







项目地址:https://github.com/levihsu/OOTDiffusion
试用地址:https://ootd.ibot.cn/
论文:2403.OOTDiffusion: 基于衣服融合的可控虚拟试穿潜在扩散
arxiv: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on | readpaper
在comfyui中使用: https://github.com/StartHua/ComfyUI_OOTDiffusion_CXH
b站说明:https://www.bilibili.com/video/BV1nj421Q7yg
一、简介
基于图片虚拟试穿(image-based virtual try-on ,VTON)
基于扩散模型全套试穿:Outfitting over Try-on Diffusion (OOTDiffusion)
利用预训练的潜在扩散模型的力量(pretrained latent diffusion models),用于现实和可控的(realistic and controllable)虚拟试穿。在没有明确的衣物形变适应过程(warping process)的情况下,
提出了一个outfitting UNet来学习服装细节特征,在扩散模型去噪过程中,通过我们提出的服装融合outfitting fusion将其与目标人体融合。
1.1 原文展示结果
生成分辨率 1024x768
第一行数据,是在`VITON-HD,半身数据集上训练的,支持上半身衣服(upper-body garment)
第二行,在Dress Code 数据集训练, 支持上半身服装(upper-body)、下身服装(upper-body)和裙子(dresses)

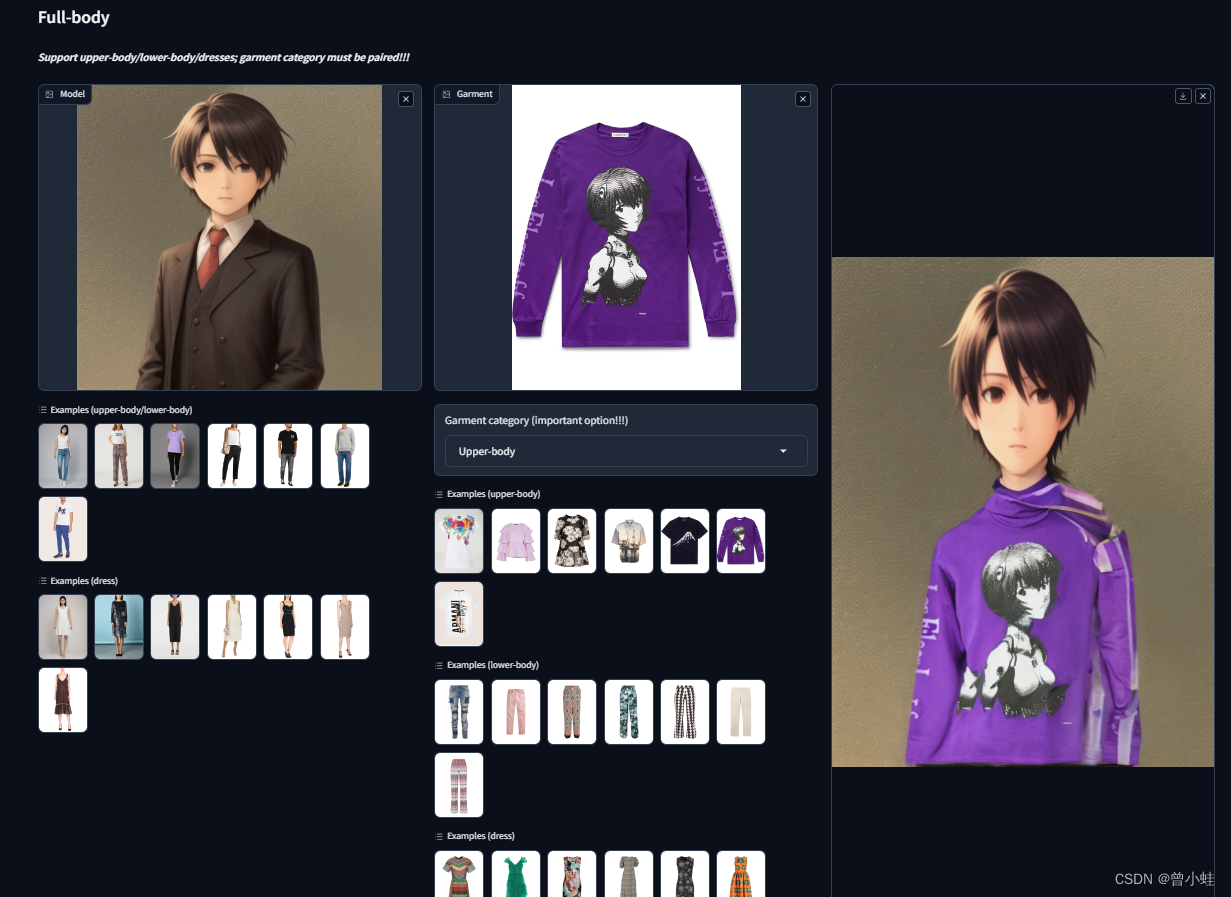
1.2 实测结果
生成衣服保存特征还是会有问题
二、如何训练?
2.1 数据集
1024x768分辨率
VitonHD数据集
13,679对正面半身模型和相应的上半身服装组成,其中2032对作为测试集。
Dress Code数据集
15,363/8,951/2,947 个全身模型的图像对和相应的上半身服装/下身服装/服装组成,其中每个服装类别的 1,800 对作为测试集。
训练参数
实验中,我们通过继承Stable Diffusion v1.5 的 预训练权重来初始化 OOTDiffusion 模型。
然后我们使用固定学习率为 5e-5 的 AdamW 优化器微调(fineturn)换衣Unet和去噪 UNet。
请注意,我们分别在 512 × 384 和 1024 × 768 的分辨率下在 VITON-HD [6] 和 Dress Code [33] 数据集上训练四种类型的模型。
所有模型都在 单个NVIDIA A100 GPU 上训练 36000 次迭代,
512 × 384 分辨率的批量大小为 64,
1024 × 768 分辨率的批量大小为 16。
在推理时,我们使用 UniPC 采样器在单个 NVIDIA RTX 4090 GPU 上运行我们的 OOTDiffusion 20 个采样步骤 [
三、方法与原理
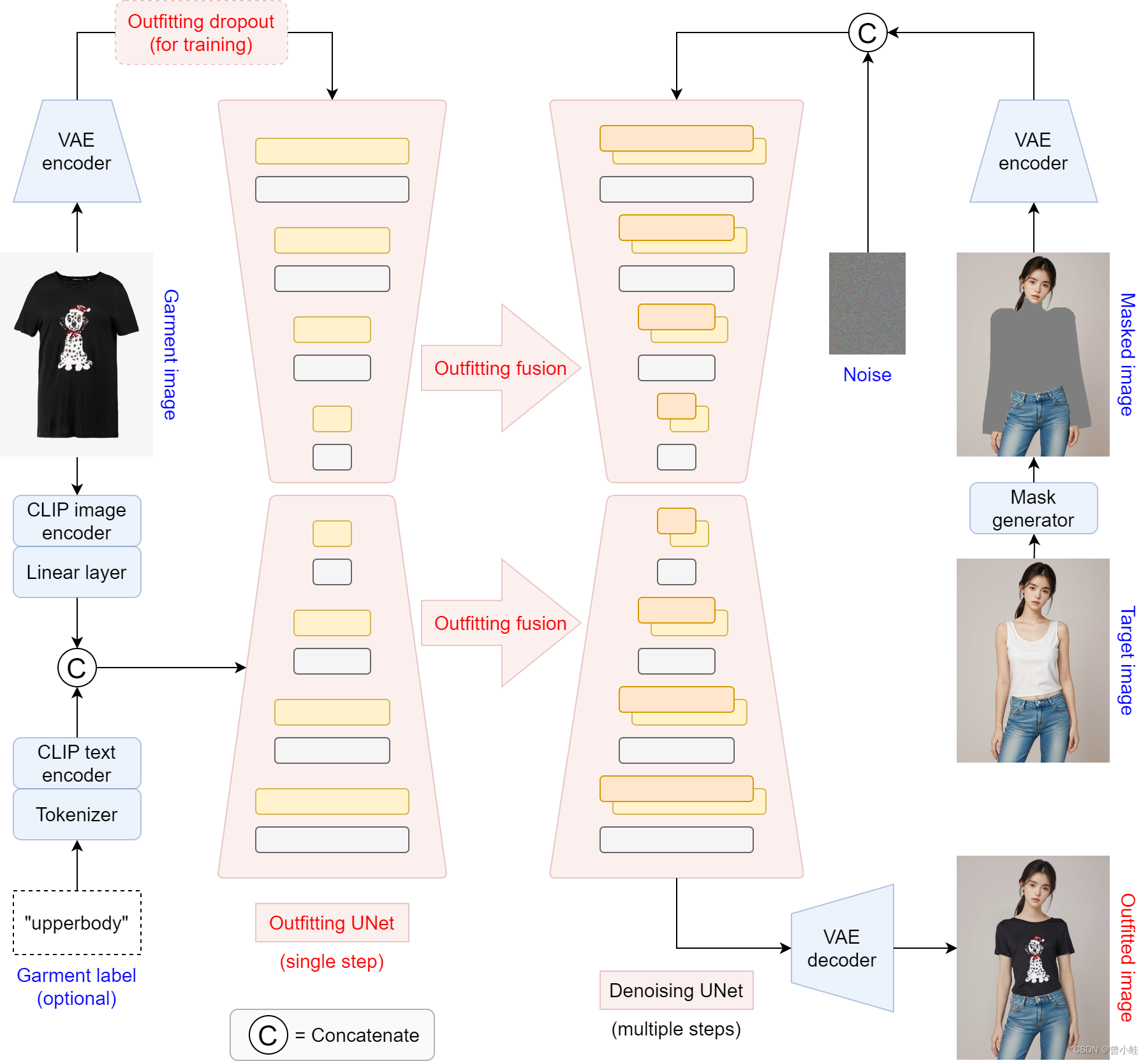
原图2: 概述OOTDiffusion模型。
- 在左侧,服装图像被 clip-vit-large-patch14 编码到潜在空间中,并输入到服装UNet中进行单步处理。
- 与CLIP编码器生成的辅助调节输入一起,通过服装融合(outfitting fusion)将服装特征纳入去噪UNet。
- 在训练过程中,为了实现无分类器的指导(classifier-free guidance),对训练过程进行了 outfitting dropout。
- 在右侧,输入的人类图像通过掩码生成模块(mask generator, HumanParsing+OpenPose )将需要换衣以及相近的地方被遮盖为黑色(masked),并与高斯噪声连接在一起,作为多个采样步骤的去噪UNet的输入。
- 去噪后,特征映射被解码回图像空间作为我们的试戴结果。
Overview of our proposed OOTDiffusion model. On the left side, the garment image is encoded into the latent space and fed into the outfitting UNet for a single step process. Along with the auxiliary conditioning input generated by CLIP encoders, the garment features are incorporated into the denoising UNet via outfitting fusion. Outfitting dropout is performed for the garment latents particularly in training to enable classifier-free guidance. On the right side, the input human image is masked with respect to the target region and concatenated with a Gaussian noise as the input to the denoising UNet for multiple sampling steps. After denoising, the feature map is decoded back into the image space as our try-on result.
数学参数概述
输入一张 3xHxW的图片
x
x
x, 一张衣服图片
g
g
g ,输出换衣结果
x
g
x_g
xg
采用 OpenPose 和 HumanParsing 产生遮盖区域图片
x
m
x_m
xm
通过VAE的编码器
ϵ
\epsilon
ϵ进入latent空间 (原图被降采样8倍)
E
(
x
m
)
∈
R
4
×
h
×
w
,
h
=
H
8
,
w
=
W
8
\mathcal{E}(x_m) \in \mathbb{R}^{4 \times h \times w}, h = \frac{H}{8}, w = \frac{W}{8}
E(xm)∈R4×h×w,h=8H,w=8W
和高斯噪声拼接后构成 (8通道)
z
T
∈
R
8
×
h
×
w
z_T \in \mathbb{R}^{8 \times h \times w}
zT∈R8×h×w
为了让 去噪Unet支持8通道数据的输入,对一个卷积层,增加了4个0初始化通道
另一方面,我们将编码的服装隐码(encoded garment latent)
E
(
g
)
∈
R
4
×
h
×
w
\mathcal{E}(g) \in \mathbb{R}^{4 \times h \times w}
E(g)∈R4×h×w输入到
(i) outfit UNet模快,训练一步学习服装特征
(ii换衣融合将它们集成到去噪UNet中。
(iii) 对
E
(
g
)
\mathcal{E}(g)
E(g)进行 outfit dropout,尤其是在训练过程中
此外,我们还对服装图像进行了CLIP 文本反演[10] textual-inversion(即),并可选地将其与服装标签∈{“上半身”、“下半身”、“衣服”}的文本嵌入(text embeding)连接起来作为辅助条件输入(auxiliary conditioning input),
通过交叉注意机制输入到2个unet模型中(去噪unet和换衣unet)。
最后,在去噪过程的多个步骤之后,我们使用 VAE 解码器 D 将去噪的潜在 z0 ∈ R4×h×w 转换回图像空间作为输出图像 xg = D(z0) ∈ R3×H×W。我们将在以下部分中详细说明
OOTDiffusion 的关键技术
(i) Outfitting UNet,
(ii) Outfitting fusion
(iii) Outfitting dropout
outfitting Unet
与stable diffusion 的UNet结构基本相同
直接复制Stable Diffusion[40]的预训练UNet权值,
初始化我们的过拟合和去噪UNets(除了添加到第一个卷积层的零初始化通道除外
损失函数为
其中
where
ψ
=
τ
g
(
g
)
∘
τ
y
(
y
)
represents the auxiliary conditioning input for both
ω
θ
′
and
ϵ
θ
.
\text{where } \psi = \tau_g(g) \circ \tau_y(y) \text{ represents the auxiliary conditioning input for both } \omega_{\theta'} \text{ and } \epsilon_{\theta}.
where ψ=τg(g)∘τy(y) represents the auxiliary conditioning input for both ωθ′ and ϵθ.
L
O
O
T
D
=
E
E
(
x
m
)
,
E
(
g
)
,
ψ
,
ϵ
∼
N
(
0
,
1
)
,
t
[
∥
ϵ
−
ϵ
θ
(
z
t
,
t
,
ω
θ
′
(
E
(
g
)
,
ψ
)
,
ψ
)
∥
2
2
]
(
2
)
\mathcal{L}_{OOTD} = \mathbb{E}_{\mathcal{E}(x_m), \mathcal{E}(g), \psi, \epsilon \sim \mathcal{N}(0, 1), t}\left[\lVert \epsilon - \epsilon_{\theta}(\mathbf{z}_t, t, \omega_{\theta'}(\mathcal{E}(g), \psi), \psi) \rVert_2^2\right] (2)
LOOTD=EE(xm),E(g),ψ,ϵ∼N(0,1),t[∥ϵ−ϵθ(zt,t,ωθ′(E(g),ψ),ψ)∥22](2)
Outfitting fusion
参考了驱动图片运动的论文空间注意力机制(spatial-attention mechanism [)
23.12 Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation
引入了一种融合模块,将学习到的服装特征融入到去噪Unet中
代码和模型下载 (环境安装参考b站)
代码
git clone https://github.com/levihsu/OOTDiffusion
模型
export HF_ENDPOINT=https://hf-mirror.com
huggingface-cli download --resume-download levihsu/OOTDiffusion --local-dir ./


















 1425
1425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











