







文章目录
0. 前言
- 介绍AutoAugment系列论文
- AutoAugment:系列的开山之作,定义了数据增强策略的形式,并通过强化学习暴力搜索最优数据增强策略。
- Fast AutoAugment:为了缓解AutoAugment训练耗时长的问题,通过Bayesian DA以及密度匹配搜索最优数据增强策略,达到与AutoAugment差不多的效果。
- PBA:为了缓解AutoAugment训练耗时长的问题,借鉴 PBT(超参数搜索算法)的思想,搜索最优数据增强策略schedule,从而达到与AutoAugment差不多的效果。
1. AutoAugment
- 相关资料:
- 论文基本信息
- 领域:数据增强
- 作者单位:Google Brain
- 发表时间:CVPR 2019
- 一句话总结:通过强化学习算法寻找每个数据集最合适的增强策略
1.1. 要解决什么问题
- 之前提出了很多数据增强的方法。
- 每个数据集对应的数据增强方法都是手动设计的。
- 每个数据集应该使用怎样的数据增强策略,这方面的研究比较少。
1.2. 用了什么方法
- 通过强化学习的方法寻找每个数据集对应的数据增强策略。
- 一共使用了16种数据增强方法
- 大多数方法都有一个magnitude范围。
- 后续每个方法都对应一个离散的magnitude数值(0-10),有最大值。
- 之后根据magnitude范围、magnitude离散值、magnitude离散值最大值三个来计算当前magnitude数值。
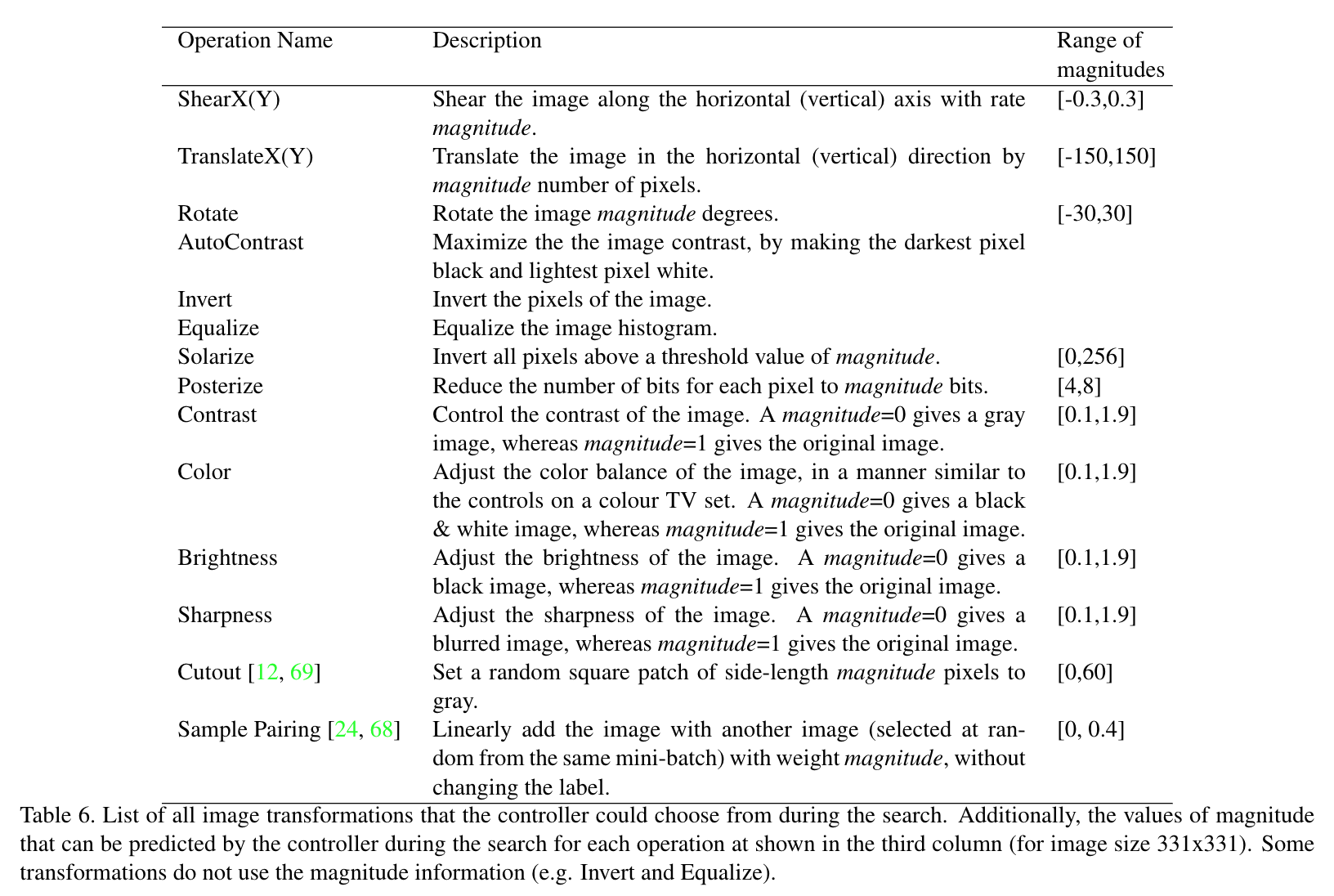
- 数据增强策略
- AutoAugment这篇论文最主要的贡献我觉得有俩,一是提出了通过AutoML的方法寻找数据增强策略这条路并证明是可行的,二是提出了这个“数据增强策略”的基本形式。
- 后面一系列论文的数据增强策略基本上都沿用了这个数据增强策略形式。
- 数据增强策略(policy)由若干子策略(sub-policy)组成。
- 每个子策略由n种数据增强方法组成(本文中n=2)。
- 每种数据增强方法对应3个参数:方法名称、触发概率、magnitude数值。
- 后面一篇论文中有一个可视化示意图,比较容易理解。
- 本文提出的策略一共包含5个子策略。
- 搜索空间
- 定义好了数据增强策略,其实也就定义好了搜索空间。
- 所以搜索空间大小时 ( 16 × 10 × 11 ) 1 0 (16 \times 10 \times 11)^10 (16×10×11)10
- 几个数值依次代表:16是数据增强方法数量,10是magnitude离散值数量,11是概率离散值数量(0/0.1/…/0.9/1.0共11个数值),10代表5个子策略共10个方法。
- 搜索具体实现是强化学习PPO+RNN,看不懂,主要参考了NAS
- Learning transferable architectures for scalable image recognition
- Neural architecture search with reinforcement learning
- Designing neural network architectures using reinforcement learning
- Proximal policy optimization algorithms
1.3. 效果如何
- 每个数据集搜索出来的结果都不错。
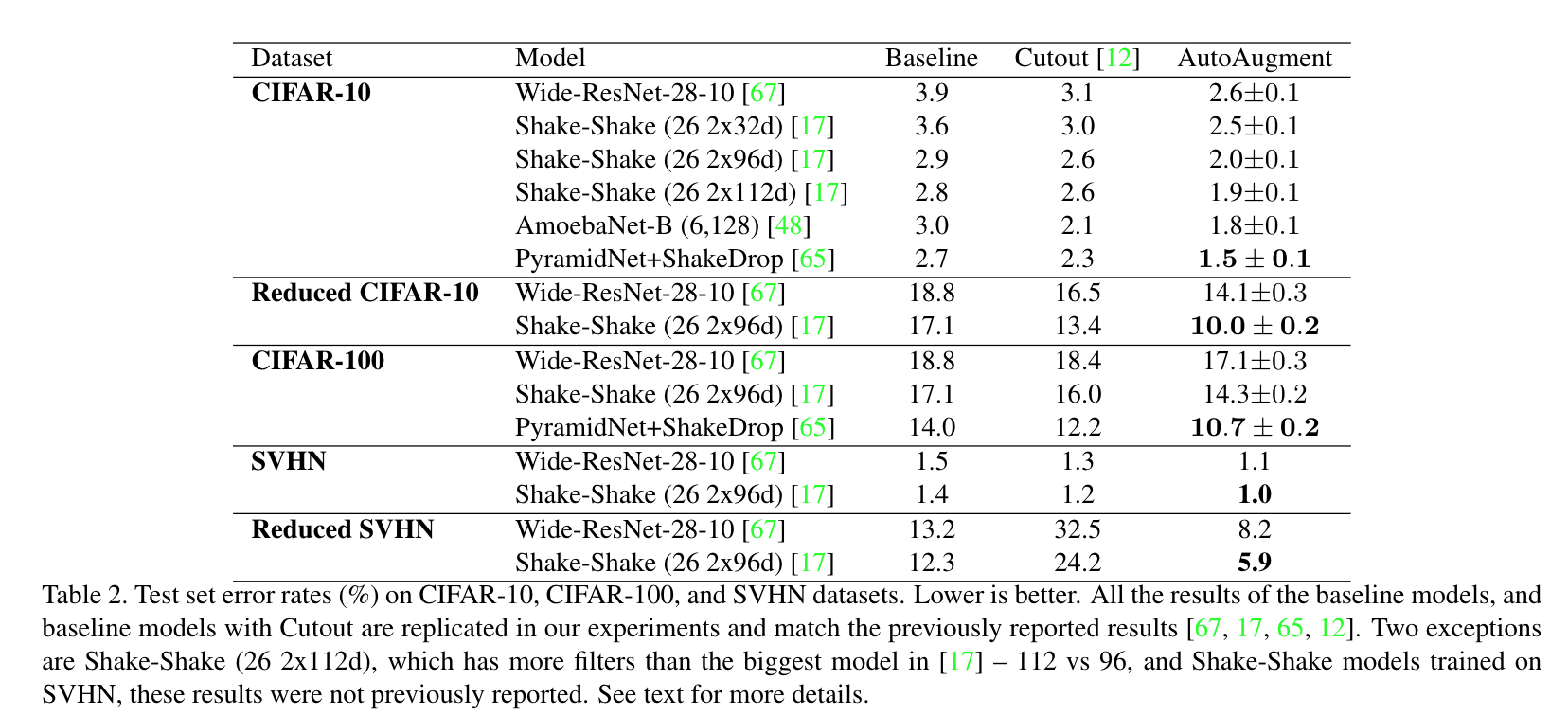
- 搜索出来的增强策略具有一定迁移能力(A数据集搜索出来的增强策略用到B数据集效果也不错)
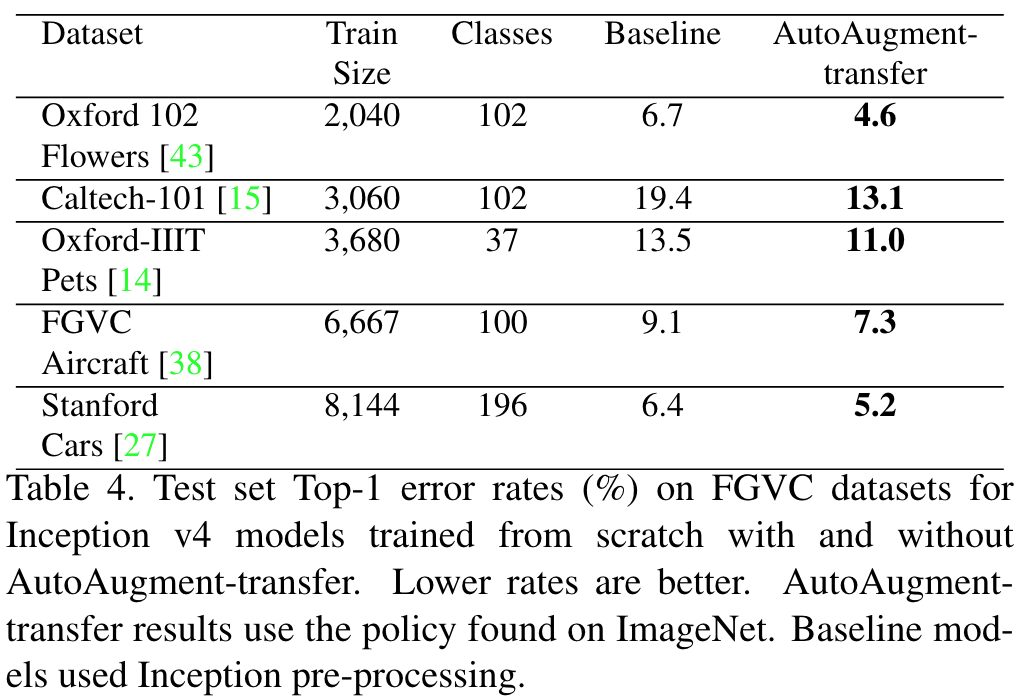
1.4. 还存在什么问题&可借鉴之处
-
这篇属于这个领域的开山之作,挖坑。
- 证明搜索数据增强策略是可行、有效的。
- 提出的这个搜索空间(数据增强策略定义)非常有用,后续都用这个。
-
毕竟是开山之作,很多地方问题很大,最明显的就是训练时间太长了……
- 后续论文基本上都是要解决训练时间太长的问题。
2. Fast AutoAugment
- 相关资料:
- 论文基本信息
- 领域:数据增强
- 作者单位:Kakao(韩国微信) Brain
- 发表时间:2019.5
- 一句话总结:使用密度匹配与类似Bayesian DA进行增强策略搜索
2.1. 要解决什么问题
- AutoAugment的训练时间太长了(Cifar10要5000GPU Hours,ImageNet要15000GPU Hours)
2.2. 用了什么方法
- 沿用了AutoAugment的搜索空间。本文有一张图很清晰的解释了一个子策略(sub-policy)的结构
- 本文的搜索空间与AutoAugment的搜索空间基本上相同,只有一个区别:数据增强方法的两个参数(概率p和magnitude)是
[0, 1]范围内连续的数值,而不是离散的。
- 本文的搜索空间与AutoAugment的搜索空间基本上相同,只有一个区别:数据增强方法的两个参数(概率p和magnitude)是
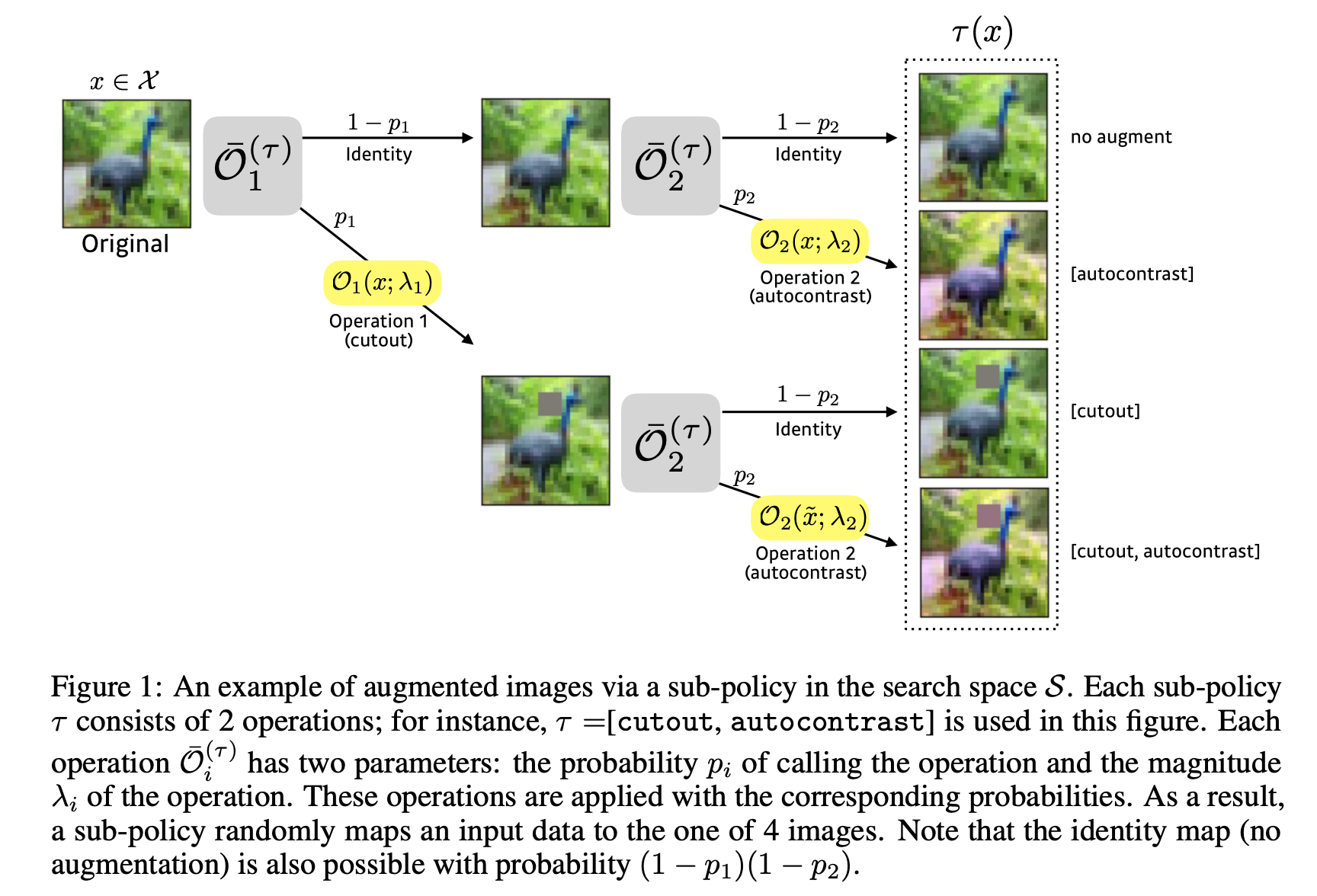
-
搜索方法改变了,使用了基于密度匹配的搜索策略。
- 整体思路:
- 之前AutoAugment要重复训练很多child models重复训练得到结果然后筛选策略。
- 本文将增强得到的数据作为训练数据中缺失的数据(原始数据与增强数据属于同一数据分布)。
- 搜索数据增强策略,也就是两个训练数据集之间进行密度匹配。
- 搜索算法如下

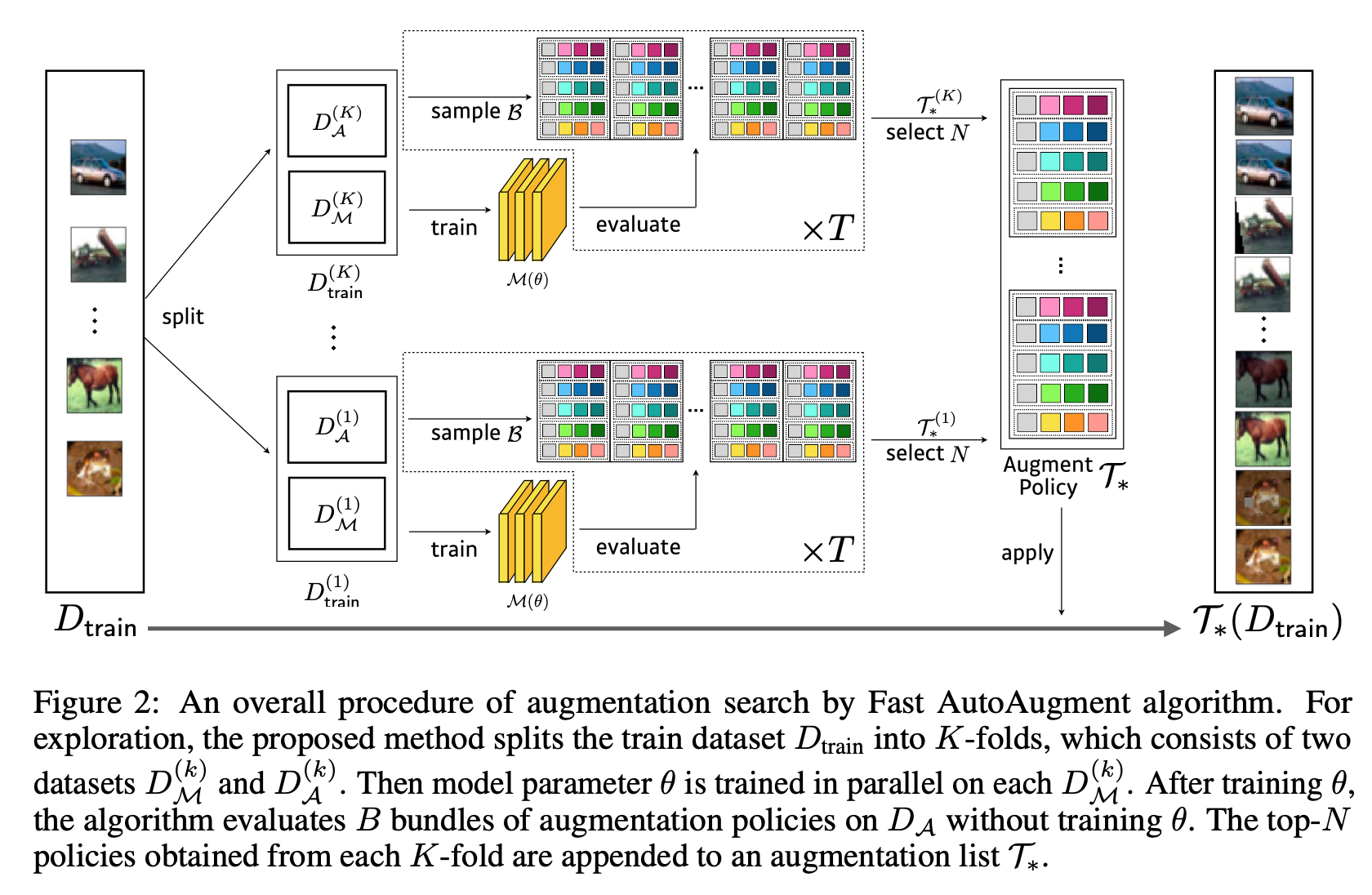
- 整体思路:
-
基于密度匹配的增强策略搜索
- 这部分不是特别懂,能理解个大概。
- 主要就是有两个数据集
- 通过一个数据集训练模型,得到模型
- 在另一个数据集上尝试各种数据增强策略,令前一步得到模型的准确率最高
- 从公式上看就是(KaTeX parse error: Undefined control sequence: \Tao at position 1: \̲T̲a̲o̲是增强策略集合,
Θ
∗
\Theta^*
Θ∗是训练得到的模型参数,
R
R
R是模型准确率,
D
A
D_A
DA就是第二个数据集)
-
本文的具体实现(Github)使用了HyperOpt和Ray,值得仔细看一下,以便更好地理解相关内容。
- 上面过程中最主要的BayesOptim就是直接调库。
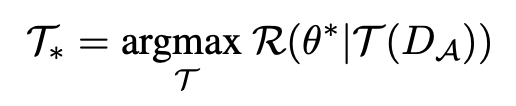
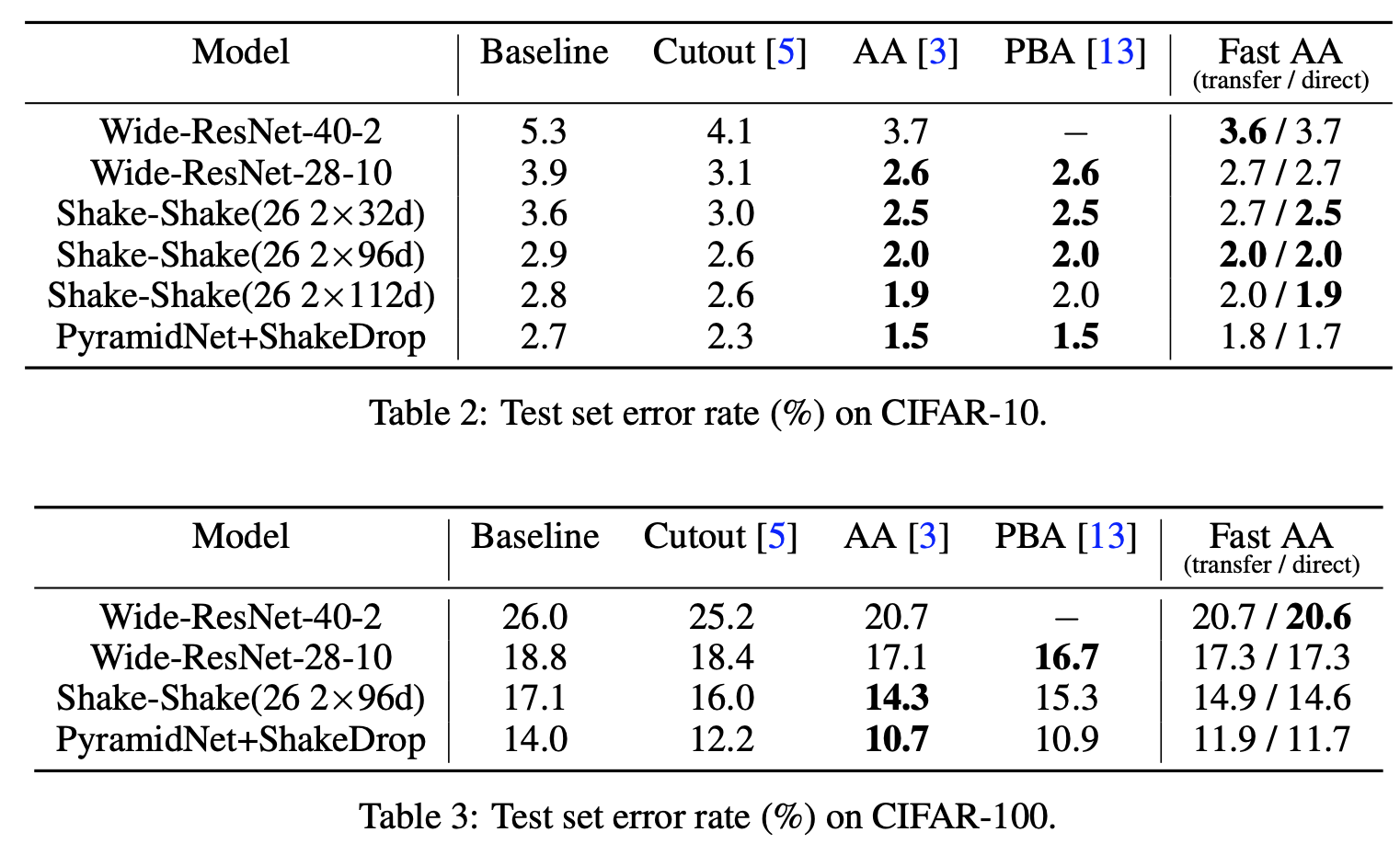
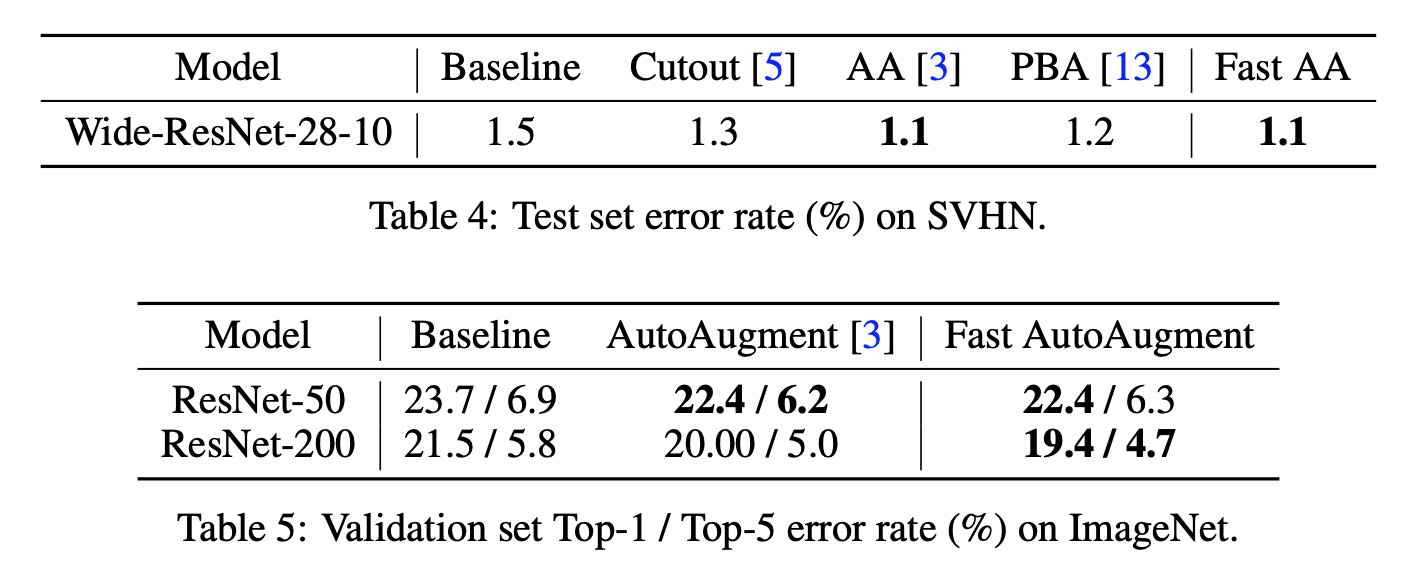
2.3. 效果如何
- 比AutoAugment耗时少,效果差不多

2.4. 还存在什么问题&可借鉴之处
- 这个有完整训练代码,如果要理解需要研究Ray、HyperOpt的使用。
3. PBA
- 相关资料:
- 论文基本信息
- 领域:数据增强
- 作者单位:UC Berkeley
- 发表时间:ICML 2019
- 一句话总结:借鉴Population based training方法搜索augmentation policy schedule(而不是augmentation policy)。
3.1. 要解决什么问题
- 之前的AutoAugment速度太慢,想要提高搜索的效率。
3.2. 用了什么方法
- 本方法搜索的是augmentation policy schedule,而不是 fixed augmentation policy。
- 所谓fixed augmentation policy,我猜就是类似AutoAugment以及Fast AutoAugment的结果,如一个策略包含5个子策略,每个子策略的数据增强方法、参数都是固定的。
- 本文的搜索空间,其实也就是 augmentation policy schedule,优势有:
- 判断一个fixed policy的好坏需要训练一个模型,耗时很长,而判断一个schedule的好坏不需要管模型之前的效果如何。
- 根据实验结果表明,搜索shedule后更能得到效果好的policy。
- augmentation policy schedule的定义
- 搜索空间数量级:
- 为了方便与AutoAugment进行对比,使用的参数都是类似 AutoAugment
- 一共选择了15个数据增强方法(相比AutoAugment,去掉了SamplePairing),每个方法有两个参数(使用概率p以及量级magnitude),所以搜索空间是 ( 10 × 11 ) 3 0 = 1.75 × 1 0 6 1 (10 \times 11)^30 = 1.75 \times 10^61 (10×11)30=1.75×1061,远远大于AutoAugment的 2.8 × 1 0 3 2 2.8 \times 10^32 2.8×1032。
- 所谓
count,值得就是最多使用几个数据增强方法,后面的probability应该就是下面for循环中3个count数值的取值概率。 - 可以看到,与AutoAugment相比,本文schedule没有“固定子策略”的概念,或者说,本文的子策略是不固定的。
- 搜索空间数量级:

- 如何寻找、学习一个schedule?
- 将augmentation policy search看作是 hyperparameter schedule learning 的一个特例。
- 借鉴Population based training(超参数搜索算法)来实现,PBT搜索的不是固定的最优超参数,而是超参数schedule。
- PBT的基本思路
- 第一步:随机初始化固定数量的模型,并行训练。
- 第二步:训练一定次数后,进行
exploit-and-explore操作,去处效果差的模型,赋值效果好的模型的参数与权重,并对效果好的模型的超参数进行扰乱(perturb,稍微改变一点点参数)。- 由于不需要进行重新训练,所以需要的计算量相对少一点。
- 本文基于PBT提出了PBA,其基本实现思路分为5个步骤
- Step:每一步都要进行一轮训练(one epoch gradient descent)
- Eval:通过验证集验证一次试验的效果
- Ready:本次试验已经准备好进行 exploit-and-explore 操作,要进行3steps(训练3epochs)
- Exploit:使用Truncation Selection策略,就是将效果排名后25%的模型通过排名前25%的模型进行替换
- Explore:对每个超参数,要么随机初始化,要么根据前一轮的结果进行随机扰动,具体步骤如下图
- 20%的概率随机初始化,80%的概率进行随机扰动。
- 随机扰动起始就是将参数进行简单变换(变换幅度是amt,可能是增加amt也可能是减少amt)

3.3. 效果如何
- 论文中反复强调一点,一些参过数的设置是为了与AutoAugment进行对比,并不是说经过测试这么设置效果好。
- 与AutoAugment比,效果差不多,时间少
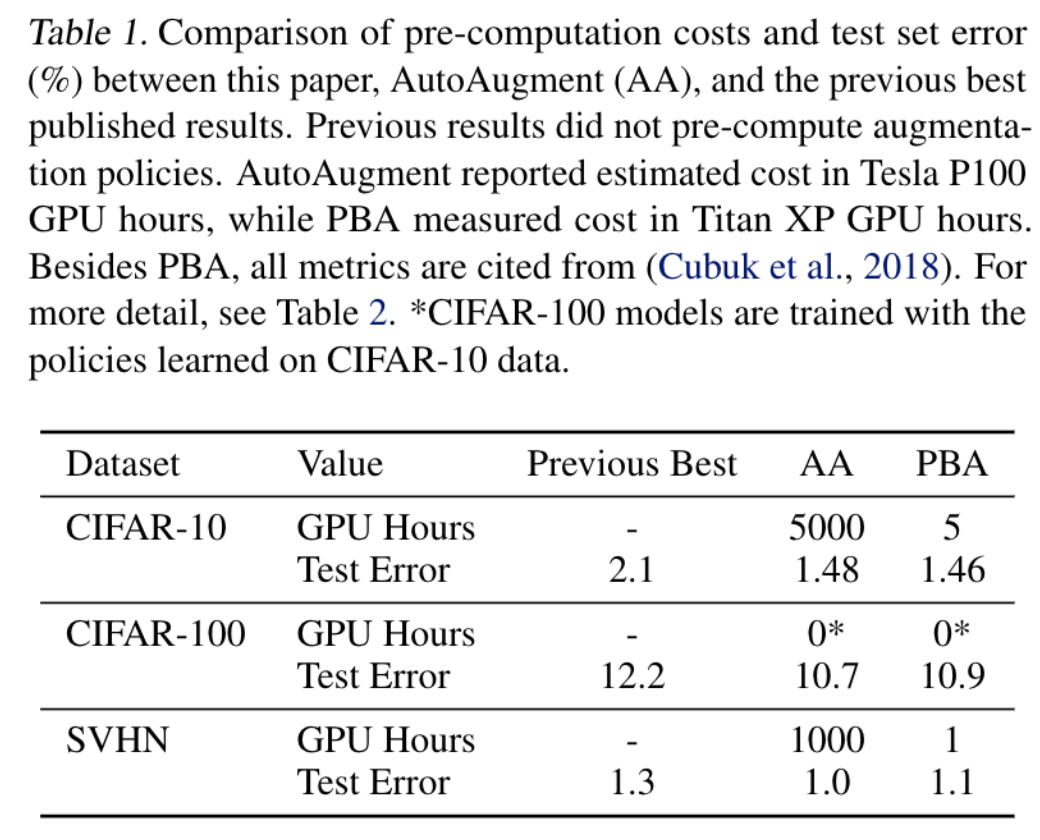
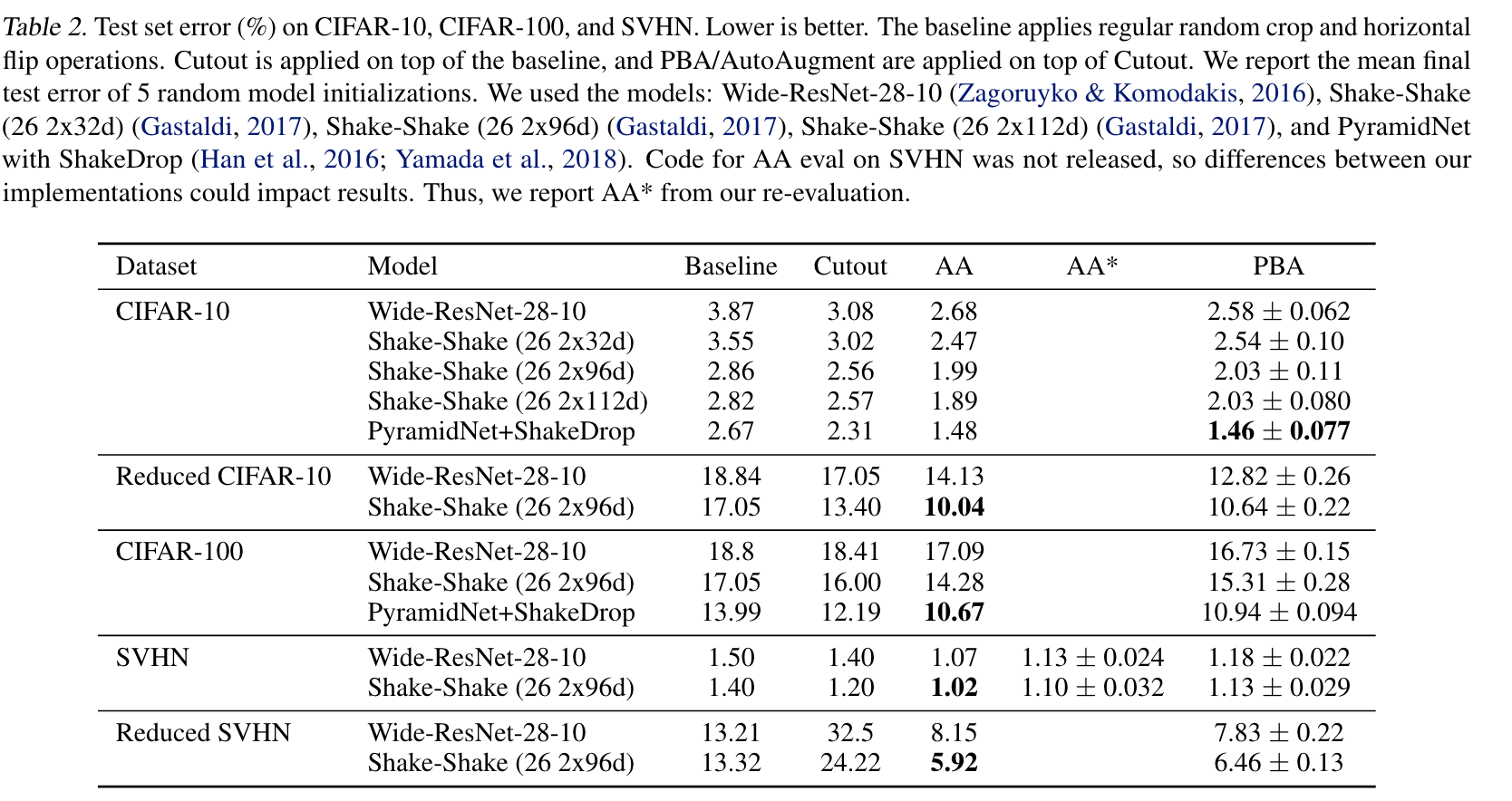
3.4. 还存在什么问题&可借鉴之处
- 根据Fast AutoAugment看,效果好像不如Fast AutoAugment
- 也是通过Ray实现,源码也有,可以学习一下。

















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









