






本文介绍FM(Factorization Machines)二分类器使用FTRL优化的算法原理,以及如何结合softmax改造成一个多分类器。我自己实现了该算法工具,取名为alphaFM,已经开源。
最近公司内部举办了一届数据挖掘大赛,题目是根据用户的一些属性和行为数据来预测性别和年龄区间,属于一个二分类问题(性别预测男女)和一个多分类问题(年龄分为7个区间),评判标准为logloss。共有五六十支队伍提交,我们组的三名小伙伴最终取得第三名的好成绩,跟前两名只有千分之一二的差距。
赛后总结,发现前6名全部使用了DNN模型,而我们团队比较特别的是,不只使用了DNN,还有FM,最终方案是六七个DNN模型和一个FM模型的ensembling。
其实比赛刚开始,他们使用的是XGBoost,因为XGBoost的名头实在太响。但这次比赛的数据量规模较大,训练样本数达到千万,XGBoost跑起来异常的慢,一个模型要跑一两天。于是我把几个月前写的FM工具给他们用,效果非常好,二分类只需十几分钟,多分类也就半个多小时,logloss和XGBoost基本持平,甚至更低。最终他们抛弃了XGBoost,使用FM在快速验证特征和模型融合方面都起到了很好的作用。此外,我们组另外两名实习生仅使用此FM工具就取得了第七名的成绩。
最初写此FM代码时正值alphaGo完虐人类,因此随手给这个工具起了个名字叫alphaFM,今天我就来分享一下这个工具是如何实现的。
alphaFM介绍
代码地址在:
alphaFM是Factorization Machines的一个单机多线程版本实现,用于解决二分类问题,比如CTR预估,优化算法采用了FTRL。我其实把sgd和adagrad的方法也实现了,但最终发现还是FTRL的效果最好。
实现alphaFM的初衷是解决大规模数据的FM训练,在我们真实的业务数据中,训练样本数常常是千万到亿级别,特征维度是百万到千万级别甚至上亿,这样规模的数据完全加载到内存训练已经不太现实,甚至下载到本地硬盘都很困难,一般都是经过spark生成样本直接存储在hdfs上。
alphaFM用于解决这样的问题特别适合,一边从hdfs下载,一边计算,一个典型的使用方法是这样:
训练:10个线程计算,factorization的维度是8,最后得到模型文件fm_model.txt
hadoop fs -cat train_data_hdfs_path | ./fm_train -core 10 -dim 1,1,8 -m fm_model.txt测试:10个线程计算,factorization的维度是8,加载模型文件fm_model.txt,最后输出预测结果文件fm_pre.txt
hadoop fs -cat test_data_hdfs_path | ./fm_predict -core 10 -dim 8 -m fm_model.txt -out fm_pre.txt当然,如果样本文件不大,也可以先下载到本地,然后再运行alphaFM。
由于采用了FTRL,调好参数后,训练样本只需过一遍即可收敛,无需多次迭代,因此alphaFM读取训练样本采用了管道的方式,这样的好处除了节省内存,还可以通过管道对输入数据做各种中间过程的转换,比如采样、格式变换等,无需重新生成训练样本,方便灵活做实验。
alphaFM还支持加载上次的模型,继续在新数据上训练,理论上可以一直这样增量式进行下去。
FTRL的好处之一是可以得到稀疏解,在LR上非常有效,但对于FM,模型参数v是个向量,对于每一个特征,必须w为0且v的每一维都为0才算稀疏解, 但这通常很难满足,所以加了一个force_v_sparse的参数,在训练过程中,每当w变成0时,就强制将对应的v变成0向量。这样就可以得到很好的稀疏效果,且在我的实验中发现最终对test样本的logloss没有什么影响。
当将dim参数设置为1,1,0时,alphaFM就退化成标准的LR的FTRL训练工具。不禁想起我们最早的LR的FTRL代码还是勇保同学写的,我现在的代码基本上还是沿用了当初的多线程思路,感慨一下。
alphaFM能够处理的特征维度取决于内存大小,训练样本基本不占内存,理论上可以处理任意多的数量。后续可以考虑基于ps框架把alphaFM改造成分布式版本,这样就可以支持更大的特征维度。
alphaFM_softmax是alphaFM的多分类版本。两个工具的具体使用方法和参数说明见代码的readme,这里不再详述。
接下来请各位打起精神,我们来推一推公式。诗云,万丈高楼平地起,牛不牛逼靠地基。公式就是算法工具的地基,公式整明白了,像我们这种”精通”C++的(谁简历里不是呢:-P),实现就是分分钟的事(装B中,勿扰:-)。
二分类问题
对于二分类,最常见的模型是LR,搭配FTRL优化算法。LR的输出会用到sigmoid函数,定义为:
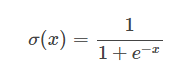
LR预测输入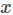
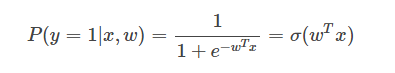
可以看到,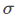
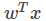
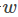
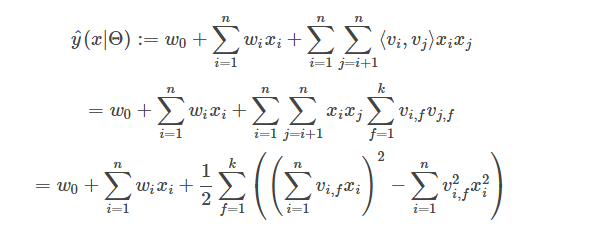
其中,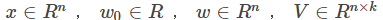
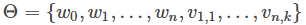
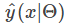
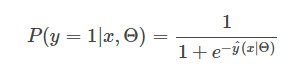
对于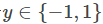
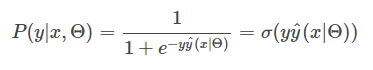
模型参数估计采用最大似然的方法,对于训练数据
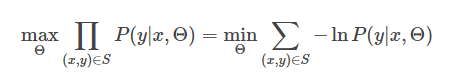
即样本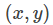
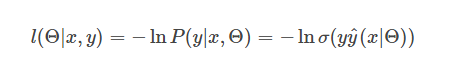
此损失函数对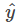
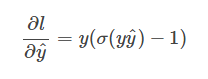
再配合上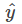
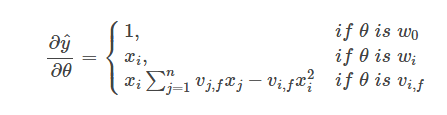
便可得到损失函数
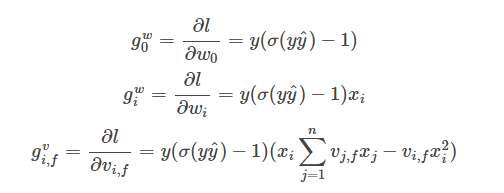
此时,我们能够很自然的想到用SGD的方法来求解模型参数,但我这里采用了更加高效的FTRL优化算法。
让我们来简单回顾一下FTRL,Google在2013年放出这个优化方法,迅速火遍大江南北,原始论文里只是用来解决LR问题,论文截图如下:

但其实FTRL是一个online learning的框架,能解决的问题绝不仅仅是LR,已经成了一个通用的优化算子,比如TensorFlow的optimizer中都包含了FTRL。我们只要把截图中的伪代码修改,
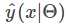
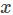
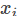
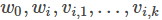
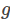
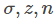


多分类问题
Softmax模型是LR在多分类上的推广,具体介绍戳这里。大致就是如果有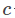

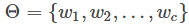
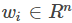
样本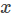
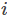
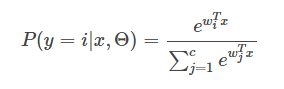
FM解决多分类的方法同样是将线性部分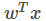
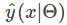
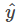
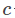

样本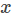
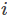
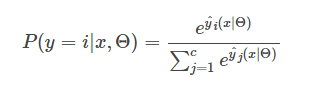
模型参数一共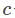
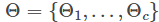
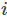
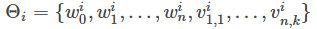
我们定义一个示性函数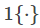
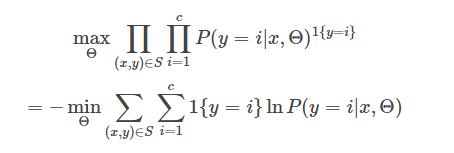
每条样本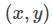
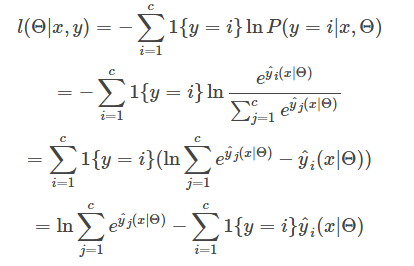
梯度:
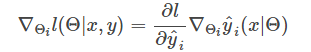
而
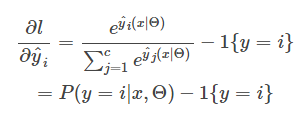
所以有

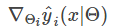
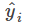
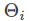

最后,仍然是套用FTRL的框架,只是每条样本更新的参数更多,不再细说,详见代码。
本文作者:张卫,8年多码农生涯,先后在腾讯、搜狗混过些时日,目前在小米负责广告算法。无甚特别,唯好数学物理,正所谓推公式无敌手,推妹子无得手的中二汉子。















 9858
9858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









