









数据科学 5.1 数据处理(概念)
一、数据库基础
1、基本概念
- 关系型数据库:将世界抽象为实体和关系,实体包括物和事件。(一张二维表中存放着实体的集合,“行”为一个实体,“列”为属性和特征。表与表之间通过逻辑关系相连。)
- 主键与外键: 主键: 指该表中唯一确定每条记录的一个变量或多个变量的组合,它具有无缺失、 无重复的特征。经常用于(数据清洗)和(数据横向合并)。外键: 是另一张表中与这张表的某个字段的类型,字段名相同的字段,一般用作(关联两张或两张以上的数据表)。
- E-R图:
- 实体型(Entity):具有相同属性的实体具有相同的特征和性质,用实体名及其属性名集合来抽象和刻画同类实体;
- 属性(Attribute):实体所具有的某一特性,一个实体可由若干个属性来画。
- 联系(Relationship):联系也称关系,信息世界中反映实体内部或实体之间的联系。
- 联系可分为以下 3 种类型:
- (1) 一对一联系(1 ∶1)
例如,一个部门有一个经理,而每个经理只在一个部门任职,则部门与经理的联系是一对一的。 - (2) 一对多联系(1 ∶N)
例如,某校教师与课程之间存在一对多的联系,即每位教师可以教多门课程,但是每门课程只能由一位教师来教 - (3) 多对多联系(M ∶N)
- (1) 一对一联系(1 ∶1)
- 表的关系:数据的实体-关系图(ER图)

二、数据整合与数据清洗
1、数据整合
1.1SQL语句介绍
- SQL语句的动词只有九条
| 名称 | 动词 |
|---|---|
| 数据定义DDL | CREATE,DROP, ALTER |
| 数据查询DQL | SELECT |
| 数据操纵DML | INSERT, UPDATE, DELETE |
| 数据控制DCL | GRANT, REVOTE |
SELECT数据查询是最核心和常用的操作。

一般格式
SELECT [ALL | DISTINCT] <目标列表达式> [别名] [,
<目标列表达式> [别名] ]…
FROM <表名或视图名>[, <表名或视图名>]…
[WHERE <条件表达式>]–
[GROUP BY <列名1>
[HAVING <条件表达式> ]]
[ORDER BY <列名2 >[ASC | DESC]];
用WHERE 语句 选择满足特定条件的观测。
- WHERE 语句的一般形式:
- WHERE where-表达式 ;
使用ORDER BY子句对指定行。 - select year,market,sale,profit
from sale
order by year; - 也可以使用变量在SELECT语句中的序号。
select year,market,sale,profit
from sale
order by 1;
- WHERE where-表达式 ;
1.2数据纵向合并
- 并:UNION
- 交:INTERSECT
- 差:EXCEPT

select *
from one
union
select *
from two;
注意, union后面没有跟随all选项,因此剔除重复值。
最后结果:

在pandas中使用concat() 函数完成。
1.3数据横向合并
方法:sql、pandas
横向连接查询基础
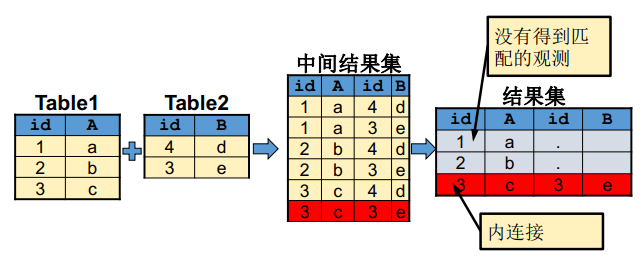
1)、交叉连接(cross join,笛卡尔乘积):查询结果包括两张表观测的所有组合情况,这是SQL实现两表合并的基础,但是极少单独做这种操作;

笛卡尔积

内连接

- 左连接等价于两部分的叠加:内连接+左表中没有匹配的观测。
- 右连接等价于两部分的叠加:内连接+右表中没有匹配的观测。
- 全连接等价于三部分的叠加:内连接+左表中没有匹配的观测+右表中没有匹配的观测。


左 右 全
1.4SQL进行汇总
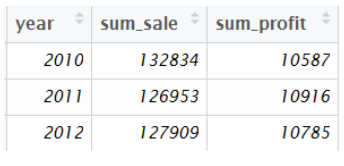
1、对数据分组汇总
select year,
sum(sale) as sum_sale,
sum(profit) as sum_profit
from sale
group by year
- 汇总函数一般和Group by语句同时使用;
- Group by语句出现的变量必须出现在Select语句的最前面,在Oracle 的SQL语句中,不允许Select语句中出现没有在Group by语句出现的变量,也不参与汇总的变量。
2、汇总函数
汇总函数也叫做集函数,包括:
count( [DISTINCT] <列名>)统计一列中值的个数
sum( [DISTINCT] <列名>)计算一列值的总和
avg( [DISTINCT] <列名>)计算一列的平均值
stdev ( [DISTINCT] <列名>)计算一列的标准差
max( [DISTINCT] <列名>)计算一列的最大值
min( [DISTINCT] <列名>)计算一列的最小值
- 例. 获得sale表的总行数。
select count(*) from sale;
3、获取这三年全国销售的平均值:select avg(sale) as all_avg_sale from sale
计算每个地域三年销售的平均值,并与全国数据做比较:
select market,avg(sale) as mavg_sale
from sale
group by market
having mavg_sale<32308
order by mavg_sale

4、使用嵌套语句(子查询)完成:
- 在SQL中可以进行多层嵌套,并且语句从最深的一层开始执行。
- 比如上例中有两层SQL语句, having语句中的select语句为第二层,是最深的,要先运行,其返回的结果为32308,其作为having语句中逻辑判断的常数,这样外层的SQL就可以执行了。
select market,avg(sale) as mavg_sale
from sale
group by market
having mavg_sale<(select avg(sale) as
all_avg_sale from sale)
order by mavg_sale
2、数据清洗
- 脏数据或数据不正确
- 比如 ‘0’ 代表真实的0,还是代表缺失; Age = -2003
- 数据不一致
- 比如收入单位是万元,利润单位是元,或者一个单位是美元,一个是人民币
- 数据重复
- 这个问题在前面已经解决
- 缺失值
- 离群值
- 数据探索识别噪声
- 利用图形可以直观快速地对数据进行初步分析:
• 直方图、饼图、条形图、折线图、散点图等

- 利用图形可以直观快速地对数据进行初步分析:
1.1错误值处理
1、识别错误方法
发现错误值只能通过描述性统计的方法,逐一核实每个变量是否有问题,比如 ‘0’ 代表真实的0,还是代表缺失。
举例:外呼营销数据

(teleco_camp_orig)的当地人均收入(AvgIncome),出现了大量0值,我们有理由怀疑是错误值。可以使用缺失值替代,然后再用缺失值填补的方法处理。
2、处理错误值(明确错误很关键)
- 修正
- 补充正确信息
- 对照其他信息源
- 视为空值
- 删除
- 删除记录
- 删除字段
1.2缺失值处理

1、处理原则
首选基于业务的填补方法,其次根据单变量分析进行填补,多重插补进行所有变量统一填补的方法只有在粗略清洗时才会使用。
- 缺失值少于20%
• 连续变量使用均值或中位数填补。
• 分类变量不需要填补,单算一类即可,或者用众数填补 - 缺失值在20%-80%
• 填补方法同上
• 另外每个有缺失值的变量生成一个指示哑变量,参与后续
的建模 - 缺失值在大于80%
• 每个有缺失值的变量生成一个指示哑变量,参与后续的建
模,原始变量不使用。

2、示例

1.3噪声值处理
1、单变量离群值发现

- 极端值
• 设置标准,如: 5倍标准差之外的数据
• 极值有时意味着错误,应重新理解数据,例如:特殊用户的超大额消费 - 离群值
• 平均值法:平均值±n倍标准差之外的数据- 建议的临界值:
• |SR| > 2 ,用于观察值较少的数据集
• |SR| > 3 ,用于观察值较多的数据集
- 建议的临界值:
- 四分位数法:
• IQR = Q3 – Q1
• Q1 – 1.5 × IQR ~ Q3 + 1.5 × IQR * 更适用于对称分布的数据
2、盖帽法处理
把小于1%的数据用1%的来代替,将大于99%的用99%的来代替

3、分箱法 - 分箱方法通过考察数据的“近邻”来光滑有序数据的值。有序值分布到一些桶或箱中。
• 等深分箱:每个分箱中的样本量一致;(以下为例:9/3=3,每个箱子3个样本)
• 等宽分箱:每个分箱中的取值范围一致。((34-4)/3=10,所以划分点4-14,14-24,。。。)
比如价格排序后数据: 4,8,15,21,21,24,25,28,34

三、数据整理
- FRM提取行为变量
- 数据重组
• 拆分列
• 堆叠列 - 抽样
1、FRM提取行为变量

根据美国数据库营销研究所Arthur Hughes的研究,客户数据库中有三个重要指标:
•最近一次消费(Recency)
最近一次消费意指上一次购买的时间。上一次消费时间越近的顾客对提供即时的商品或是服务也最有可能会有反应。对提供即时的商品或是服务也最有可能会有反应。
•消费频率(Frequency)
消费频率是顾客在限定的期间内所购买的次数。最常购买的顾客,也是满意度最高的顾客。这个指标是“忠诚度”很好的代理变量。
•消费金额(Monetary)
消费金额是最近消费的平均金额。是体现客户短期价值重要变量。如果你的预算不多,而且只能提供服务信息给2000或 3000个顾客,你会将信息邮寄给贡献40%收入的顾客,还是那些不到1%的顾客?数据库营销有时候就是这么简单。这样的营销所节省下来的成本会很可观 。

分析的起点—原始交易记录
无论是超市、电商、制造商、电信公司和银行,总会有一张类似于以下的这张表。其中主要的变量有:订单号、客户编码、订单时间、产生金额和交易类型。这个表“RFM_TRAD_FLOW”

2、数据重组
1、列拆分
继续上一节案例,找出偏爱打折的客户:


•拆分列操作即按组做某个变量的转置,需要告知三个主要变量: 1、分组依据; 2、用于做变量名的列; 3、需要拆分的列; 。
2、堆叠列

3、抽样
•在每个地区随机选择5名客户进行满意度调查
•预期数据格式(部分)

1、分类

- 简单随机抽样(SPS):
从总体中不加任何分组、划类、排队等,完全随机地抽取调查单位。
特点: - 每个样本单位被抽中的概率相等,样本的每个单位完全独立,彼此之间无一定的关联性和排斥性。
- 简单随机抽样是其他各种抽样形式的基础。通常只是在总体单位之间差异程度较小和数目较少时,才采用这种方法。
局限性: - 当总体单位数很大时,就难以实现简单随机抽样,且抽样误差较大
- 分层抽样(STR):
也称类型抽样,总体分成不同的“层”,然后在每一层内进行抽样。
二种方法:
( 1)等数分配法
( 2)等比分配法
例: - 企业按照大中小微型分类
- 对家庭收入分为高收入、中等收入、低收入等
- 系统抽样:
也称等距抽样,其步骤如下:
( 1)按某一标志值的大小将总体单位进行排队并按顺序编号
( 2)根据确定的抽样比例确定抽样间距
( 3)随机确定第一个样本单位
( 4)按顺序总体等间距地抽取其余样本单位 - 系统抽样的随机性主要体现在第一个样本单位的选取上,因此一定要
保证抽取第一个样本单位的随机性。 - 该方法适用于总体情况复杂,各单位之间差异较大,单位较多的情况。
- 多段抽样:
将调查分成两个或两个以上的阶段进行抽样,第一阶段先将总体按照一定的规范分成若干抽样单位,称之为一级抽样单位,再把抽中的一级抽样单位分成若干个二级抽样单位,从抽中的二级抽样单位中再分三级抽样单位等,这样就形成一个多阶段抽样过程,分成若干个
阶段逐步进行。
例:从某省抽取100人组成样本单位
省→市→县—100人 - 放回抽样:
放回抽样又称重复抽样,每次从总体中随机地抽取一个样本单位,观察登记其标准值后又放回总体中,如此进行N次的抽样方法,
特点: - 在重复抽样的过程中,被抽取的总体单位总数始终保持不变,每一次抽样中各总体单位被抽到的机会都相同,每次抽样结果相互独立;
- 每一总体单位都有被重复抽取的可能。
- 不放回抽样:
不放回抽样也称不重复抽样,指被抽到的单位不再放回总体,
每次仅在余下的总体单位中抽取下一个样本的抽样方法。
特点: - 任意总体单位都不会被重复抽到;
- 可以一次抽取所需要的样本单位数。
- 在实际应用中通常采用的都是不重复抽样方法
2、抽样在挖掘中的作用
快速获得数据的基本特征
数据量较大,建模速度较慢
数据不足时
数据平衡
数据分为训练集,测试集,验证集
3、抽样与bagging集成算法
Bagging的基本思路:
第一步:从总体N中重复抽样选取数据集N1,N2,…形成{NI}
第二步:基于{NI},建立统计模型,分别给出每个模型的预测结果
第三步:对结果进行投票
适用范围:
- 训练集之间相互独立,可以并行运行模型















 1106
1106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











