







 本文综述了行为识别领域的数据集和模型发展历程,讨论了面临的挑战,包括数据集构建的难点及模型训练的需求,并介绍了多种行为识别模型和技术。
本文综述了行为识别领域的数据集和模型发展历程,讨论了面临的挑战,包括数据集构建的难点及模型训练的需求,并介绍了多种行为识别模型和技术。
文章目录
0. 前言
- 相关资料:
- 论文基本信息
- 领域:行为识别
- 作者单位:亚马逊
- 发表时间:2020.12
- 一句话总结:从数据集、模型的角度介绍行为识别的发展历程,提供了代码库,探讨了当前的挑战,展望了未来发展趋势。
1. 数据集概述
1.1. 看图说话
-
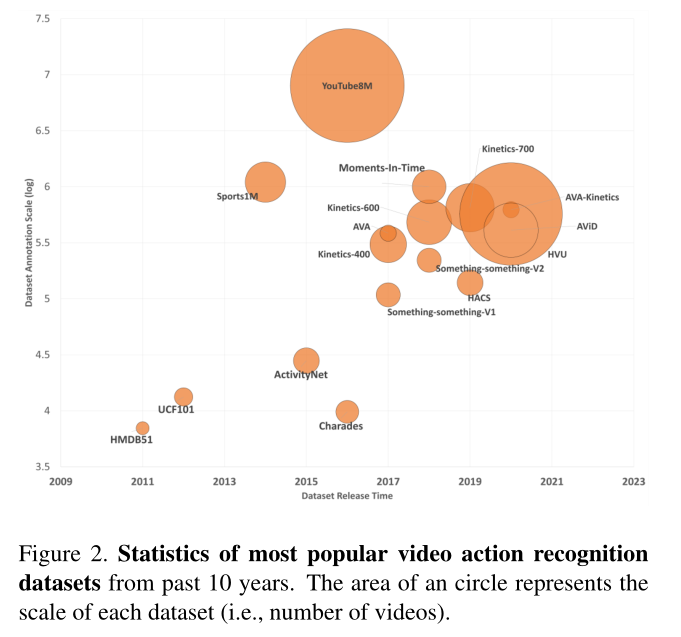
过去10年行为识别数据集概述
- 横坐标是年份
- 纵坐标是label的数量(log级别)
- 源泉的大小是样本数量。
-
1.2. 数据集概述
-
数据集构建流程
- 确定行为类别(从之前的数据库中获取,并根据自己的需求添加)
- 从各个渠道获取视频,例如youtube,一般是在视频的标题中有行为类别名称。
- 手动标注行为的起止时间。
- 最后进行数据清洗(去除重复标注、错误标注等)
-
挑战
- 挑战一:确定行为类别非常麻烦、非常重要。
- 原因在于:人类行为是非常复杂的概念,而且没有良好的层级结构。
- 我自己的理解:行为类别与图片类别的主要区别在于,行为类别属于动词或动名词。
- 动词本身就非常复杂,有些动词存在一词多义的现象。比如“做”,这个字的意思就非常多,做手术、做手表等等。英文中的
take/play啥的,也是很麻烦,很难明确定义。 - 动名词就更复杂了,比如“拿起物品”这个动作,到底拿起手机和拿起水杯算不算一类行为呢?一些场景下属于,一些场景下不属于。
- 而图片分类的目标是“名词”,这一般就比较好分类,也有较好的层级结构。
- 动词本身就非常复杂,有些动词存在一词多义的现象。比如“做”,这个字的意思就非常多,做手术、做手表等等。英文中的
- 挑战二:视频标注相当麻烦
- 需要看整段视频(不像图片,速度快得多)
- 标签很多时候非常模糊,比如对于动作起始/终止位置的确定,也许每个人都有不同的意见。
- 挑战三:数据集本身获取非常困难。
- 数据集都只给链接,需要自己下载,可能每个人能拿到的数据集都不太一样,所以模型比较起来也不是特别的公平。
- 啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊,真的是感同身受。我现在属于苦尽甘来了,刚开始的时候真的痛苦。
- 挑战一:确定行为类别非常麻烦、非常重要。
-
数据集分类
- Scene-focused datasets:视频长度很短,且可以通过静态情境来判断行为本身,比如Kinetics-400/UCF101/HMDB51等
- motion-focused datasets:背景信息很少,对行为本身的帮助也不大,包括
从左到右和从右到左等类别,需要很强的运动信息。 - 多标签数据集:有更多标签,比如提供了bbox以及object标签。
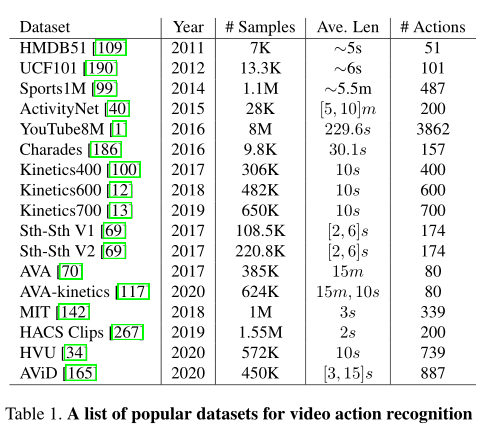
1.3. 具体数据集概述
- 这里不介绍了,自己其实有单独的笔记记录这些数据集的情况
- HMDB51、UCF101、Sports1M、ActivityNet、YouTube8M、Charades、Kinetics、Something-Something、AVA、Moments In Time、HACS、HVU、AViD
2. 模型发展
2.1. 看图说话
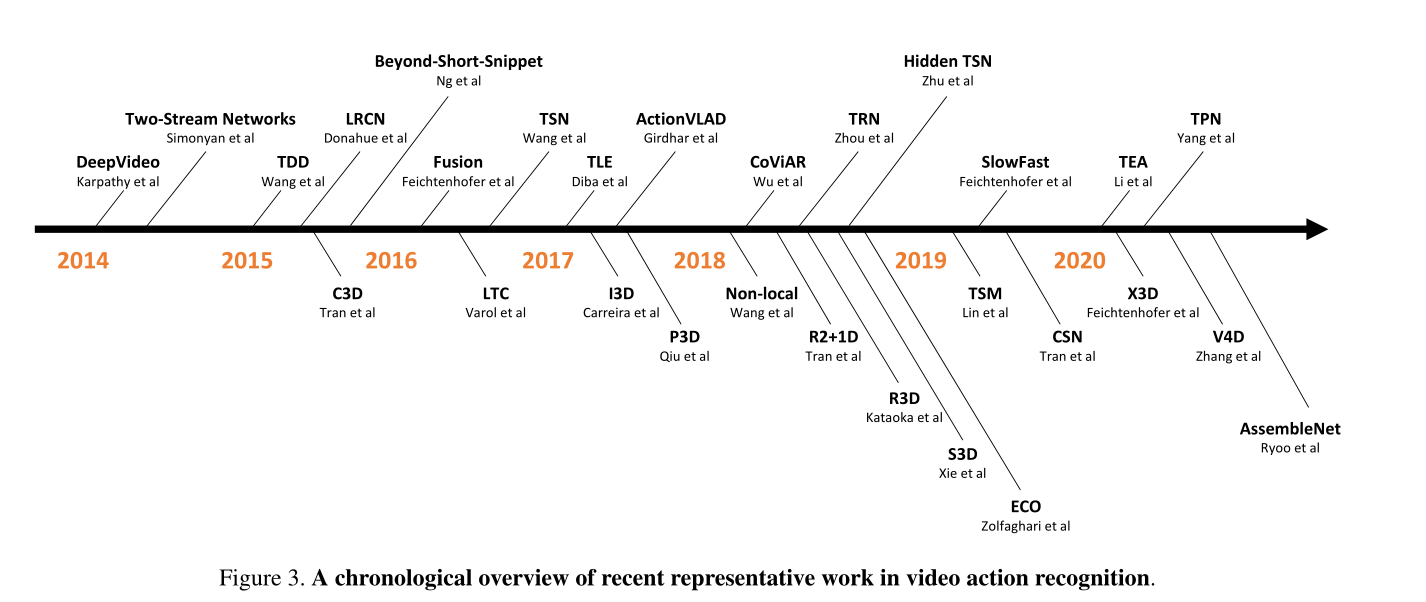
2.2. 模型概述与挑战
- 挑战(对于视频数据建模的挑战)
- 挑战一:人类行为存在非常大的 intra- and inter-class variations
- 同一类行为之间的差距非常大,不同行为之前的差距也非常大
- 同一动作可以从不同角度、不同速度来进行。
- 有一些行为有非常类似的动作趋势,非常难以区分。
- 挑战二:对于行为的建模必须同时对短期动作信息与长期时间信息进行建模
- both short-term action-specific motion information and long-range temporal information
- 挑战三:模型训练与推理需要的计算量都非常大。
- 挑战一:人类行为存在非常大的 intra- and inter-class variations
2.3. 模型的发展
-
手工特征(hand-crafted features):这个我不太关心,就没细看
-
双流法(two-stream networks)
- 光流(optical flow)是一种用于描述物体、场景运动方式的表示方式(motion representation)
- 能够很好的描述运动特征(motion pattern)。
- 相比于RGB图像,能够提供更加直接的信息(orthogonal infomation)。猜测意思是,不太考虑context信息,更多考虑动作本身。
- 双流法有一个所谓的“双流假设”(two-streams hypothesis):大脑中的视觉皮层(visual cortex)包含两个通道,dorsal stream(实现目标检测)和dorsal stream(实现行为检测)
- RNN相关算法:基本就是cnn backbone加上LSTM及其变种。
- Segment-based 相关算法:比如TSN/TSM,以及基于这些的时序行为检测方法TRN。
- 多模态数据:比如加上声音、深度学习、骨架信息等。
- 光流(optical flow)是一种用于描述物体、场景运动方式的表示方式(motion representation)
-
3D模型
- 直接扩展2D模型为3D模型,比如C3D
- 叠加2D与3D模型,比如R2+1D
- Long-range temporal modeling(不知道咋翻译,长期时间建模?):普通行为识别都是对短期数据进行建模,长期数据建模有一些方法,比如T3D/LTC,作者把non-local也放在这一部分,没看懂。
- 3D模型的变种,比如X3D/A3D
-
探索更高效的视频建模方式
- 问题:
- 对于Kientics-400,如果构建光流需要4.5T的空间保存……
- 3D模型部署比较困难(没有2D支持的好)
- 3D模型需要更多IO性能。
- 探索“模拟光流”的方法
- 双流发需要预先计算光流,这是一个很大的限制。
- 有一些方法,比如MotionNet、PAN等都是模拟光流的方法。
- 探索不需要3D卷积的时间建模方法,一般都是一些新结构,比如TSM/TIN/STM/TEA/TEINet等
- 问题:
-
其他研究
- 基于轨迹的方法
- 基于rank pooling的方法(使用类似于LTR的方法来进行建模),但看论文好像都是早期的(2017之前)。
- Compressed video action recognition:视频编码中,I帧是关键帧,P/B帧都不是关键帧,可能可以从这里入手,有一些使用了知识蒸馏的方法。各种Sampler方法可能可以归于这一类,比如SCSampler
- 视频帧提取方法:frame/clip sampling相关,即一般方法认为所有输入帧都有相同的权重,但其实不应该是这样。Sampler相关的也可以归于这一类。
- Visual tempo:描述动作有多快,比如CIDC/TPN
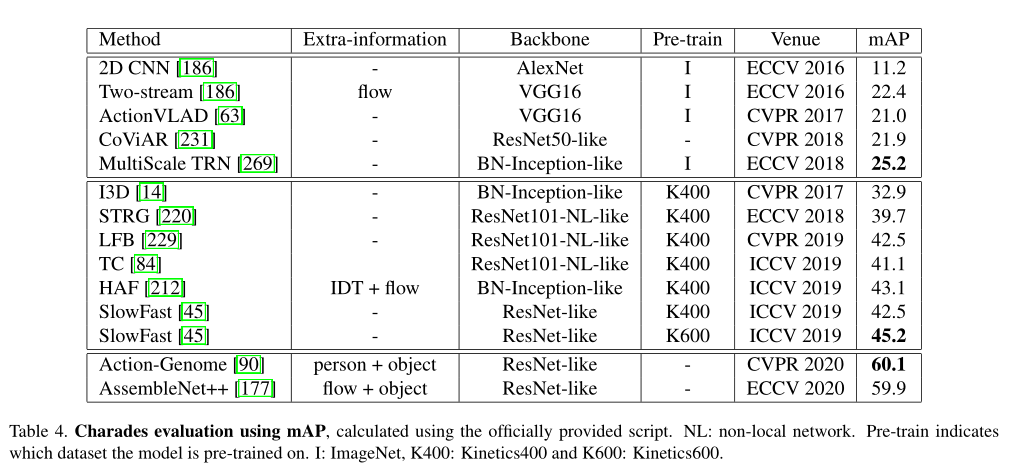
3. 性能指标与结果展示
- 一般对比准确率、fps。
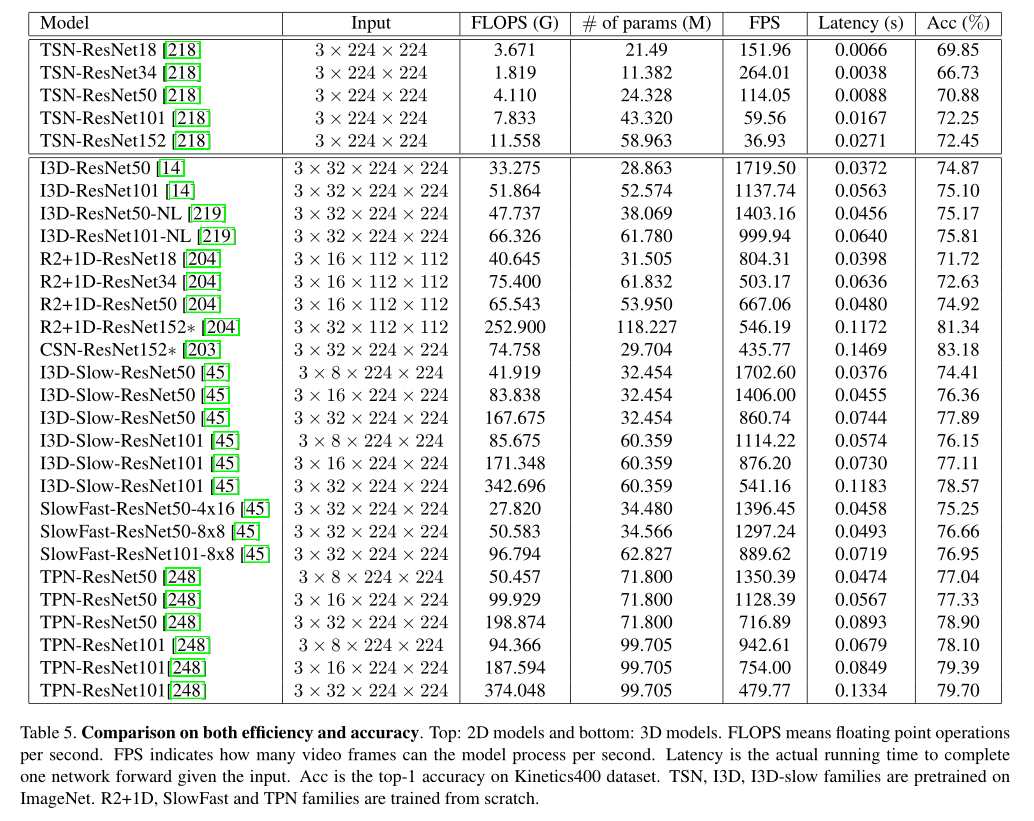
4. 其他研究方向
- 数据增强:有论文说color jitter和随机翻转有一些效果,其他的没有验证过。
- domain adaptation(迁移学习的一种)
- 神经网络搜索(NAS):肉食者谋之,又何间焉
- 高效模型部署(部署到现实场景中比较困难,应该指的是监控场景):
- 主要存在的问题:
- 大多数模型都是在offline的状态下设计训练的,即每次拿到的都是一段视频,而不是在线视频流。
- 大多数模型不能实时运行。
- 3D以及其他非标准op很难部署。
- 很多2D相关技术可以应用到行为识别中,比如模型压缩、量化、剪枝等等。
- 可能需要更好的数据集以及更合适的性能指标来。
- 可能可以使用压缩视频来进行,毕竟大多数视频已经被压缩过了。
- 主要存在的问题:
- 新数据集:
- 现有的大多数数据集都是偏向于空间信息,即通过一张图片就能判断行为类别,而不需要动态信息。
- youtube不允许单个id下载大量数据……哭了
- 视频对抗攻击
- Zero-shot learning
- 弱监督学习
- 细粒度分类
- 第一视角行为识别
- 多模态
- 自监督学习

















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









