






VAE (Variational Autoencoder)
代码:https://github.com/AntixK/PyTorch-VAE/blob/master/models/vanilla_vae.py
论文:Auto-Encoding Variational Bayes
核心参考1 https://github.com/lyeoni/pytorch-mnist-VAE/blob/master/pytorch-mnist-VAE.ipynb
工程化不错,但是vae的loss可能不对:https://blog.csdn.net/lsb2002/article/details/134837076
一、VAE直观理解 (全连接层实现,仅用作实验说明)
基于手写字符生成案例说明
0. 纯线性层,nn.liner实现(每个神经元连接到上一层的所有神经元)
2. 如何直接使用别人训练好的模型:预训练模型+模型
3. 如何训练vae?
1.1 直接推理生成图片 (加载训练好vae模型,随机生成只使用解码器)
随机生成多元的正态分布z, 输入到vae的解码器 (decoder),直接得到结构
def load_pretain_vae(point_path='./checkpoint_8.pth'):
# 加载预训练的vae
z_gauss_dims=2
# 下面是训练时的参数
vae = VAE(x_dim=784, h_dim1= 512, h_dim2=256, z_dim=z_gauss_dims)
vae.cuda() # 先移到CUDA上
vae.load_state_dict(torch.load(point_path, map_location=torch.device('cuda')))
print('load pretrain vae')
sample_num=6
# 输入一个多元正态分布(训练时候的维度)
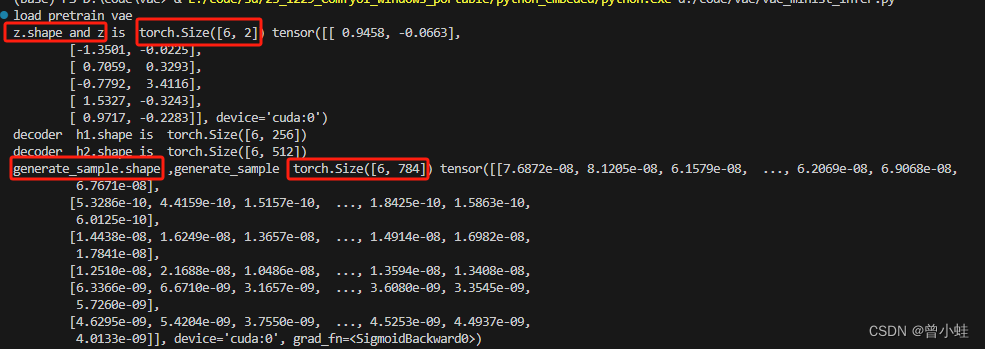
z = torch.randn(sample_num, z_gauss_dims).cuda()
print('z.shape and z is ',z.shape,z)
sample = vae.decoder(z).cuda()
# pytorchg官方保存 n c h w
# nrow 表示每行的显示数量(相当于列数)
save_image(sample.view(sample_num, 1, 28, 28), f'./load_pretain_vae' + '.png',nrow=2)
1.1.1 由随机正态分布直接生成
生成6张图片,输入是随机的z (shape 为 (6,2)), 然后进入到vae的解码器 (decoder)
输出为 (6,764)
可视化生成的6张手写字符

1.1.2 完整生成图片代码
'''
from: https://github.com/lyeoni/pytorch-mnist-VAE/blob/master/pytorch-mnist-VAE.ipynb
edit: zengxy+ gpt4o 2024.05.27
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
from torchvision.utils import save_image
import os
# z_dim 一般维度为2
#
class VAE(nn.Module):
def __init__(self, x_dim, h_dim1, h_dim2, z_dim):
super(VAE, self).__init__()
# encoder part
# 神经元中间层的个数与维度数
self.fc1 = nn.Linear(x_dim, h_dim1)
self.fc2 = nn.Linear(h_dim1, h_dim2)
self.fc31 = nn.Linear(h_dim2, z_dim)
self.fc32 = nn.Linear(h_dim2, z_dim)
# decoder part
self.fc4 = nn.Linear(z_dim, h_dim2)
self.fc5 = nn.Linear(h_dim2, h_dim1)
self.fc6 = nn.Linear(h_dim1, x_dim)
def encoder(self, x):
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
return self.fc31(h), self.fc32(h) # mu, log_var
def sampling(self, mu, log_var):
std = torch.exp(0.5*log_var)
eps = torch.randn_like(std)
return eps.mul(std).add_(mu) # return z sample
# 训练好后,用作生成还原图像
def decoder(self, z):
h = F.relu(self.fc4(z))
print('decoder h1.shape is ',h.shape)
h = F.relu(self.fc5(h))
print('decoder h2.shape is ',h.shape)
return F.sigmoid(self.fc6(h))
# 训练时执行逻辑
def forward(self, x):
mu, log_var = self.encoder(x.view(-1, 784))
z = self.sampling(mu, log_var)
return self.decoder(z), mu, log_var
def load_pretain_vae(point_path='./checkpoint_8.pth'):
# 加载预训练的vae
z_gauss_dims=2
# 下面是训练时的参数
vae = VAE(x_dim=784, h_dim1= 512, h_dim2=256, z_dim=z_gauss_dims)
vae.cuda() # 先移到CUDA上
vae.load_state_dict(torch.load(point_path, map_location=torch.device('cuda')))
print('load pretrain vae')
sample_num=6
# 输入一个多元正态分布(训练时候的维度)
z = torch.randn(sample_num, z_gauss_dims).cuda()
print('z.shape and z is ',z.shape,z)
sample = vae.decoder(z).cuda()
# pytorchg官方保存 n c h w
save_image(sample.view(sample_num, 1, 28, 28), f'./load_pretain_vae' + '.png',nrow=2)
if __name__ == '__main__':
load_pretain_vae()
1.2 训练中模型推理的逻辑 (编码器产生中间变量输入到解码器)
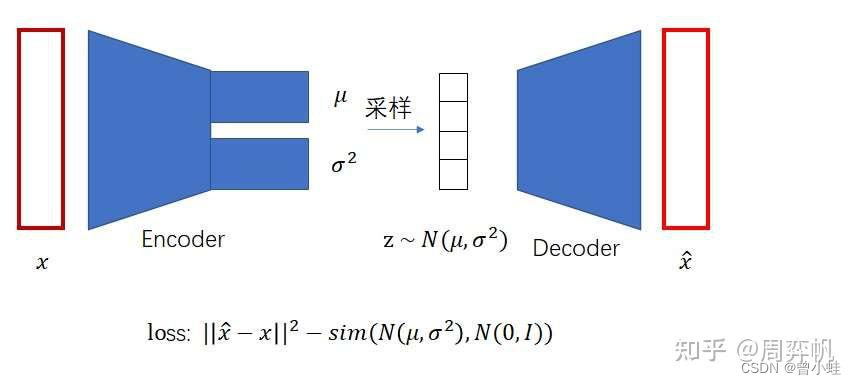
训练图片X经过编码器输出,经过重采样,得到Z,z经过编码器得到X^,
然后根据公式计算loss,反向迭代参数
输入训练数据data,
经过vae的前向推理流程:recon_batch, mu, log_var = self.model(data)
然后计算loss:loss = self.model.loss_function(recon_batch, data, mu, log_var)
sim前面有个负号的原因: 在实际实现中,KL
散度是一个非负值。为了使其在损失函数中发挥正则化作用,我们通常会加上负号,从而在整体损失中减去这个值,确保模型在训练过程中不仅关注重构误差,还关注潜在分布的正则化。
# 局部代码 仅用作说明
def train(self, epoch,save_image_name="train_sample"):
"""
训练过程。
:param epoch: 当前的训练轮数。
"""
self.model.train() #将导入的模型输入到训练模式
self.load_minist()
train_loss = 0
for batch_idx, (data, _) in enumerate(self.train_loader):
data = data.cuda()
self.optimizer.zero_grad()
recon_batch, mu, log_var = self.model(data)
loss = self.model.loss_function(recon_batch, data, mu, log_var)
loss.backward()
train_loss += loss.item()
self.optimizer.step()
1.2.0 正态分布的性质* (补充知识,可跳过)
根据正态分布的线性变换性质,我们可以推导出 ( z ) 的分布。具体来说,正态分布的线性变换性质包括以下几个方面:
-
线性组合的性质:
- 如果 X ∼ N ( μ X , σ X 2 ) X \sim \mathcal{N}(\mu_X, \sigma_X^2) X∼N(μX,σX2)
-
Y
∼
N
(
μ
Y
,
σ
Y
2
)
Y \sim \mathcal{N}(\mu_Y, \sigma_Y^2)
Y∼N(μY,σY2)
那么 a X + b Y ∼ N ( a μ X + b μ Y , a 2 σ X 2 + b 2 σ Y 2 ) aX + bY \sim \mathcal{N}(a\mu_X + b\mu_Y, a^2\sigma_X^2 + b^2\sigma_Y^2) aX+bY∼N(aμX+bμY,a2σX2+b2σY2)
-
加权和的性质:
- 如果 X ∼ N ( μ , σ 2 ) X \sim \mathcal{N}(\mu, \sigma^2) X∼N(μ,σ2),a和 b是常数,那么 a X + b ∼ N ( a μ + b , a 2 σ 2 ) aX + b \sim \mathcal{N}(a\mu + b, a^2\sigma^2) aX+b∼N(aμ+b,a2σ2)
1.2.1 loss计算函数
重构损失函数:二值交叉熵损失(Binary Cross Entropy Loss)
在VAE中逐像素应用的公式为:
BCE
=
−
∑
j
=
1
M
[
x
j
log
(
x
^
j
)
+
(
1
−
x
j
)
log
(
1
−
x
^
j
)
]
\text{BCE} = -\sum_{j=1}^M \left[ x_j \log(\hat{x}_j) + (1 - x_j) \log(1 - \hat{x}_j) \right]
BCE=−j=1∑M[xjlog(x^j)+(1−xj)log(1−x^j)]
KL 散度(KL Divergence)
def loss_function(self,recon_x, x, mu, log_var):
"""
VAE的损失函数,包括重构损失和KL散度(KLD:Kullback-Leibler divergence)。
:param recon_x: 重构的数据。
:param x: 原始数据。
:param mu: 编码的均值。
:param log_var: 编码的对数方差。
"""
BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784), reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
return BCE + KLD
为什么2个损失函数,如何推导的? (见后文,先及结论通读)
1.2.2 对应VAE的前向代码
输入训练数据x,
编码器的输出 mu, log_var用于计算z
输出最终的结果 self.decoder(z),
这里的log_var 表示 由网络输出的对数方差,等效于
l
o
g
(
σ
2
)
log(\sigma^2)
log(σ2)
# class VAE
def forward(self, x):
"""
VAE模型的前向传递。
:param x: 输入的训练数据数据。
"""
mu, log_var = self.encoder(x.view(-1, 784)) # 将图像展平处理
z = self.sampling(mu, log_var)
return self.decoder(z), mu, log_var
1.2.3 sampling函数 (重参数技巧)
返回值为Z
z
∼
N
(
μ
,
σ
2
)
z \sim \mathcal{N}(\mu, \sigma^2)
z∼N(μ,σ2)
下面的函数实现,等效下面函数实现,又叫重参数技巧
def sampling(self, mu, log_var):
std = torch.exp(0.5*log_var)
# 用于生成与给定张量具有相同形状和类型的随机数张量,其元素值遵循标准正态分布(均值为0,标准差为1)。
eps = torch.randn_like(std)
return eps.mul(std).add_(mu) # return z sample
可以用下面的公式表示 sampling 函数的操作:
z
=
mu
+
ϵ
×
exp
(
log
(
σ
2
)
2
)
z = \text{mu} + \epsilon \times \exp\left(\frac{\log(\sigma^2)}{2}\right)
z=mu+ϵ×exp(2log(σ2))
这里的log_var 表示 由网络输出的对数方差,等效于
l
o
g
(
σ
2
)
log(\sigma^2)
log(σ2)
其中 torch.exp(0.5*log_var) =
σ
\sigma
σ 表示为 std
使用 torch.randn_like(std) 生成一个与标准差 std 形状相同、服从标准正态分布(均值 0,方差 1)的随机噪声向量
ϵ
\epsilon
ϵ。
1.2.3.1 sampling函数为什么这样写?推导
- ϵ \epsilon ϵ 是从标准正态分布 N ( 0 , 1 ) \mathcal{N}(0, 1) N(0,1) 中采样的。
- σ \sigma σ 是标准差,因此 ϵ × σ \epsilon \times \sigma ϵ×σ是从标准差为 σ \sigma σ 的正态分布中采样的。
根据正态分布的性质,如果 ϵ ∼ N ( 0 , 1 ) \epsilon \sim \mathcal{N}(0, 1) ϵ∼N(0,1),则 ϵ × σ ∼ N ( 0 , σ 2 ) \epsilon \times \sigma \sim \mathcal{N}(0, \sigma^2) ϵ×σ∼N(0,σ2)。
- 加上均值 μ \mu μ 后,根据正态分布的线性变换性质:
z = μ + ϵ × σ ∼ N ( μ , σ 2 ) z = \mu + \epsilon \times \sigma \sim \mathcal{N}(\mu, \sigma^2) z=μ+ϵ×σ∼N(μ,σ2)

1.2.4 vae完整训练代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.utils import save_image
import os
'''
from: https://github.com/lyeoni/pytorch-mnist-VAE/blob/master/pytorch-mnist-VAE.ipynb
edit: zengxy+ gpt4o 2024.05.27
'''
class VAE(nn.Module):
def __init__(self, x_dim, h_dim1, h_dim2, z_dim):
"""
VAE模型的初始化。
:param x_dim: 输入数据的维度。
:param h_dim1: 第一个隐藏层的维度。
:param h_dim2: 第二个隐藏层的维度。
:param z_dim: 潜在变量的维度。
"""
super(VAE, self).__init__()
# 编码器部分
self.fc1 = nn.Linear(x_dim, h_dim1)
self.fc2 = nn.Linear(h_dim1, h_dim2)
self.fc31 = nn.Linear(h_dim2, z_dim) # 生成均值
self.fc32 = nn.Linear(h_dim2, z_dim) # 生成对数方差
# 解码器部分
self.fc4 = nn.Linear(z_dim, h_dim2)
self.fc5 = nn.Linear(h_dim2, h_dim1)
self.fc6 = nn.Linear(h_dim1, x_dim)
def encoder(self, x):
"""
编码器功能,用于生成均值和对数方差。
:param x: 输入数据。
"""
h = F.relu(self.fc1(x))
h = F.relu(self.fc2(h))
return self.fc31(h), self.fc32(h)
def sampling(self, mu, log_var):
"""
通过重新参数化技巧从标准正态分布中采样。
:param mu: 生成的均值。
:param log_var: 生成的对数方差。
"""
std = torch.exp(0.5 * log_var)
eps = torch.randn_like(std)
return eps.mul(std).add_(mu)
def decoder(self, z):
"""
解码器功能,用于从潜在空间重构输入数据。
:param z: 潜在变量。
"""
h = F.relu(self.fc4(z))
h = F.relu(self.fc5(h))
return torch.sigmoid(self.fc6(h))
def forward(self, x):
"""
VAE模型的前向传递。
:param x: 输入的训练数据数据。
"""
mu, log_var = self.encoder(x.view(-1, 784)) # 将图像展平处理
z = self.sampling(mu, log_var)
return self.decoder(z), mu, log_var
# @staticmethod
# 这意味着该方法不依赖于类的实例,也不修改类的状态。它是类的一部分,但是可以在没有创建类的实例的情况下调用,且不需要self参
def loss_function(self,recon_x, x, mu, log_var):
"""
VAE的损失函数,包括重构损失和KL散度(KLD:Kullback-Leibler divergence)。
:param recon_x: 重构的数据。
:param x: 原始数据。
:param mu: 编码的均值。
:param log_var: 编码的对数方差。
"""
BCE = F.binary_cross_entropy(recon_x, x.view(-1, 784), reduction='sum')
KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
return BCE + KLD
class VAE_TrainMnist:
def __init__(self, model, optimizer,local_data_path='./data/'):
"""
训练和测试VAE模型的类。
:param model: VAE模型。
:param optimizer: 优化器。
: local_data_path : 本地数据路径
"""
self.model = model
self.optimizer = optimizer
self.local_data_path = local_data_path
self.batch_size = 128
# 加载数据集
def load_minist(self):
transform = transforms.ToTensor()
train_dataset = datasets.MNIST(root=self.local_data_path, train=True, transform=transform, download=True)
test_dataset = datasets.MNIST(root=self.local_data_path, train=False, transform=transform)
print('len(train_dataset)',len(train_dataset))
print('len(test_dataset)',len(test_dataset))
self.train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=self.batch_size, shuffle=True)
self.test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=self.batch_size, shuffle=False)
print("数据集加载完成!")
def train(self, epoch,save_image_name="train_sample"):
"""
训练过程。
:param epoch: 当前的训练轮数。
"""
self.model.train() #将导入的模型输入到训练模式
self.load_minist()
train_loss = 0
for batch_idx, (data, _) in enumerate(self.train_loader):
data = data.cuda()
self.optimizer.zero_grad()
recon_batch, mu, log_var = self.model(data)
if batch_idx==0:
print("只在第一次训练时打印,其他时候不打印,防止信息冗余")
print('输入的训练数据:data.tensor.size',data.size())
print("输出recon_batch.shape",recon_batch.shape)
print("输出mu.shape",mu.shape)
print("输出log_var.shape",log_var.shape)
loss = self.model.loss_function(recon_batch, data, mu, log_var)
loss.backward()
train_loss += loss.item()
self.optimizer.step()
if batch_idx % 100 == 0:
print(f'训练轮次: {epoch} [{batch_idx * len(data)}/{len(self.train_loader.dataset)} '
f'({100. * batch_idx / len(self.train_loader):.0f}%)]\t损失: {loss.item() / len(data):.6f}')
save_image(recon_batch.view(self.batch_size, 1, 28, 28), f'./{save_image_name}_{epoch}.png')
torch.save(self.model.state_dict(), f'checkpoint_{epoch}.pth')
print(f'====> 训练轮次: {epoch} 平均损失: {train_loss / len(self.train_loader.dataset):.4f}')
def test(self):
"""
测试过程。
"""
self.model.eval()
test_loss = 0
with torch.no_grad():
for data, _ in self.test_loader:
data = data.cuda()
recon, mu, log_var = self.model(data)
test_loss += self.model.loss_function(recon, data, mu, log_var).item()
test_loss /= len(self.test_loader.dataset)
print(f'====> 测试集损失: {test_loss:.4f}')
if __name__ == '__main__':
vae = VAE(x_dim=784, h_dim1=512, h_dim2=256, z_dim=2)
vae.cuda()
optimizer = optim.Adam(vae.parameters(), lr=1e-3)
trainer = VAE_TrainMnist(vae, optimizer,local_data_path='./data/')
# trainer.load_minist() #
for epoch in range(1, 3):
trainer.train(epoch,save_image_name="train_sample")
trainer.test()
输出 (为演示只训练3个,可以多训练几个)
len(train_dataset) 60000
len(test_dataset) 10000
数据集加载完成!
只在第一次训练时打印,其他时候不打印,防止信息冗余
输入的训练数据:data.tensor.size torch.Size([128, 1, 28, 28])
输出recon_batch.shape torch.Size([128, 784])
输出mu.shape torch.Size([128, 2])
输出log_var.shape torch.Size([128, 2])
训练轮次: 1 [0/60000 (0%)] 损失: 546.049500
训练轮次: 1 [12800/60000 (21%)] 损失: 183.680786
训练轮次: 1 [25600/60000 (43%)] 损失: 178.807480
训练轮次: 1 [38400/60000 (64%)] 损失: 168.790909
训练轮次: 1 [51200/60000 (85%)] 损失: 167.150360
====> 训练轮次: 1 平均损失: 182.9290
====> 测试集损失: 164.0699
训练轮次: 2 [0/60000 (0%)] 损失: 159.409363
训练轮次: 2 [12800/60000 (21%)] 损失: 161.341766
训练轮次: 2 [25600/60000 (43%)] 损失: 155.624207
训练轮次: 2 [38400/60000 (64%)] 损失: 156.475525
训练轮次: 2 [51200/60000 (85%)] 损失: 157.767914
====> 训练轮次: 2 平均损失: 159.2507
====> 测试集损失: 156.2279

二、VAE原理探究和简易推导
核心参考:台大李宏毅教授ppt:https://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Lecture/VAE%20(v5).pdf
2.1 vae模型训练架构图 (训练目的:重构出训练样本+解码器输入趋近于正态分布)
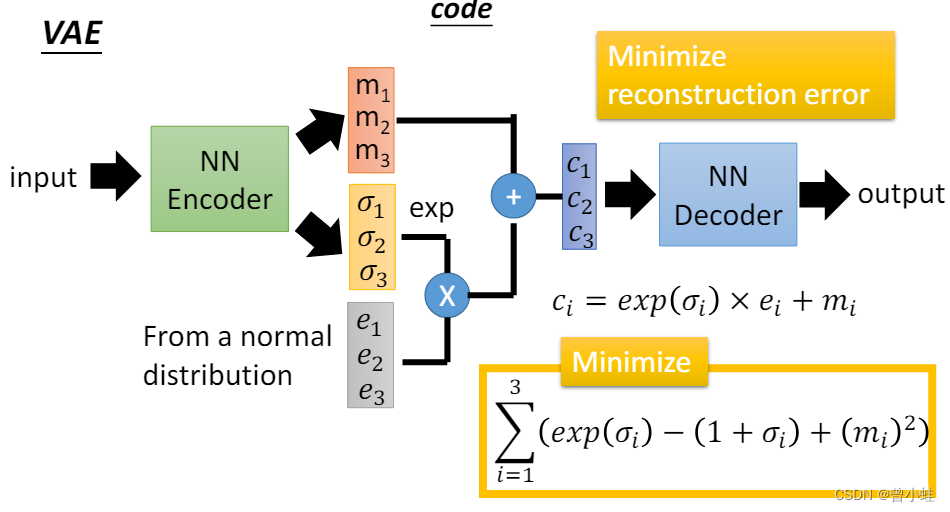
训练过程中,输入训练图片(batch,图片H*W),
编码器输出最终的结果 recon_batch, 编码器输出中间变量 mu, log_var
其中编码器和解码器的神经网络实现结构有区别,但是输出变量的个数,意义差别不大
NN Encoder输出
c
i
=
exp
(
σ
i
)
×
e
i
+
m
i
c_i = \exp(\sigma_i) \times e_i + m_i
ci=exp(σi)×ei+mi 表示根据编码器输出来计算
c
c
c,这里代码z等同,实际代码计算时有差异
Minimize部分:
核心loss, 保证了编码器输出值,经过重采样后近似接近标准正态分布,所以我们再生成的时候,可以直接z~(0,1)采样解码得到生成图像。(下图中sim表示两个分布的相似度,也可以用KL散步来表示)
2.2 VAE 中的 KL 散度(KL Divergence)从零推导(最大化对数似然函数)
变分自编码器的目标是最大化观测数据的对数似然函数,即:
P ( x ) = ∫ P ( z ) P ( x ∣ z ) d z P(x) = \int P(z) P(x|z) \, dz P(x)=∫P(z)P(x∣z)dz
其中:
- P ( z ) P(z) P(z) 是潜在变量 ( z ) 的先验分布, 表示在没有任何观测数据 x 的情况下,对潜在变量 z 的先验知识通常假设,这里为标准正态分布 N ( 0 , I ) \mathcal{N}(0, I) N(0,I)。
- P ( x ∣ z ) P(x|z) P(x∣z) 是给定潜在变量 z z z 时,生成观测数据 x x x的概率分布。
这整个公式表示的是,观测数据 𝑥的概率可以通过对所有可能的潜在变量 𝑧进行求和(积分)
对数似然函数为:
L = ∑ x log P ( x ) L = \sum_x \log P(x) L=x∑logP(x)
引入变分分布 q ( z ∣ x ) q(z|x) q(z∣x)
由于直接计算 P(x)是不可行的,我们引入一个变分分布 ( q(z|x) ) 来近似后验分布 ( P(z|x) )。
对数似然可以写成:
log P ( x ) = ∫ q ( z ∣ x ) log P ( x ) d z \log P(x) = \int q(z|x) \log P(x) \, dz logP(x)=∫q(z∣x)logP(x)dz
使用 ( q(z|x) ) 重写对数似然
通过将对数似然展开并使用 ( q(z|x) ) 重写,我们得到:
log P ( x ) = ∫ q ( z ∣ x ) log P ( z , x ) P ( z ∣ x ) d z \log P(x) = \int q(z|x) \log \frac{P(z, x)}{P(z|x)} \, dz logP(x)=∫q(z∣x)logP(z∣x)P(z,x)dz
其中 ( P(z, x) = P(x|z) P(z) ),所以公式可以写为:
log P ( x ) = ∫ q ( z ∣ x ) log P ( x ∣ z ) P ( z ) P ( z ∣ x ) d z \log P(x) = \int q(z|x) \log \frac{P(x|z) P(z)}{P(z|x)} \, dz logP(x)=∫q(z∣x)logP(z∣x)P(x∣z)P(z)dz
分解对数似然
进一步分解对数似然:
log P ( x ) = ∫ q ( z ∣ x ) log ( P ( x ∣ z ) P ( z ) q ( z ∣ x ) q ( z ∣ x ) P ( z ∣ x ) ) d z \log P(x) = \int q(z|x) \log \left( \frac{P(x|z) P(z)}{q(z|x)} \frac{q(z|x)}{P(z|x)} \right) \, dz logP(x)=∫q(z∣x)log(q(z∣x)P(x∣z)P(z)P(z∣x)q(z∣x))dz
将对数拆分为两部分:
log P ( x ) = ∫ q ( z ∣ x ) log P ( x ∣ z ) P ( z ) q ( z ∣ x ) d z + ∫ q ( z ∣ x ) log q ( z ∣ x ) P ( z ∣ x ) d z \log P(x) = \int q(z|x) \log \frac{P(x|z) P(z)}{q(z|x)} \, dz + \int q(z|x) \log \frac{q(z|x)}{P(z|x)} \, dz logP(x)=∫q(z∣x)logq(z∣x)P(x∣z)P(z)dz+∫q(z∣x)logP(z∣x)q(z∣x)dz
第一项:
∫ q ( z ∣ x ) log P ( x ∣ z ) P ( z ) q ( z ∣ x ) d z \int q(z|x) \log \frac{P(x|z) P(z)}{q(z|x)} \, dz ∫q(z∣x)logq(z∣x)P(x∣z)P(z)dz
是证据下界(ELBO)。
第二项:
∫ q ( z ∣ x ) log q ( z ∣ x ) P ( z ∣ x ) d z = D KL ( q ( z ∣ x ) ∥ P ( z ∣ x ) ) \int q(z|x) \log \frac{q(z|x)}{P(z|x)} \, dz = D_{\text{KL}} (q(z|x) \| P(z|x)) ∫q(z∣x)logP(z∣x)q(z∣x)dz=DKL(q(z∣x)∥P(z∣x))
是 KL 散度。
证据下界(ELBO)
由于 KL 散度 D KL ( q ( z ∣ x ) ∥ P ( z ∣ x ) ) D_{\text{KL}} (q(z|x) \| P(z|x)) DKL(q(z∣x)∥P(z∣x))总是非负的,因此我们有:
log P ( x ) ≥ E q ( z ∣ x ) [ log P ( x ∣ z ) ] − D KL ( q ( z ∣ x ) ∥ P ( z ) ) \log P(x) \geq \mathbb{E}_{q(z|x)} [\log P(x|z)] - D_{\text{KL}} (q(z|x) \| P(z)) logP(x)≥Eq(z∣x)[logP(x∣z)]−DKL(q(z∣x)∥P(z))
这一不等式被称为证据下界(ELBO),记作 ( L_b ):
L b = E q ( z ∣ x ) [ log P ( x ∣ z ) ] − D KL ( q ( z ∣ x ) ∥ P ( z ) ) L_b = \mathbb{E}_{q(z|x)} [\log P(x|z)] - D_{\text{KL}} (q(z|x) \| P(z)) Lb=Eq(z∣x)[logP(x∣z)]−DKL(q(z∣x)∥P(z))
2.3 KL 散度公式的进一步化简 (得到loss函数)!
为了推导 KL 散度,我们需要具体定义 ( q(z|x) ) 和 ( p(z) ) 的形式。在 VAE 中,通常选择以下形式:
- ( q(z|x) = \mathcal{N}(z; \mu(x), \sigma^2(x)) )
- ( p(z) = \mathcal{N}(z; 0, I) )
KL 散度的计算公式为:
D KL ( N ( μ , σ 2 ) ∥ N ( 0 , I ) ) = 1 2 ∑ i = 1 d ( σ i 2 + μ i 2 − log σ i 2 − 1 ) D_{\text{KL}} \left( \mathcal{N}(\mu, \sigma^2) \| \mathcal{N}(0, I) \right) = \frac{1}{2} \sum_{i=1}^{d} \left( \sigma_i^2 + \mu_i^2 - \log \sigma_i^2 - 1 \right) DKL(N(μ,σ2)∥N(0,I))=21i=1∑d(σi2+μi2−logσi2−1)
具体推导过程如下:
- KL 散度的定义:
D KL ( q ∥ p ) = ∫ q ( z ) log q ( z ) p ( z ) d z D_{\text{KL}}(q \| p) = \int q(z) \log \frac{q(z)}{p(z)} \, dz DKL(q∥p)=∫q(z)logp(z)q(z)dz
- 代入具体的高斯分布形式:
q ( z ∣ x ) = N ( z ; μ , σ 2 ) , p ( z ) = N ( z ; 0 , I ) q(z|x) = \mathcal{N}(z; \mu, \sigma^2), \quad p(z) = \mathcal{N}(z; 0, I) q(z∣x)=N(z;μ,σ2),p(z)=N(z;0,I)
- 计算对数概率密度函数:
log q ( z ∣ x ) = − 1 2 ( d log ( 2 π ) + log ∣ Σ ∣ + ( z − μ ) T Σ − 1 ( z − μ ) ) \log q(z|x) = -\frac{1}{2} \left( d \log(2\pi) + \log|\Sigma| + (z - \mu)^T \Sigma^{-1} (z - \mu) \right) logq(z∣x)=−21(dlog(2π)+log∣Σ∣+(z−μ)TΣ−1(z−μ))
log p ( z ) = − 1 2 ( d log ( 2 π ) + log ∣ I ∣ + z T z ) \log p(z) = -\frac{1}{2} \left( d \log(2\pi) + \log|I| + z^T z \right) logp(z)=−21(dlog(2π)+log∣I∣+zTz)
- 代入 KL 散度公式并化简:
D KL ( q ( z ∣ x ) ∥ p ( z ) ) = E q ( z ∣ x ) [ log q ( z ∣ x ) − log p ( z ) ] D_{\text{KL}} \left( q(z|x) \| p(z) \right) = \mathbb{E}_{q(z|x)} \left[ \log q(z|x) - \log p(z) \right] DKL(q(z∣x)∥p(z))=Eq(z∣x)[logq(z∣x)−logp(z)]
= E q ( z ∣ x ) [ − 1 2 ( log ∣ Σ ∣ + ( z − μ ) T Σ − 1 ( z − μ ) − log ∣ I ∣ − z T z ) ] = \mathbb{E}_{q(z|x)} \left[ -\frac{1}{2} \left( \log|\Sigma| + (z - \mu)^T \Sigma^{-1} (z - \mu) - \log|I| - z^T z \right) \right] =Eq(z∣x)[−21(log∣Σ∣+(z−μ)TΣ−1(z−μ)−log∣I∣−zTz)]
= 1 2 ( tr ( Σ ) + μ T μ − d − log ∣ Σ ∣ ) = \frac{1}{2} \left( \text{tr}(\Sigma) + \mu^T \mu - d - \log |\Sigma| \right) =21(tr(Σ)+μTμ−d−log∣Σ∣)
对于对角协方差矩阵 ( \Sigma = \text{diag}(\sigma^2) ),上式化简为:
= 1 2 ∑ i = 1 d ( σ i 2 + μ i 2 − log σ i 2 − 1 ) = \frac{1}{2} \sum_{i=1}^{d} \left( \sigma_i^2 + \mu_i^2 - \log \sigma_i^2 - 1 \right) =21i=1∑d(σi2+μi2−logσi2−1)
对应实际实现中的 KL 散度
在实际实现中,编码器输出的是对数方差 ( \log(\sigma^2) ),记为 log_var。KL 散度的代码实现为:
KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











