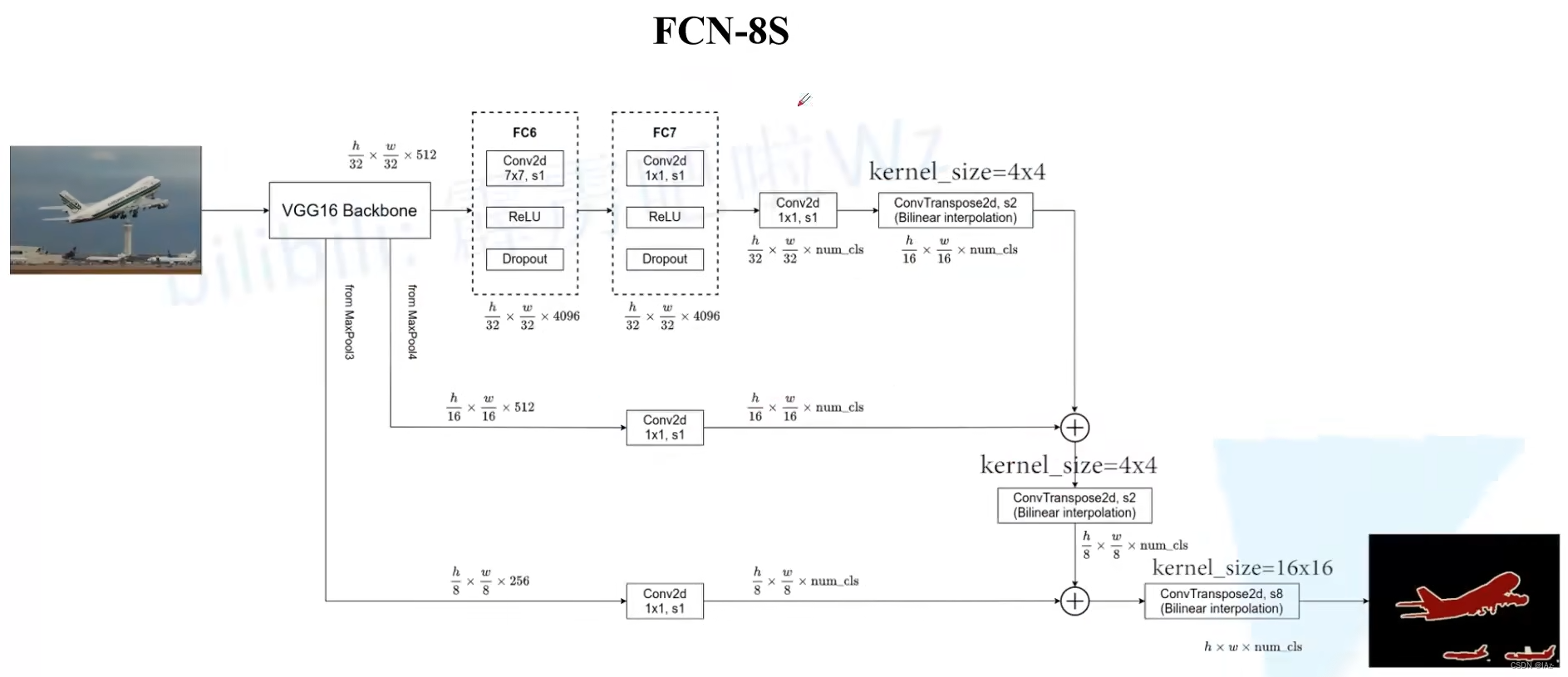
FCN-8S在FCN-16S的基础上,增加了MaxPool3的输出,通过MaxPool3之后图像下采样了8倍,尺寸为,在之后加上大小[1x1],步距为1,卷积核个数为num_cls的卷积层,通过这个卷积层之后得到特征图大小为
。
将原FCN-16S的两个特征图相加之后,特征图大小为,再使用转置卷积进行2倍上采样,就能得到大小为
的特征图。
将经过转置卷积上采样两倍后的特征图与MaxPool3经卷积得到的特征图进行相加,再通过一个转置卷积上采样8倍就可还原为原图大小。
notes:
FCN-16S与FCN-8S都有融合相对底层的特征层信息。
三、常见损失计算
1、交叉熵损失函数(Cross Entropy Loss)
交叉熵损失(Cross Entropy Loss)是最常见的损失函数之一,用于分类问题。对于每个像素点,计算真实标签和预测标签之间的交叉熵损失,然后对所有像素点的损失求平均。
其中,y是真实标签,是预测标签。
2、均方差损失(Mean Square Error Loss)
均方差损失(Mean Square Error Loss)也是一种常见的损失函数,用于回归问题。对于每个像素点,计算真实标签和预测标签之间的差的平方,然后对所有像素点的损失求平均。
其中,y是真实标签,是预测标签,N是像素点的总数。
3、Dice损失(Dice Loss)
Dice损失(Dice Loss)常用于像素级的图像分割任务。Dice损失是通过计算预测标签和真实标签之间的相似度来度量的。它的计算公式为:2 * (交集的像素数) / (预测标签的像素数 + 真实标签的像素数)。
其中,y是真实标签,是预测标签。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











