







文章目录
上文链接:
graph embedding第一篇——deepwalk and line
graph embedding 第二篇 node2vec and sdne
参考
graph embedding
深度学习中不得不学的Graph Embedding方法
Embedding从入门到专家必读的十篇论文
DNN论文分享 - Item2vec
从KDD 2018最佳论文看Airbnb实时搜索排序中的Embedding技巧
Negative-Sampling Word-Embedding Method
推荐系统遇上深度学习(四十四)-Airbnb实时搜索排序中的Embedding技巧
理论优美的深度信念网络,Hinton老爷子北大最新演讲
Item2Vec
Item2Vec-Neural Item Embedding for Collaborative Filtering
这篇文章是微软在2016年发表的文章,文章思路也比较简单。Item2vec相当于把用户浏览的商品集合等价于Word2vec中的句子。
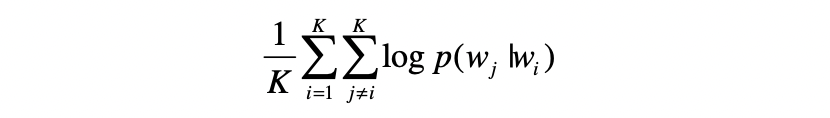
利用负采样,得到:
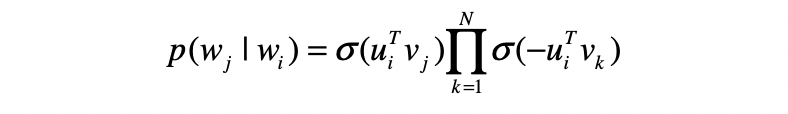
本篇的想法非常简单,就是将用户行为序列看成是句子,然后应用word2vec计算embedding。
Airbnb Embedding
本论文获得了2018 年 KDD ADS track 的最佳论文,主要介绍了机器学习的Embedding在 Airbnb 爱彼迎房源搜索排序和实时个性化推荐中的实践。
Real-time Personalization using Embeddings for Search Ranking at Airbnb
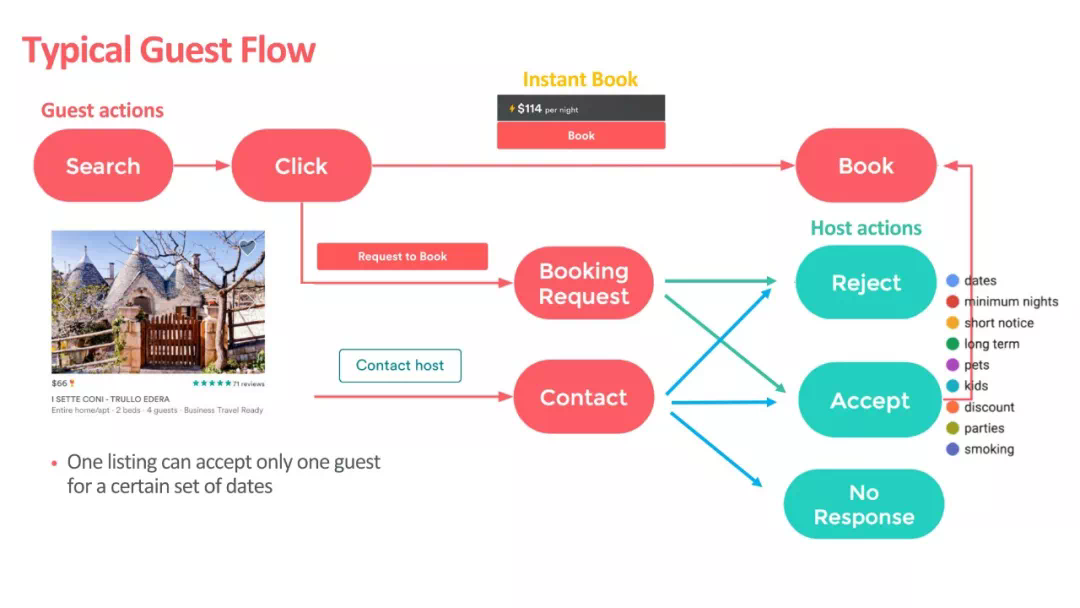
上图为Airbnb的交互方式,可以看出Airbnb是一个可以双向选择的平台,用户可以选择自己心仪的房子进行预订,房东也有权利拒绝你的预订。Airbnb团队建立模型时,既考虑用户的短时兴趣,又考虑用户的长期兴趣。
- 短时兴趣: 用户在一个session中表现出得兴趣。
- 长期兴趣: 用户在其所有历史行为中表现得兴趣。
List Embedding:
这一部分主要是获取用户的短时兴趣,即用户在session中表现出来的兴趣,通过用户在session中的点击序列得到。对session的定义如下:
- 每次点击,用户需要至少在页面上停留30s,否则被视为误点击,不进行考虑;(清洗噪点和非相关信号)
- 用户前后两次点击时间间隔大于30min,作为切割session的依据。(避免非相关序列的产生)
这一部分的目标是,对于任一list中的元素 l i l_i li,希望训练出一个 v l i v_{l_i} vli,使得相似的list在嵌入空间中更为接近。
使用word2vec的skip-gram作为框架,那么其损失函数为:

这样的计算量太大了,因为房源
∣
V
∣
|V|
∣V∣总数是一个很大的值。
因此,采用word2vec的negative sampling方法,负样本则是在确定 central listing 后随机从语料库(这里就是 listing 的集合)中选取一个 listing 作为负样本:
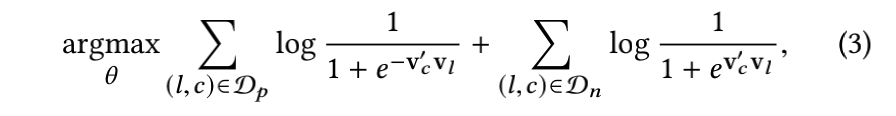
这一步具体的推导可看附录部分。
在原始 word2vec embedding 的基础上,针对其业务特点,Airbnb 的工程师希望能够把 booking 的信息引入 embedding。这样直观上可以使 Airbnb 的搜索列表和 similar item 列表中更倾向于推荐之前 booking 成功 session 中的listing。
从这个 motivation 出发,Airbnb 把 click session 分成两类,最终产生 booking 行为的叫 booked session,没有的称做 exploratory session。

为了更好的发现同一市场(marketplace)内部 listing 的差异性,Airbnb 加入了另一组 negative sample,就是在 central listing 同一市场的 listing 集合中进行随机抽样,获得一组新的 negative samples,其中
D
m
n
D_{mn}
Dmn就是同一地区的房源的集合:

对于新房源,选择3个同种类且距离最近(但是要在半径10miles以内)的3个房源,并用其embedding的平均值来作为新房源的embedding。
User Type & Listing Type Embedding
这里主要为了捕获长期兴趣,比如用户在B地找房源,可以通过用户在A地预订过的房源信息进行推荐,我们可以通过list embedding得到的embedding信息,找到最相关的进行推荐。但实际上,各个地区的embedding在语义上比较割裂,因为很少有人一个session跨屏浏览多个地区的房源信息,所以使用不同用户在不同城市的预订行为,来学习不同城市房源的相似性。
但是,这其中有一些数据问题:
1)预订序列数据相比于点击序列数据,是非常少的
2)许多用户只有过一次预订行为,这种的session是不能拿来用的
3)为了学习一个比较有效的embedding,房源至少要出现5-10次,但是有许多房源无法达到这样的标准
4)如果序列中两次预订的时间间隔过长的话,用户的偏好是会发生改变的。
前三条总结来说,就是数据少,但是房源多。这样,我们不去学习每个具体房源的embedding,我们把房源进行归类,学习每一类房源的embedding。而为了解决第四个问题,我们把用户type考虑进来。
这样,原来的一条预订序列,此时变为了:(utype1,ltype1,utype2,ltype2,…,utypeM,ltypeM)。这样,尽管用户的偏好随时间改变了,这种改变就体现在了user type的不断变化上。
其归类的规则如下:

目标函数类似skip-gram,当中心是一个user-type时,最大化目标函数:

当中心是一个list-type时,最大化目标函数:

这样做,使得user-type和list-type的embedding属于同一个空间,可以直接计算相似度。
接下来,考虑将房东的拒绝信息带入到其中,作为明显的负样本信息:

从而训练得到user type embedding和list type embedding。
EGES算法
Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
Base graph embedding

在博文graph embedding第一篇——deepwalk and line中,已经详细介绍了deepwalk方案。我们只需知道阿里如何构建上图(b)便可以通过deepwalk得到最终的embedding结果。
(a)表示3个用户购买过的商品,并按照时间顺序做了排列,比如用户U1先后购买了D A B三个商品。这里有一个业务上的技巧,就是把用户在某个时间窗内的连续行为作为一个session,例如一个小时,如果超过时间窗,就划分为不同的session。通常在短周期内访问的商品更具有相似性。根据购买顺序构建有向图。 e d g e i j edge_{ij} edgeij记录了从商品i到商品j的出现次数,计算商品的转移概率,并根据转移概率做游走,生成商品序列,如( c )所示。转移概率为:

Graph Embedding with Side Information
该方案增加 item 的额外信息(例如category, brand, price等)丰富 item 表征力度。而且base graph embedding不能表达新顶点的信息,加入side information为其提供了可能。其架构如下:
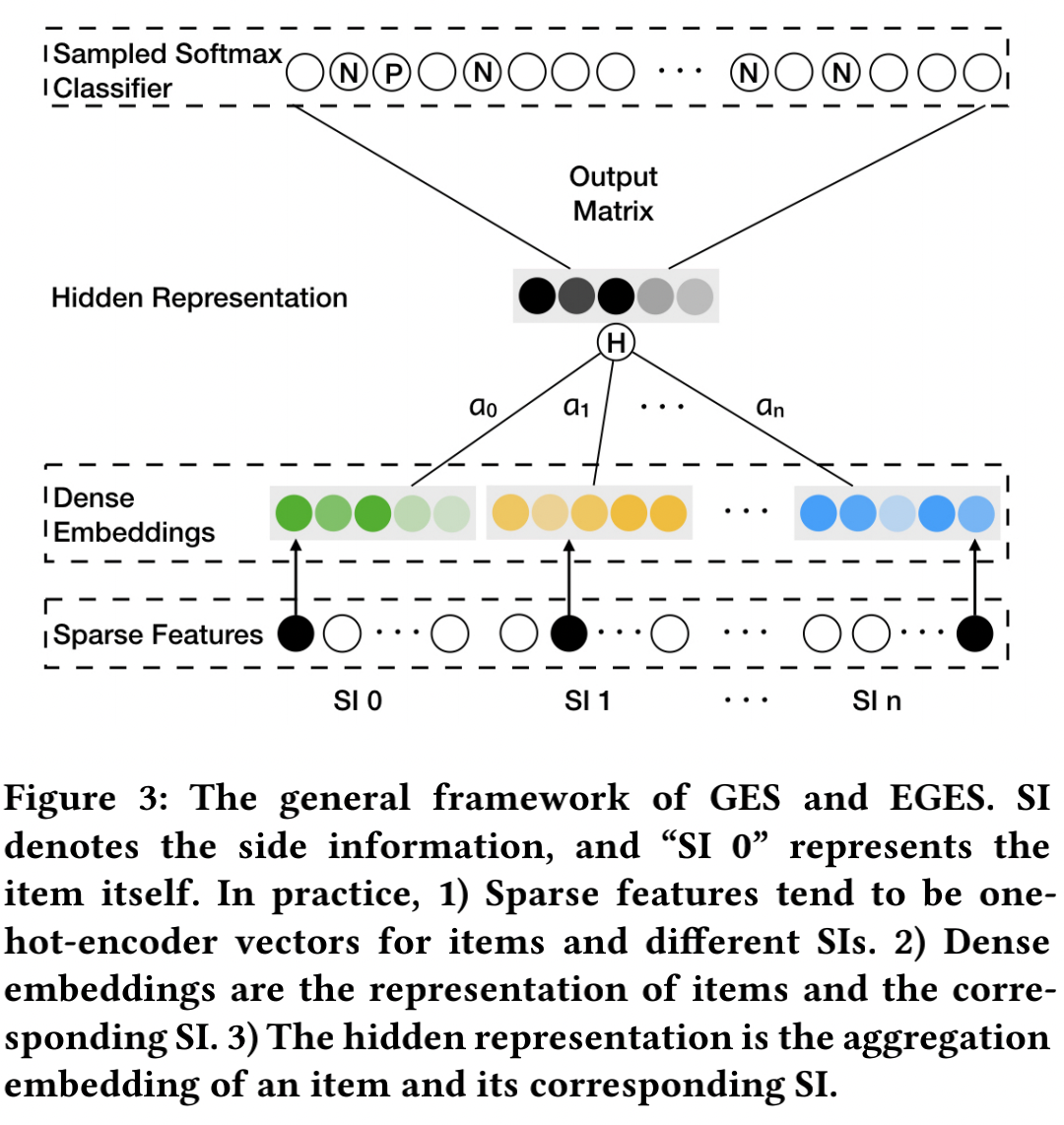
这里的side information意为物品的边信息,比如说:商品品类、价格、商店等信息。SI相似的商品,在向量空间中也应该接近。在Sparse Features中,
S
I
0
SI_0
SI0表示商品本身的one-hot特征,
S
I
1
SI_1
SI1 到
S
I
n
SI_n
SIn表示n个边信息的one-hot特征,阿里采用了13种边信息特征。将每个特征进行embedding,其中
W
v
0
W_v^0
Wv0表示item v的embedding,
W
v
s
W_v^s
Wvs表示item v 的第s个side information的embedding,取平均得到
H
v
H_v
Hv,接下来的步骤与上一节相同。
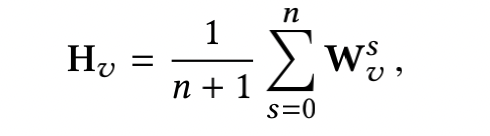
Enhanced Graph Embedding with Side Information
取平均还是显得太粗糙了,因为不同的边信息对于商品的向量可能会有不同的贡献。因此,可以另外学习一个权重矩阵
A
A
A:
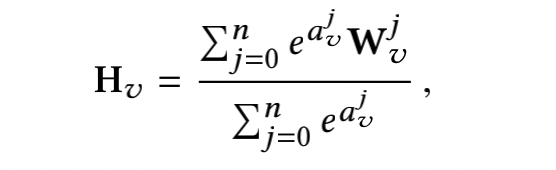
取
e
e
e的指数是因为需要让其权重均大于0。
目标函数为:

具体算法如下:


附录
skip-gram negtive sampling explain
对于word2vec的skip-gram模型而言,目标是最大化:
这一步可以简写为:
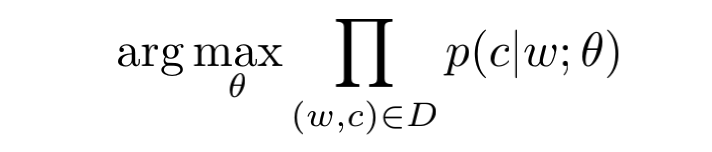
这个条件概率实际上为softmax:
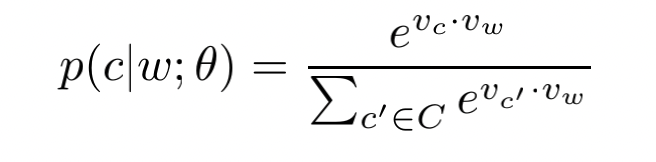
将损失函数变为对数损失,则我们有:

计算量巨大,考虑采用negative sampling采样。考虑
p
(
D
=
1
∣
w
,
c
)
p(D=1|w,c)
p(D=1∣w,c)是
(
w
,
c
)
(w,c)
(w,c)出自语料库的概率,反之
p
(
D
=
0
∣
w
,
c
)
p(D=0|w,c)
p(D=0∣w,c) 是
(
w
,
c
)
(w,c)
(w,c)不出自语料库的概率。我们希望最大化
∏
p
(
D
=
1
∣
w
,
c
)
\prod p(D=1|w,c)
∏p(D=1∣w,c),使得观察到的
(
w
,
c
)
(w,c)
(w,c)均出自语料库D。那么我们有:

而
p
(
D
=
1
∣
w
,
c
)
p(D=1|w,c)
p(D=1∣w,c)的概率可以由sigmoid计算:

同样的,我们希望最大化
∏
p
(
D
=
0
∣
w
,
c
)
\prod p(D=0|w,c)
∏p(D=0∣w,c),使得未观察到的
(
w
,
c
)
(w,c)
(w,c)均出自语料库D’。结合起来我们有:
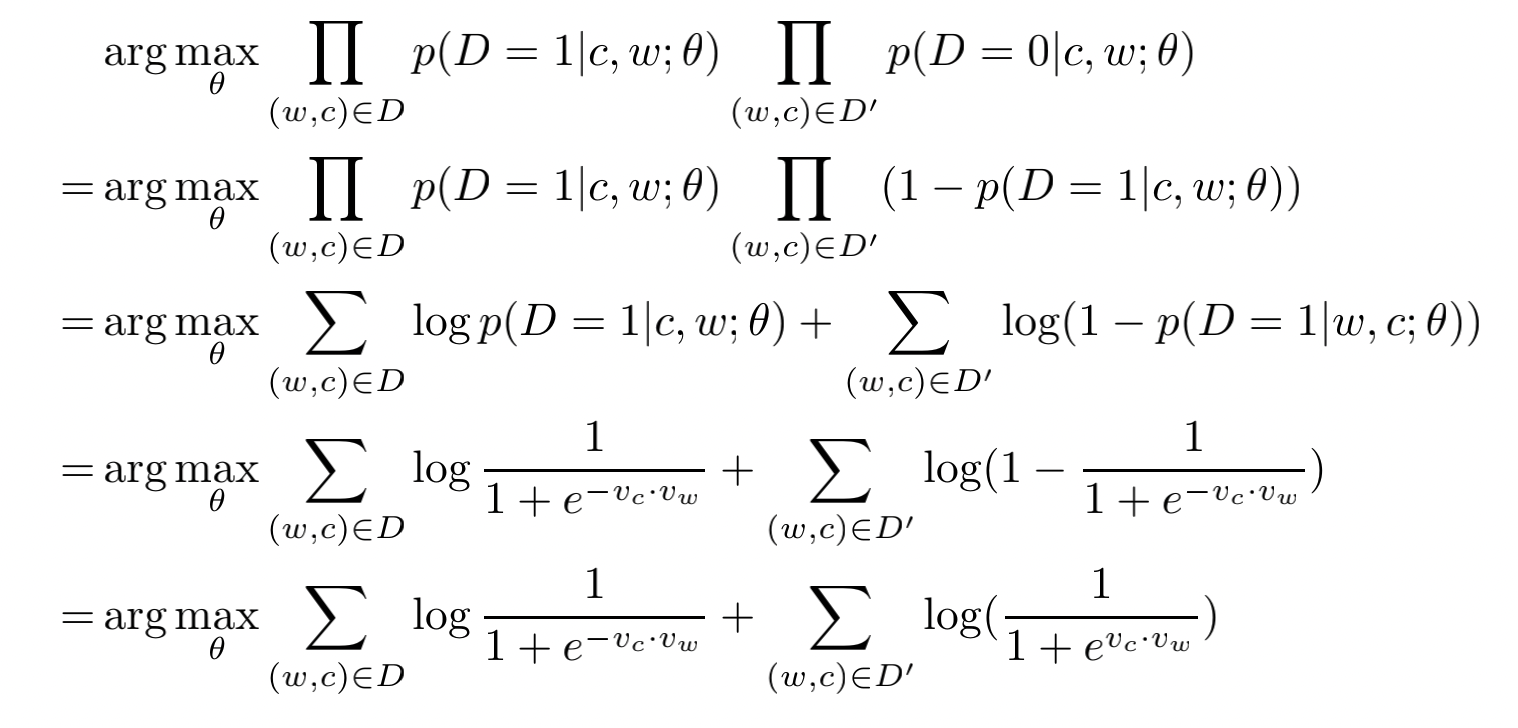
















 4421
4421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









