







这节课主要是关于总体情况的一个介绍。集中在机器学习可以处理怎样的问题上。
在模型方面进行分类,主要是根据需要预测的结果进行分类
1)首先从PLA算法可以知道机器学习可以进行二元分类。类似得,也可以进行多元分类,预测多个可能有多个结果的数据集的结果。即binary classification和multiclass classfication
2)另外也可以做回归分析,通过各项特征得到一个数量值。上面的这种需要预测的结果是一个categorical的结果,而下面则是需要预测一个quantitative的结果
3)在课程中还提到了结构学习,举的例子通过将语言中的名词、动词等分类,获取了语言的基本结构。
另一方面,机器学习算法根据学习的方式(algorithm)的情况可以分成以下几种
1)监督学习,训练集中的每个x都有一个对应的y,希望得到的结果能够尽量满足通过给定的x可以得到y
2)非监督学习,主要是聚类
另外还有半监督学习,即其中部分x有对应的y。
3)强化学习(也许算是半监督的一种),其方式是给得到的结果打分,以此对hypothesis进行反馈。个人感觉类似于监督学习,但这里没有结果y,只有对于预测结果的一个评分。
最后根据训练集的使用方式分为batch和online等类型
batch类型是一次过进行批量训练,而online则是每次可以仅将训练集中的一组数据输入进行训练。显然PLA属于online的一类。
另外还有active类型,其与以上的区别是有选择地对y进行访问,感觉有些类似于半监督学习,只不过在这个场景下是根据算法确认是否需要对结果y进行query,然后自行querry。感觉active类型有些类似于有目的性的抽样,可以在互联网的某些业务场景中使用。
Lesson 4
这节课主要是在论证为何可以利用已知的数据集推导未知数据集中的情况,个人认为这里主要是在为supervised learning 提供理论基础
通过一些简单的例子,如

我们可以得到机器学习的需求之一,是从当前已有数据集的情况总结出一个目标映射关系g。好的g应该是适用于尽可能多的x,使得到的y=g(x),与我们理想的映射关系f得到的结果尽可能的接近。在上节课中,以及其他的可能算法中,我们已经能确定目标映射g在训练集中与映射关系f尽可能的接近。那么如何确保其可以推广到非训练集中的x-y对中呢?其基础就是抽样统计。
从简答的抽样统计开始:假设一个盒子中有绿球和橙球,要推断其橙色球所占的比例,而且不能将球全部取出来
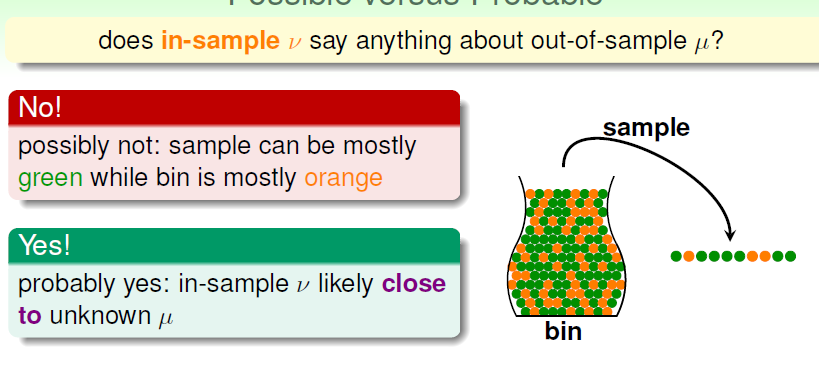
虽然抽样所得到的橙球比例并非与盒子中总体的比例情况一定相同,依然存在抽样中得到绿色占大多数而盒子中橙色占大多数的情况,但抽样得到的比例情况和总体情况有很大概率是接近的。
这一点在数学上由霍夫丁不等式给出

霍夫丁不等式说明,抽样比例v与总体比例u的差距大于某个边距值e的概率,小于一个由e和样本大小N得到的关系式的值。(在这里我们将右边的关系式定义为Plarge,在后面用到)
显然如果抽样样本数N越大,那么抽样比例和总体比例有比较大的差距的可能性越小。这与我们的直观感觉相符。
因此在抽样样本足够大的情况下,我们可以说抽样比例v和总体比例u之间v=u的关系是大致接近正确的(probably approximately correct,PAC)
将以上对于抽样统计的论证推广到机器学习中,是这样的一个过程:
在机器学习的问题中,对于某个假设h,在将其推广到非训练集中时,我们讨论的是h(x)=f(x)或h(x)<>f(x)的比例。在这里我们得到的训练数据集则相当于抽样的样本。类似于上面的陈述,当样本总量N足够大的时候,训练集中的h(x)<>f(x)的比例v将和非训练集中的h(x)<>f(x)的比例u将十分接近(将h(x)<>f(x)类比为橙色的球)。在这个时候,能使h(x)<>f(x)的比例Ein=v小的hypothesis,对非训练集中的x也有一个小错误比例的Eout=u。而这就是一个比较好的结果映射关系,因为它与理想的映射关系f得到的结果是接近的。
以上说明了,对于单个假设,如果它在训练集中得到的结果与理想映射f的结果接近,那么它在非训练集中也很有可能得到与理想映射f十分接近的结果。
虽然对于单个hypothesis,其样本集错误率和非样本数据错误率相等(u=v,Ein=Eout)来说是PAC(probably correct)的,然而我们需要在多个hypothesis中进行选择。当hypothesis数量较大时,即使对单个hypothesis,Ein与Eout差距大的概率较小,依然可能会出现Ein与Eout差距大的hypothesis。
对于使某个hypothesis Ein与Eout差距较大的数据集D,我们说D对于Hypothesis h来说一个坏数据集。
对于某个数据集D和一组hypothesis H{h1,h2,h3,....},其遇到坏数据集(|v-u|>e,e为指定的某个边距值,类似霍夫丁不等式)的概率上限可以由出以下关系式的推导得出
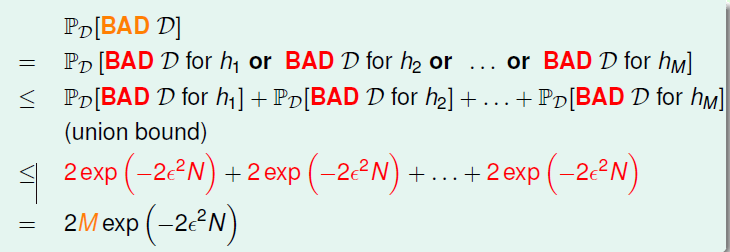
即某个数据集D与某组hypothesis H遇到含有|v-u|>e的情况的概率不大于每个hypothesis的Plarge的和,最终相当于是hypothesis数量乘以Plarge的结果。(Plarge见前面对于单个假设的论证)
由此我们依然可以得到一个与假设集大小M,数据集大小N和边距e有关的一个上限。当M和e限定的时候,通过选择一个有足够数据量的数据集,依然可以避免“坏数据”的出现,来保证Ein=Eout大致接近正确(probably approximate correct,PAC)。在以上情况下,可以使用有最低Ein的假设作为最终的目标映射g。
然而在大多数时候,可以供我们选择的假设集H的大小M是趋于无穷的,在这个时候以上式子需要进一步的证明。
在下节课中将讲解当假设集大小M趋于无穷时,如何扩展以上式子,以建立假设集较大的监督式学习的理论基础。
总结:
机器学习按训练后输出的结果划分可以分为二元分类、多元分类、回归和结果学习。
按algorithm对训练集的需求可以划分为监督学习、非监督学习、半监督学习与强化学习。
按algorithm对训练集的使用方式可以分为batch与online两种方式。(目前已知的许多supervised learning同时也是online,unsupervised是batch。auto-encoder也许算是unsupervised中的一个特例)。
在统计学中我们通过霍夫丁不等式来限定抽样集与总体集中的频率与概率关系。通过将其推广到机器学习中,可以得到类似的单个hypothesis的Ein与Eout差距限定不等式。然而当考虑到一组hypothesis数量多的假设集时,即使对单个hypothesis遇到bad data使其Ein与Eout差别比较大的概率十分低,但总体而言其中有一个或几个hypothesis遇到bad data使其Ein与Eout差别较大的概率依然无法保证。因此通过union bound我们讲假设集中假设的数量M通过union bound引入不等式中,最终得到在有限的假设数量时,只要样本数量N足够,我们依然能让这组data保证取到的hypothesis的Ein与Eout差距不大,从而可以挑选Ein最小的hypothesis,也即Eout最小的hypothesis,作为结果。















 457
457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









