










未完待续。。。。。
GPU操作
二、模型保存读取操作
1、访问模块模型参数
model.parameters()
一个从参数名称隐射到参数Tesnor的字典对象
state_dict
举例1
import torch
from torch import nn
net = MLP() #这里我省略了MLP()的定义,详见《动手学习深度学习Pytorch》对应章节
net.state_dict()
输出1
class MLP(nn.Module):...
OrderedDict([('hidden.weight',
tensor([[-0.1291, -0.4541, -0.0159],
[-0.5555, -0.3319, 0.4285]])),
('hidden.bias', tensor([-0.3046, -0.0209])),
('output.weight', tensor([[-0.4204, 0.4508]])),
('output.bias', tensor([-0.5094]))])
举例2
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
optimizer.state_dict()
输出2
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)...
{'state': {},
'param_groups': [{'lr': 0.001,
'momentum': 0.9,
'dampening': 0,
'weight_decay': 0,
'nesterov': False,
'params': [0, 1, 2, 3]}]}
2、保存加载模型
1)仅保存和加载模型参数(state_dict)(推荐)
保存
torch.save(model.state_dict(), PATH) # 推荐的⽂件后缀名是pt或pth
加载
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
2)保存和加载整个模型
保存
torch.save(model, PATH)
加载
model = torch.load(PATH)
三、网络操作
1、named_children:获取一级子模块及其名字
# named_children获取一级子模块及其名字(named_modules会返回所有子模块,包括子模块的子模块)
for name, blk in net.named_children():
X = blk(X)
print(name, 'output shape: ', X.shape)
输出:
vgg_block_1 output shape: torch.Size([1, 64, 112, 112])
vgg_block_2 output shape: torch.Size([1, 128, 56, 56])
vgg_block_3 output shape: torch.Size([1, 256, 28, 28])
vgg_block_4 output shape: torch.Size([1, 512, 14, 14])
vgg_block_5 output shape: torch.Size([1, 512, 7, 7])
2、torch.cat((p1, p2, p3, p4), dim=1) # 在通道维上连结输出
详见GoogLeNet一节。
torch.cat是将两个张量(tensor)拼接在一起,cat是concatnate的意思,即拼接,联系在一起。
使用torch.cat((A,B),dim)时,除拼接维数dim数值可不同外其余维数数值需相同,方能对齐。
C = torch.cat( (A,B),0 ) #按维数0拼接(竖着拼)
C = torch.cat( (A,B),1 ) #按维数1拼接(横着拼)
3、Global average Pooling
这个概念出自于 network in network ,主要是用来解决全连接的问题,其主要是是将最后一层的特征图进行整张图的一个均值池化,形成一个特征点,将这些特征点组成最后的特征向量进行softmax中进行计算。
参考:https://blog.csdn.net/losteng/article/details/51520555
假如,最后的一层的数据是10个66的特征图,global average pooling是将每一张特征图计算所有像素点的均值,输出一个数据值,这样10 个特征图就会输出10个数据点,将这些数据点组成一个110的向量的话,就成为一个特征向量,就可以送入到softmax的分类中计算了。
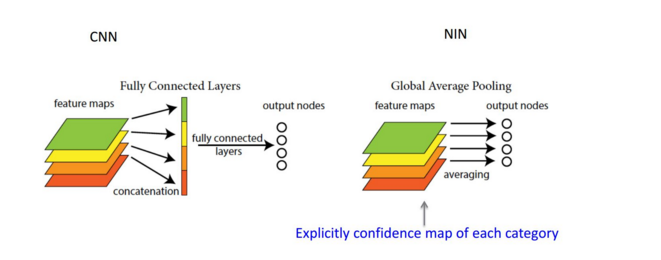
GAP的工作原理:
深度学习基础系列(十)| Global Average Pooling是否可以替代全连接层?

假设卷积层的最后输出是h × w × d 的三维特征图,具体大小为6 × 6 × 3,经过GAP转换后,变成了大小为 1 × 1 × 3 的输出值,也就是每一层 h × w 会被平均化成一个值。
net.add_module("global_avg_pool", d2l.GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, 512, 1, 1)
4、Flatten layer
Convolution卷积层之后是无法直接连接Dense全连接层的,需要把Convolution层的数据压平(Flatten),然后就可以直接加Dense层了。
也就是把 (height,width,channel)的数据压缩成长度为 height × width × channel 的一维数组,然后再与 FC层连接,这之后就跟普通的神经网络无异了。

可以从图中看到,随着网络的深入,我们的图像(严格来说中间的那些不能叫图像了,但是为了方便,还是这样说吧)越来越小,但是channels却越来越大了。在图中的表示就是长方体面对我们的面积越来越小,但是长度却越来越长了。
举例
X = torch.rand((1, 512, 1, 1))
Flatnet = d2l.FlattenLayer()
Flatnet(X).size()
输出
torch.Size([1, 512])
















 765
765











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











