







串行程序
连通域:
连通域标记是图像处理中常用的预处理方法,在机器视觉、目标检测跟踪中几乎都要用到。
一个例子:主动反狙击探测
猫眼效应↓

瞄准镜目标↓

检测标记↓


有很多种标记算法,其中一种↓
原理描述:

数据输入:从文件中读取图像数据,记为D
初始化:开辟与图像尺寸相同的数据空间,对每个像素顺序标号,生成标号矩阵L
处理:对于L中的每一个像素p,首先根据D矩阵判断领域像素是否连通,然后搜寻连通邻域内的最小值v_min,令L[p]=v_min
循环:循环上步骤,直到L没有变动
结果:L就是标号矩阵
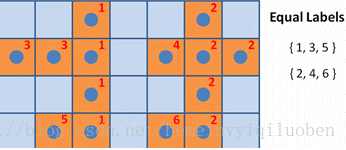
如下图,灰色的属于一类元素,白色的是另一类元素,通过每个像素的领域搜索、置最小,多次循环后,最终可以标出连通域。

从左到右,从上到下,遍历全部像素,将当前像素置为邻域内最小。
重复遍历多次,直到没有变动。复杂度O(n^2)
do{
m =kernel8(D, L, N, W, threshold);
}while(m);
传统C语言下的一些加速方法:用内联函数减小开销,移位代替乘除。
图像解码和输入
CUDA服务器上账号的权限有限,无法配置环境,只能使用标准库和已安装的库,并且没有图形界面。解决方法:编解码和处理分离。
使用PIL库读取图像文件(img2input.py),转化为文本文件作为cuda程序的输入,处理结果也以文本文件表示。最后使用result2Img.py转化为图片以显示结果。


处理输出数据时,利用
imPix[j,i]=(int(label[j])%1027%256,int(label[j])%537%256,int(label[j])%3531%256)
对同一个label着色,以便显示结果。这实际上是哈希到了0-255.

输入:

运行,耗时1.29 s

结果(用Python转换为图像):

标记结果:

并行实现
大循环中,每个像素的处理可以并行。
为每个像素分配thread,并行实现邻域查找,逻辑上将时间n缩小到了1,复杂度从O(n^2)到O(n)。
实现细节:1个block分配256 threads,每个thread处理一个像素点;根据图像大小分配block数量。Thread执行的顺序无法控制,但在有限资源的硬件上block会串行分配,总体上遍历像素时还是从上到下,从左到右的顺序。
实现了一次遍历中的并行,但是循环次数没有变化,连通域太大时收敛较慢(Naive & Simple的方法)。
Gpu上运行,耗时0.27 s

结果一致。
算法优化
算法上的优化,Oleksandr Kalentev提出的label equivalence算法,分为扫描-分析-标记步骤。
除了label矩阵,还引入了"等价表",以下论文给出了算法细节,以伪代码形式描述。

在大循环内增加小循环,每个tread负责将当前像素的指向的root从局部最小移到全局最小。
原理是检查所指的根是否是底层根,如果不是,顺藤摸瓜,找出底层root,并修改该像素的指向,如上图所示。
减少了大循环,加快了收敛速度→常数倍的速度提升。


其他方面的优化:
使用Texture memory
方法:
声明- texture<float, 1, cudaReadModeElementType> texRef;
绑定- cudaBindTexture(0,texRef,rain_table );
调取- tex1Dfetch(texRef, index);
解除- cudaUnbindTexture(texRef);
(http://preston2006.blog.sohu.com/253531751.html)
不使用Texture MeM

使用Texture MeM

结论:优化算法大大加快了收敛速度,但加不加纹理缓存并没有区别!在1.X架构的硬件上比较有用,2.X以后的硬件中,L2缓存可以加速全局存储的读取速度。
性能测试
至此,我们已经得到了4个程序,分别是:CPU上的naive算法程序,naive算法的GPU并行实现,GPU上的优化算法程序,GPU上使用texture的优化算法程序. 将这4个程序记为A、B、C、D,以便后文描述。如下图,程序体积也越来越大。

串行与并行对比
串行程序
在服务器上运行A程序进行评估。服务器上有2个CPU E5-2620,每个6核,每核超线程2,总共有24个逻辑核。


图 1 服务器cpu配置
测试方法:使用同一幅彩色图像,分别处理得到宽度为2048、1080、640、320的图像,高度按比例缩放。图像内容如下。

服务器上没有第三方库,需要先把图像解码为文本文件,使用img2input.py.

解码之后的结果,成为文本文件。

放到服务器上,运行测试结果(多次运行,取平均)。

2048图像:77 s
使用另外一个Python程序result2img.py 转换为图像,以便查看结果(实际应用时不需要这步,机器不需要看图像)。

使用相同的方法,测试其他尺寸的图像。
1080:26 s

640:7.32 s

320:1.3 s

串行程序在cpu上的执行时间,随图像体积而变 | ||||
尺寸(width, pixes) | 2048 | 1080 | 640 | 320 |
耗时(s) | 77 | 26 | 7.3 | 1.3 |
列表如下:

O(N^2) !
并行化
B程序是直接并行化后的程序。在k20下,测试其执行结果。
2048:4.4s

1080: 2.1 s

640:1.65 s

320:1.60 s

并行化程序在k20上的执行时间,随图像尺寸而变 | ||||
尺寸(width, pixes) | 2048 | 1080 | 640 | 320 |
耗时(s) | 4.4 | 2.1 | 1.65 | 1.60 |

服务器下多次测得的结果波动很大。 多用户?其他原因?

两种算法对比
对应2048宽度图像,B与C程序的对比,90倍加速。

Label equivalence算法:
不同硬件执行对比
硬件参数
GT 635m

K20c

使用naive算法程序(B)测试
使用naive 的gpu并行连通域标记程序,在两种硬件上计算2048和320宽度的图像。
K20C, 2048:4.4 s

635m, 2048: 9.4 s

K20C, 320: 1.6 s

635m, 320: 0.1 s

结论:?运行大量计算时,服务器上更快,少量计算时,pc更快。?
11月27日,服务器上的显卡运行状态:







╮(╯▽╰)╭反正都是我没办法解决的。
服务器上GPU运行性能的测试是不可靠的,在635m上重新评估并行程序的性能。
尺寸(width, pixes) | 2048 | 1080 | 640 | 320 |
耗时(s) | 9.4 | 1.63 | 0.48 | 0.1 |

//纹理缓存在不同架构上的表现
C程序是优化算法的程序,D在C的基础上使用了texture MeM. 都输入较大尺寸的图像数据进行运算。
635上: 差别不大

体会
CUDA为并行计算提供了低成本的方案。
一般用在计算模拟而非实际工程中,节省人力很重要,优化要适可而止,花一天优化程序有时候并不值得。
说到节省时间,MATLAB比C好用,MATLAB中调用GPU可能更容易。
算法比编程技巧重要,从CPU到GPU可以加快40倍,但另一种算法加快了90倍。
谢谢老师的辛勤教导,感谢大家抽出时间。















 1418
1418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









