







本文为 「茶桁的 AI 秘籍 - BI 篇 第 35 篇」
文章目录

Hi,你好。我是茶桁。
我们通过两节课的内容,应该对 GCN 已经有了初步的了解并熟悉了它的整个逻辑和应用过程。那么这一节课咱们就来看一个实际的项目。这个项目中一共有 4 万多个恶意软件。
相信很多同学应该都或多或少的用过查毒的软件吧?那么,杀毒软件怎么查毒呢?杀毒软件其实也是要通过软件的一些特征行为来做判断,那行为的采集是由 API 来做标识的。

在途中,hash 是理解成是一个ID,后面 t_0 到 t_99 是它 100 次调用的序号,这里的API的序号是系统里面的哪一个进程。最终,malware 代表的是恶意软件,0 是正常,1 是恶意软件。
这是 Kaggle 上的一个案例,具体地址可以参看这里:https://www.kaggle.com/datasets/ang3loliveira/malware-analysis-datasets-api-call-sequences
打开地址之后咱们来看一看

整个案例的数据是一共有 4 万多个恶意和 1,000 多个正常的。看到这里我们就可以知道,这个样本是一个分类的任务,并且这个分类还很不均衡。对于不均衡的问题一会做数据以及切分的时候要注意一下,它会不会打乱原来的分布的一个顺序。
那整个恶意软件的检测流程,咱们稍微定一下:
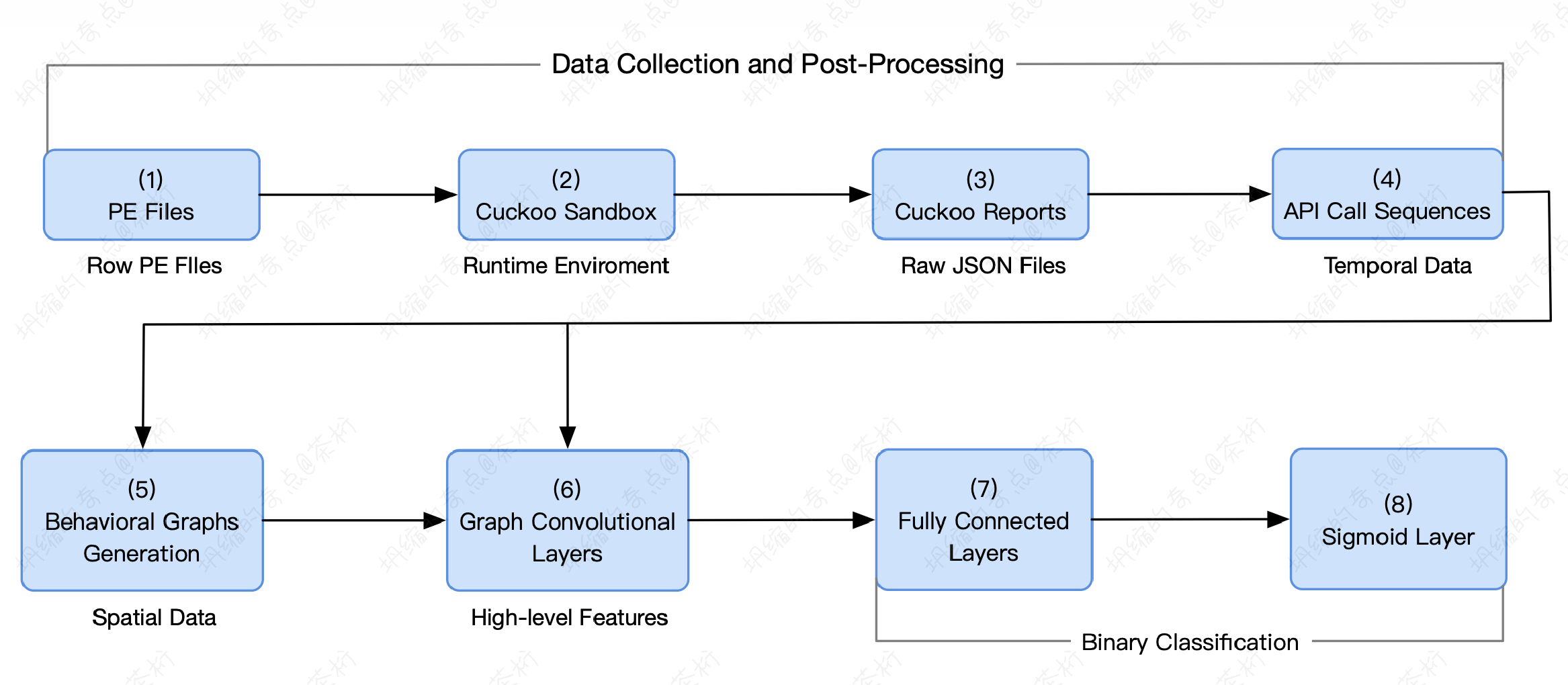
- Step1, PE files,Protable Executable, 可执行文件
- Step2, 沙盒,轮流执行 PE 文件
- Step3, 产生 raw JSON reports
- Step4,从生成的 JSON reports 中抽取 API 调用序列
- Step5,基于 API 调用序列,生成行为图(Behavioral graphs)
- Step6,使用图卷积层对行为图进行高维特征抽取,如果有多个 GCN 层叠加到一起形成一个深度的网络,需要把这些 GCN 的输出结果拼接起来,这样可以得到不同尺度的特征
- Step7,将学到的特征输入给 FC 层
- Step8,使用 Sigmoid 层进行二分类
先有一个可执行的文件,在一个沙盒里面让它去运行。把运行的过程采集下来,生成了一份 JSON 格式的报告,再从这份报告过程中提取出来调用的序列。所以前面实际上就是一个信息采集的过程,在一个调用模拟的沙盒过程中,把 API 使用的一个 sequence 序列就收集上来了。针对这些收集的序列构造一个 Behavioral Graph,叫做特征图。这是它的一个行为的图的生成。
原来是它调用了几个序列,后面用图的行为来做表达。有了图就可以做图上的特征提取,用的是 GCN,GCN 就主要是做特征提取用的。
后续如果做分类,这个分类器呢,一般我们在神经网络过程中会用 FC,它是全连接神经网络,它相当于是一个 MLP。通过后续的全连接,再加 Sigmoid 就实现了一个二分类特征。
接下来咱们简单来说一说神经网络的工作原理。你可以把它拆成两部分,第一部分是 Feature Extraction,特征提取。所以你看到的那些神经网络不管你是 CNN 或者别的什么,这些前面的部分都是特征提取,它会把一些关键特征给你提出来。
后面一个叫做 Classification,中文叫做分类。后面的分类器变化并不大,神经网络的分类器基本上都大同小异,都是 FC 就是全连接层。要构造
一个神经网络,最大变化不是在后面的 Classification,而是在前期如何去提取特征。对于图上的数据来说,采用的是 GCN 这种方式来进行提取。提取完以后用 FC 加 Sigmoid 去做一个二分类的运算,得出最终的一个结果。
这套流程其实就是对数据做特征提取和分类器得到结果。
对于这个例子,其算法流程如下:
- Step1,对于一个 API 调用序列 x,计算其邻接矩阵表
- Step2,使用 1 个或多个 GCN 层对 API 调用序列 x 进行特征抽取 Graph Embedding
其中 A = Seq2BGraph(x, |N|)得到邻接矩阵。
原来调用的一个序列会给它一个输入值,对它先需要提取一个邻接矩阵表,因为 GCN 是依赖于邻接矩阵去完成的。在网络过程中可以用一层也可以用多层。这些目的都是做 Graph Embedding,有了 Graph Embedding 后续就可以做全连接层 FC。
这里有一些定义
- A ~ = A + I N \tilde A = A + I_{N} A~=A+IN
- D ~ \tilde D D~ 为 A 的度矩阵
- X 为 x 的 one-hot 特征
- Z 为多个 GCN 层输出的拼接
- Y ~ \tilde Y Y~ 为预测结果
A_hat 的定义是加上了单位矩阵, D_hat 定义的是它的一个度矩阵。X 最开始是它的一个原始数据,再是它最终多层 GCN 的一个输出,然后预测结果 one-hot。
看看数据怎么去构造它,比如一个调用序列 x = (0, 1, 2, 0, 2, 3) 是它的 API 的 ID,就是系统进程先调用第 0 个,再是第 1 个、第 2 个。那这里一共有几个系统进程被调用呢?唯一值不重复的实际上就只有0、1、2、3这四个。我们用一张图来去看它可以连接的一个关系。
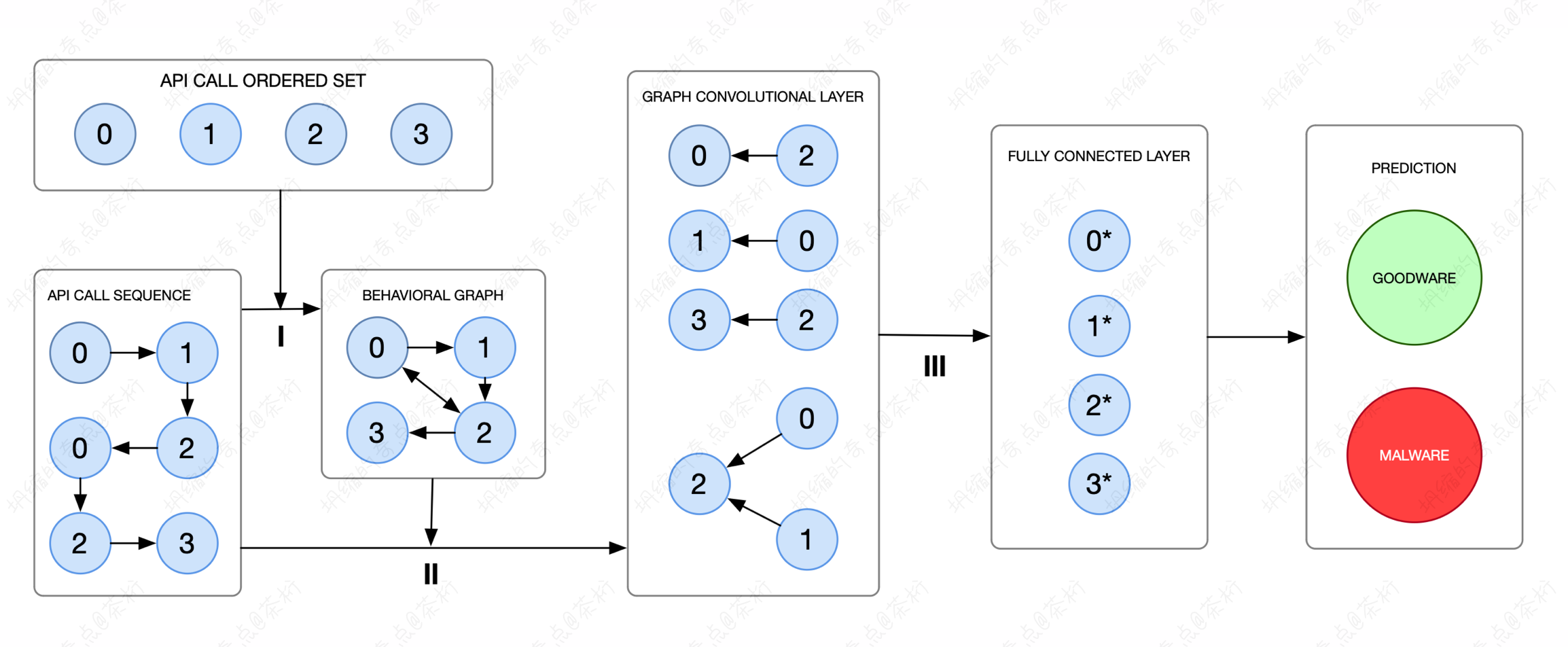
调序列是 0->1->2->0->2->3,其调用序列用 API CALL SEQUENCE 这张图生成了。在之前的课程中有给大家讲推荐系统的原理,都是类似的,在推荐系统里是将点击顺序用边做一个连接。这样,咱们的图构造就是 API CALL SEQUENCE 这张图到 BEHAVIORAL GRAPH 张图。
早期原始数据是一个调用的序列,如果想用 GCN 就要构造图。图怎么来?可以通过序列来构造,这个序列就是连通的边,如果它有边的顺序就给它连接上。有了这张图,就可以做 GCN 的特征提取了。
来看看原始数据是怎么来的:

A 是邻接矩阵,X 是调用序列,这是它输入的一个数据。AX 表明了 API 调用序列,以及每个 API 调用的入度邻居 (indegree neighbors)。A 表明了顺序的节点,X 表明了这些节点的行为。
每一层 GCN 的输入都是邻接矩阵 A 和 node 的特征 H,如果直接做一个内积,乘一个参数矩阵 W,再激活一下,就相当于一个简单的神经网络层:
f ( H ( l ) , A ) = σ ( A H ( l ) W ( l ) ) \begin{align*} f(H^{(l)}, A) = \sigma(AH^{(l)}W^{(l)}) \end{align*} f(H(l),A)=σ(AH(l)W(l))
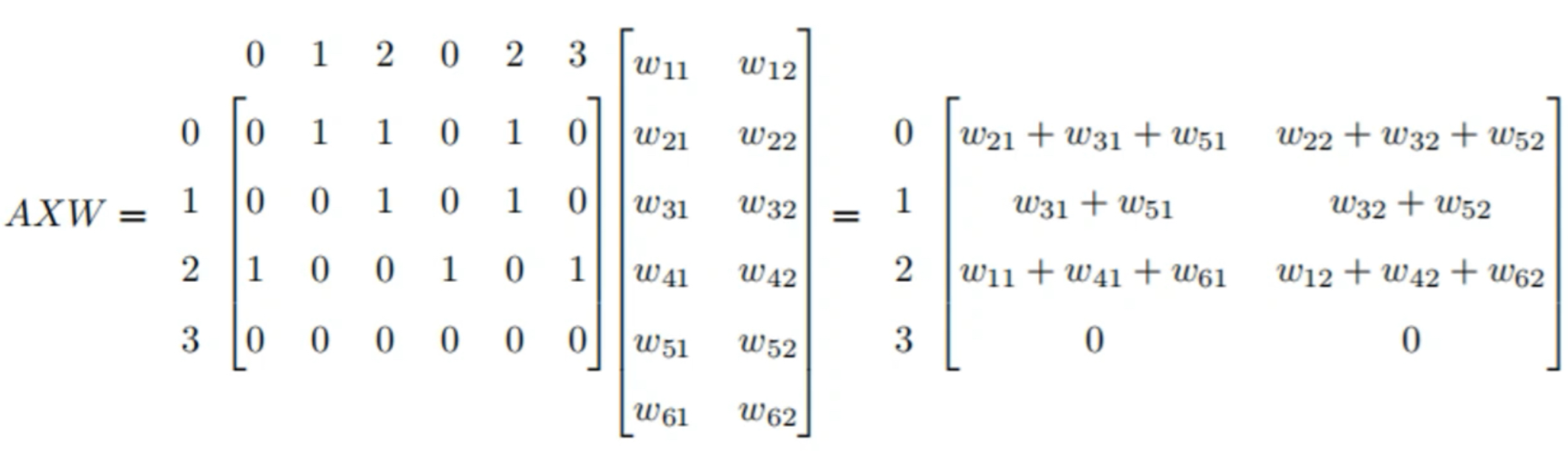
对于 2 个叠加的 GCN 层,我们将其拼接起来:

这是原来的一个定义,但之前也说了,这个简单模型存在 2 个局限性,缺乏一些自己的特征体系以及缺乏数据归一化。所以这里的 A 还是会把它使用成 D ~ − 1 2 A ~ D ~ − 1 2 \tilde D^{-\frac{1}{2}}\tilde A\tilde D^{-\frac{1}{2}} D~−21A~D~−21。就是加了一个对角线的单元矩阵,加上自己的特征,又加了一个数据的变化:
f ( H ( l ) , A ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) \begin{align*} f(H^{(l)}, A) = \sigma \left(\tilde D^{-\frac{1}{2}}\tilde A\tilde D^{-\frac{1}{2}}H^{(l)}W^{(l)} \right) \end{align*} f(H(l),A)=σ(D~−21A~D~−21H(l)W(l))
这样就把结果做了一个特征提取,后面再去做一个分类器。
我们可以看一下这个流程,先简单梳理一下整个代码,如何去求解这个问题。
先把数据读进来,读进来以后可以看到这个数据有 102 列,其实就是从 0 到 99 这 100 个调用序列以及最后一个标签。
df = pd.read_csv(path + 'dynamic_api_call_sequence_per_malware_100_0_306.csv')
df.head()
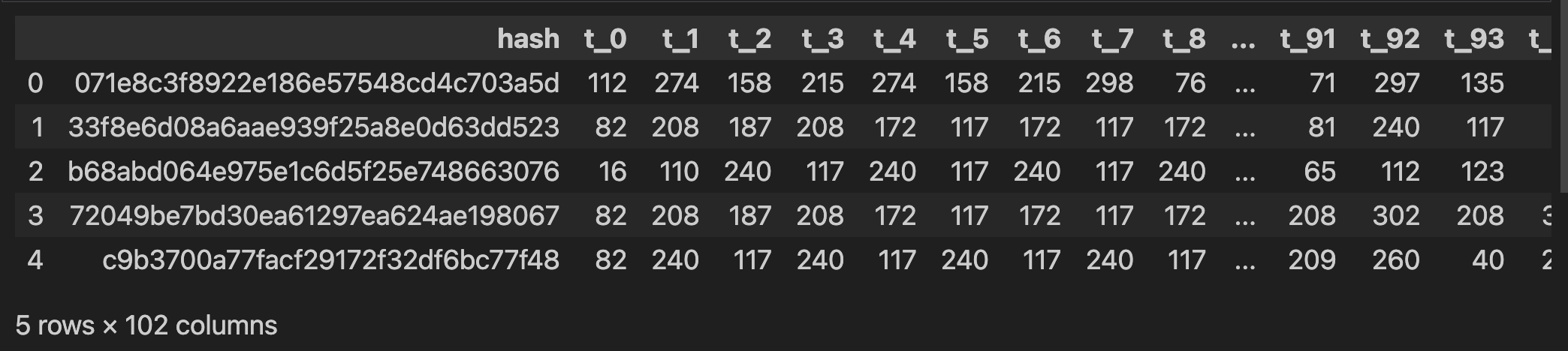
在这个数据中,hash 是一个 MD5 编码,在这里对预测是完全没有价值的,我们可以将它 drop 掉,还有 malware 这个标识。
X = df.drop(['hash', 'malware'], axis=1).values.astype(int)
y = df['malware'].values.astype(int)
y 就是 malware 这个特征,是否恶意的一个标识。
调用序列里面的最大值和最小值我们也需要查看一下:
print(X.min())
print(X.max())
---
0
306
最小值和最大值分别是 0-306,这一共有 307 个调用序列。
那样本是不是不均衡?做一个数数的计算
# 检查样本是否均匀
def check_imbalance(dataset):
count = sorted(Counter(dataset).items())
print(count)
print(count[1][1]/count[0][1])
return
check_imbalance(y)
---
[(0, 1079), (1, 42797)]
39.66357738646895
可以看到原来的样本 0 的个数是 1079,1 的个数非常多,所以这是一个样本不均衡的例子,这个不均衡的比例高达 39.7%。
后面要做机器学习的训练是需要做数据集的切分,如果不切分的话无法衡量好坏。切分之后还要去验证一下,验证切分的分布,有没有发生一些异常。
# 训练集 70%, 测试集 30%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = SEED)
check_imbalance(y_train)
check_imbalance(y_test)
# 释放不用的变量
del df, X, y
---
[(0, 731), (1, 29982)]
41.015047879616965
[(0, 348), (1, 12815)]
36.82471264367816
这个分布跟之前差别并不是很大,所以它本身也是 OK 的。如果分布跟之前差别比较大,那肯定不能算是一个好的切分方式。所以在这里 check 一下数据集的分布有没有打乱。分布如果发生了一些异常,最终有可能模型也不是一个理想的模型。模型最好是跟你的测试集的分布要保持一致。
接着咱们来写一个计算邻接矩阵矩阵的函数
# 计算邻接矩阵 A 和 D 矩阵
def norn_adj(X, input_dim_1):
# batch_size, input_dim_1, input_dim_1
temp = X.cpu().numpy()
A_adj = np.zeros([X.size(0), input_dim_1, input_dim_1])
for i in range(temp.shape[0]):
for j in range(temp.shape[1]):
x1 = int(temp[i,j])
if j!=(temp.shape[1] - 1):
x2 = int(temp[i, j+1])
A_adj[i][x1][x2] = 1.0
# 计算邻接矩阵
A = torch.from_numpy(A_adj).float()
# A_hat 为 A 的单位矩阵之和
A_hat = A + torch.eye(input_dim_1, dtype = torch.float)
D_hat = A_hat.sum(dim = 1).pow(-1.0).diag_embed()
return A_hat, D_hat
A 就是它的连接矩阵,不过我的电脑是 M1芯片,所以这里我用的是 CPU 来进行计算,如果你的电脑是 Windows 并且有独立显卡支持 cuda,最好还是使用 GPU 来进行计算,将这一句改一下:
A = torch.from_numpy(A_adj).float().cuda()
当然,之后的代码也是如此,我就不单独拿出来说了。我们继续。
这里对 A 求了一个 eye, eye 就是对角线的矩阵,这样就得到一个 A_hat。再对 A_hat 去求了一个度,把这个结果返回过来。
接着我们需要对 X 进行 one-hot 的特征提取:
# 对 X 进行 one-hot 特征提取
def to_one_hot(X, input_dim_1):
X = F.one_hot(X, num_classes = input_dim_1).float()
# 正常顺序(0, 1, 2) => (0, 2, 1)
X = X.permute(0, 2, 1)
return X
permute(0,2,1) 实际上是把顺序给它做一个交换。现在做的有可能是多维的结构,比如三维结构,把它序号称为 0, 1, 2,这是它正常的顺序。现在要把它变成 0,2,1, 这个顺序就是把后面两个给它换个位置就可以了,实际上是给它做了一个颠倒。有的时候在特征提取过程中的一些需要,可能在图像里面用的会比较多,因为有些通道是跟计算的通道的方式是不一样的,所以这里就做了一个变换。
然后是 GCN 的定义
class GCN_network(nn.Module):
def __init__(self, weight_dim_1, weight_dim_2):
super(GCN_network, self).__init__()
self.weight_dim_1 = weight_dim_1
self.weight_dim_2 = weight_dim_2
# 权重随机生成,y = wx+b 里那个 w
self.weights = nn.Parameter(torch.rand((self.weight_dim_1, weight_dim_2), dtype = torch.float, requires_grad = True))
def forward(self, A_hat, D_hat, X):
return D_hat.matmul(A_hat).matmul(X).matmul(self.weights)
Parameter 也是随机生成的,前向传播就是用 A_hat 乘上 D_hat。D_hat 在前面的代码中定义了 D_hat = A_hat.sum(dim = 1).pow(-1.0).diag_embed(),求了一个 pow,pow(-1.0) 就是 1/D,是一个倒数的概念。
实际上在工程上,这里用的是第二种计算方式。前面是一个拉普拉斯算子,再乘上一个 X,再后面是一个 W。这里的 GCN 就是模拟了一下它的一个 forward 前向传播的一个流程。
接着就需要定义一下网络:
# 使用 1 层 GCN 层
H_list_model_1 = []
class Model_1_network(nn.Module):
def __init__(self, input_dim_1, input_dim_2, weight_dim_2, dropout_rate):
super(Model_1_network, self).__init__()
self.input_dim_1 = input_dim_1
self.input_dim_2 = input_dim_2
self.weight_dim_1 = input_dim_2
self.weight_dim_2 = weight_dim_2
self.dropout_rate = dropout_rate
# 定义 GCN 层,AX 其实理解成 X 中每个节点对周围的加权,然后再过线性变换
self.gcn = GCN_network(self.weight_dim_1, self.weight_dim_2)
# 定义 dropout
self.dropout = nn.Dropout(p = self.dropout_rate)
# 定义 FC 层
self.fc = nn.Linear(self.input_dim_1 * self.weight_dim_2, 1)
# 前向传播
def forward(self, X):
# 通过 X 得到 A_hat, D_hat
A_hat, D_hat = norn_adj(X, self.input_dim_1)
X = to_one_hot(X, self.input_dim_1)
# 将 A_hat, D_hat, X 作为输入,传入 GCN 层
H = self.gcn(A_hat, D_hat, X)
H = self.dropout(H)
H = torch.relu(H)
# 变成两维,第一个维度保持不变,后面的很多维全部变成一维
H = H.view(H.size(0), -1)
# 预测阶段,进行可视化时
if not self.training:
H_list_model_1.append(H.cpu())
H = self.fc(H)
return H.squeeze()
神经网络里面有的时候容易过拟合,因为参数量特别大,参数量越多就越容易过拟合,神经网络参数就非常多,dropout 是防止过拟合。
FC 层,它的本质就是 Linear Regression,线性回归。它就把这一层和下面一层做了一个全部的连接,实际上就是一个线性回归的过程。
前面是一些参数定义,包括 dropout, FC 层的定义,下面 forward 是使用这个来进行计算。最开始传进去来的一个 X,先计算一下它的特征 A 和 D。原始数据 X,先提取它的邻接矩阵特征和度特征,然后把它做一个 one-hot 特征提取,做一个传入,传进来是 one-hot 编码之后的结果。
然后往后是第一层的 GCN,之后是 dropout, 在之后是 relu。这里 GCN 就做了一次,然后 view 拉值再去做 FC。
做这种恶意软件检测它是有持续关系的,就是调入顺序,从下一个时刻调入哪一个,LSTM 就专门是针对前后顺序的一种传递,所以除了 GCN 以外,LSTM 应该也是可以的:
H_list_lstm = []
# 定义LSTM
class LSTM_network(nn.Module):
def __init__(self, input_dim, hidden_dim, dropout_rate):
super(LSTM_network, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.dropout_rate = dropout_rate
self.lstm = nn.LSTM(self.input_dim, self.hidden_dim, batch_first=True)
self.dropout = nn.Dropout(p = self.dropout_rate)
self.fc = nn.Linear(self.hidden_dim, 1)
# 前向传播
def forward(self, X):
# 对X进行one_hot特征提取
X = F.one_hot(X, num_classes = self.input_dim).float()
# 隐藏层形状:(num_layers, batch_size, hidden_dim)
hidden_0 = (torch.zeros(1, X.size(0), self.hidden_dim).float(), torch.zeros(1, X.size(0), self.hidden_dim).float())
# 输入/输出形状: (batch_size, seq_len, hidden_0)
_, self.hidden = self.lstm(X, hidden_0)
H = self.hidden[0].squeeze()
H = self.dropout(H)
# 可视化时用到
H_list_lstm.append(H.cpu())
H = self.fc(H)
return H.squeeze()
定义 LSTM,前面流程都类似,只不过改成了LSTM。一样也是加了 dropout, Linear,原始数据就是 one-hot。进入输入之后,多了一个特征提取,LSTM 的 Embedding,然后再去 dropout,然后再做 FC 层。这个LSGM就定义好了。
模型好坏还需要做一个评估,现在这里的评估用 f1_score, roc_auc_score:
# 模型评估
def model_evaluate(y, pred):
print('Confusion matrix\n[TN FP]\n[FN TP]')
# confusion_matrix(y_true, y_pred)
print(confusion_matrix(y >= 0.5, pred >= 0.5))
print(f'F1-Score: {f1_score(y >= 0.5, pred >= 0.5): .4f}')
print(f'ROC-AUC: {roc_auc_score(y, pred): .4f}')
针对于现在这个数据集,对模型算法的好坏用准确率来做衡量准确吗?一会咱们可以一起来看一看应该用哪一个指标会更合理一些。
首先,咱们定义输入的维度 input_dim = 307,因为是从 0 到 306。每一个特征实际上都是从 0 到 306 来做一个定义,所以输入维度是 307 维。在 Embedding 这里设了一个 70,就是中间有嵌入到一个 70 维长的一个项量里。
dropout 设成 1.5,最大的学习次数为了方便,现在学的次数并没有那么多,设成 2 次,然后用 LSTM 来做分类器。
# 使用LSTM做二分类
LSTM = NeuralNetBinaryClassifier(
LSTM_network,
module__input_dim = input_dim,
module__hidden_dim = hidden_dim,
module__dropout_rate = dropout_rate,
batch_size = batch_size,
max_epochs = max_epochs,
train_split = None,
optimizer = torch.optim.Adam,
iterator_train__shuffle = True,
device = 'cpu'
)
# 定义 pipeline
pipe = Pipeline([
('model', LSTM)
])
计算过程中的用了一个 Pipeline,这是个流水线,其实没有什么其他的额外操作,就是提取一个 LSTM。
后面对 LSTM 去做一个训练:
# 使用LSTM进行训练
pipe.fit(X_train, y_train.astype(float))
---
epoch train_loss dur
------- ------------ -------
1 0.1188 13.4787
2 0.0835 13.1750
运行一下,看一看它运行的过程。
做完两轮以后看看它的预测:
H_list_lstm.clear()
# 得到预测结果
X_test_predictions_1 = pipe.predict_proba(X_test)[:, 1]
model_evaluate(y_test, np.ones(len(y_test)))
print(X_test_predictions_1)
print(y_test)
# 对LSTM预测结果进行评估
model_evaluate(y_test, X_test_predictions_1)
---
Confusion matrix
[TN FP]
[FN TP]
[[ 0 348]
[ 0 12815]]
F1-Score: 0.9866
ROC-AUC: 0.5000
[0.99655116 0.99344033 0.86208236 ... 0.99403644 0.97203976 0.9942034 ]
[1 1 1 ... 1 1 1]
Confusion matrix
[TN FP]
[FN TP]
[[ 94 254]
[ 1 12814]]
F1-Score: 0.9901
ROC-AUC: 0.8677
这是它的一个结果预测,结果预测的时候用了一个评估。
看起来 F1 感觉很好,不过我们现在是对 1 来做评估。什么是 1 呢?4万多个恶意软件检测,干脆就直接认为都是恶意软件。如果都是恶意软件的话,他没有什么预测能力。这种预测能力的评分 F1 值得到 0.9866 分, 看到这个成绩感觉已经很完美,其实它把好的都给误伤了,所以才得到了 0.9866 这个成绩。
那哪一个分数会更合理呢? 下面有一个 AUC 分数,AUC 是 0.5,这个结论其实说明比较明显,就是本身没有一个预测能力,它就是一个随机的预测。所以 AUC 对于这个例子来说会更合理一些。
然后看看 LSTM 得到的结果,F1 值比原来高了一点点 0.9901,看到这会觉得其实跟原来 1 的结果好像差别不大,实际上差别还是非常明显的。因为原来 AUC 是0.5,它没有预测能力,而现在有预测能力是 0.8677,因此 AUC 这个值相对来说合理一点点。
然后我们把这个 AUC 给绘制出来,AUC 的取值本身是 ROC 的一个面积。
fpr_1, tpr_1, thresholds_1 = roc_curve(y_test, X_test_predictions_1)
plt.plot([0, 1], [0, 1], linestyle='--')
plt.plot(fpr_1, tpr_1)
plt.show()
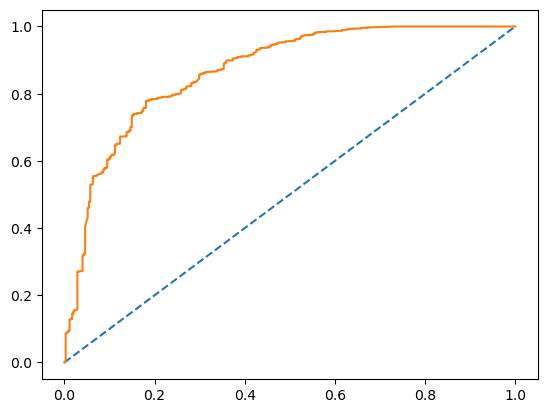
LSTM 可以达到 0.86 的 AUC。先记住这个值,然后再对它来做可视化。
# 可视化
def visualize(X, y, points, n_features):
# points 随机排列
points = np.arange(points)
np.random.shuffle(points)
color = ['red' if l == 1 else 'green' for l in y[points]]
for i in range(n_features):
for j in range(n_features):
if j > i:
plt.scatter(X[points, i], X[points, j], color = color)
plt.pause(0.1)
return
现在是嵌入到了 70 维的向量里面去,现在做可视化是通过 PCA 的方式来做映射,这样就可以把它转成平面的坐标系来做可视化了:
# 使用 PCA 压缩到 2 维,进行可视化
def visualize_pca(X, y):
# 归一化
X = X / np.max(X)
# 使用 PCA 进行压缩
pca = decomposition.PCA(n_components = 2)
# 可视化
visualize(pca.fit_transform(X), y, X.shape[0], 2)
return
visualize_pca(X_test, y_test)
result = torch.zeros(1, 70)
for i in H_list_lstm:
result = torch.cat([result, i.cpu()], 0)
X_result = result.numpy()[1:]
visualize_pca(X_result, y_test)
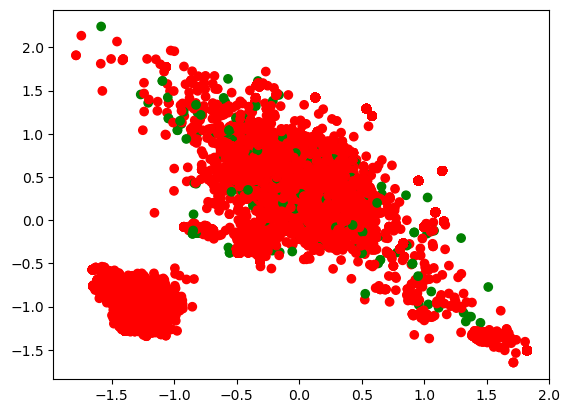
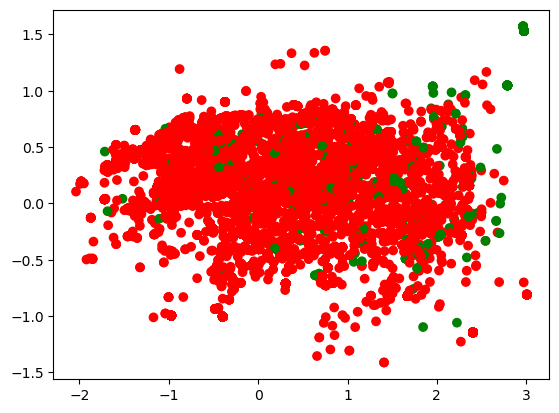
上图就是可视化的一个结果,这个可视化结果好不好,一会我们来做个对比。这是 LSTM,输出的两层,把它的特征嵌入到一个二维的空间里面去了。
接着,咱们用 GCN 去做一个操作L
torch.manual_seed(SEED)
# 输入 dim=307
input_dim_1 = 307
# GCN dim = 100
input_dim_2 = 100
weight_dim_2 = 31
dropout_rate = 0.6
batch_size = 128
max_epochs = 2
# 使用 GCN 做二分类
model_1 = NeuralNetBinaryClassifier(
Model_1_network,
module__input_dim_1 = input_dim_1,
module__input_dim_2 = input_dim_2,
module__weight_dim_2 = weight_dim_2,
module__dropout_rate = dropout_rate,
batch_size = batch_size,
max_epochs = max_epochs,
train_split = None,
optimizer = torch.optim.Adam,
iterator_train__shuffle = True,
device = 'cpu'
)
pipe = Pipeline([
('model', model_1)
])
pipe.fit(X_train, y_train.astype(float))
---
epoch train_loss dur
------- ------------ -------
1 0.1645 15.3332
2 0.0450 15.3720
一样,设 307 维, 中间嵌入到 100 维的特征向量里面去,最大的学习次数也是2。然后设置用 GCN 来做特征提取,接着是做分类器。
运行一下看看运行出来的结果:
代码都差不多,只不过特征提取用的 GCN,用的第二种的拉普拉斯的计算方式。也是训练 2 轮,第一轮是0.1645 的 loss,原来 LSTM 的 loss 是 0.1188,0.1645 感觉好像比它还大一点点。第一轮甚至比 LSTM 还大,那我们清楚,loss 是损失函数,损失函数是越小越好。接着咱们来看第二轮,第二轮是 0.0450, LSTM 的第二轮是 0.0835。这一轮对比就十分民心概念了,所以感觉比原来可能会好一点。那到底好多少,还是要去通过评估。
和之前一样,上面还是全 1 的评估,代码上完全一样:
H_list_model_1.clear()
X_test_predictions_2 = pipe.predict_proba(X_test)[:, 1]
model_evaluate(y_test, np.ones(len(y_test)))
model_evaluate(y_test, X_test_predictions_2)
---
hash t_0 t_1 t_2 t_3 t_4 t_5 t_6 t_7 t_8 ... t_91 t_92 t_93 t_94 t_95 t_96 t_97 t_98 t_99 malware
0 071e8c3f8922e186e57548cd4c703a5d 112 274 158 215 274 158 215 298 76 ... 71 297 135 171 215 35 208 56 71 1
1 33f8e6d08a6aae939f25a8e0d63dd523 82 208 187 208 172 117 172 117 172 ... 81 240 117 71 297 135 171 215 35 1
2 b68abd064e975e1c6d5f25e748663076 16 110 240 117 240 117 240 117 240 ... 65 112 123 65 112 123 65 113 112 1
3 72049be7bd30ea61297ea624ae198067 82 208 187 208 172 117 172 117 172 ... 208 302 208 302 187 208 302 228 302 1
4 c9b3700a77facf29172f32df6bc77f48 82 240 117 240 117 240 117 240 117 ... 209 260 40 209 260 141 260 141 260 1
5 rows × 102 columns
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 43876 entries, 0 to 43875
Columns: 102 entries, hash to malware
dtypes: int64(101), object(1)
memory usage: 34.1+ MB
(43876, 100)
(43876,)
[(0, 1079), (1, 42797)]
39.66357738646895
0
306
[(0, 731), (1, 29982)]
41.015047879616965
[(0, 348), (1, 12815)]
36.82471264367816
epoch train_loss dur
------- ------------ -------
1 0.1188 13.4787
2 0.0835 13.1750
Pipeline
Pipeline(steps=[('model',
<class 'skorch.classifier.NeuralNetBinaryClassifier'>[initialized](
module_=LSTM_network(
(lstm): LSTM(307, 70, batch_first=True)
(dropout): Dropout(p=0.5, inplace=False)
(fc): Linear(in_features=70, out_features=1, bias=True)
),
))])
NeuralNetBinaryClassifier
<class 'skorch.classifier.NeuralNetBinaryClassifier'>[initialized](
module_=LSTM_network(
(lstm): LSTM(307, 70, batch_first=True)
(dropout): Dropout(p=0.5, inplace=False)
(fc): Linear(in_features=70, out_features=1, bias=True)
),
)
Confusion matrix
[TN FP]
[FN TP]
[[ 0 348]
[ 0 12815]]
F1-Score: 0.9866
ROC-AUC: 0.5000
[0.99655116 0.99344033 0.86208236 ... 0.99403644 0.97203976 0.9942034 ]
[1 1 1 ... 1 1 1]
Confusion matrix
[TN FP]
[FN TP]
[[ 94 254]
[ 1 12814]]
F1-Score: 0.9901
ROC-AUC: 0.8677
epoch train_loss dur
------- ------------ -------
1 0.1645 15.3332
2 0.0450 15.3720
Pipeline
Pipeline(steps=[('model',
<class 'skorch.classifier.NeuralNetBinaryClassifier'>[initialized](
module_=Model_1_network(
(gcn): GCN_network()
(dropout): Dropout(p=0.6, inplace=False)
(fc): Linear(in_features=9517, out_features=1, bias=True)
),
))])
NeuralNetBinaryClassifier
<class 'skorch.classifier.NeuralNetBinaryClassifier'>[initialized](
module_=Model_1_network(
(gcn): GCN_network()
(dropout): Dropout(p=0.6, inplace=False)
(fc): Linear(in_features=9517, out_features=1, bias=True)
),
)
Confusion matrix
[TN FP]
[FN TP]
[[ 0 348]
[ 0 12815]]
F1-Score: 0.9866
ROC-AUC: 0.5000
Confusion matrix
[TN FP]
[FN TP]
[[ 201 147]
[ 23 12792]]
F1-Score: 0.9934
ROC-AUC: 0.9726
可以看到,全 1 的评估 F1 值也很高,也是 0.9866,第二轮的 F1 值为 0.9934,比第一轮要高一点点。接着看 AUC,AUC 值为 0.9726,是不是很惊人! 跟 LSTM 一样只是学习了两轮,原来是多少 0.8677,现在是 0.9726,足足提升了将近 11 个点,非常非常好了。
接着还是将曲线绘制出来:
fpr_2, tpr_2, thresholds_2 = roc_curve(y_test, X_test_predictions_2)
plt.plot([0, 1], [0, 1], linestyle='--')
plt.plot(fpr_2, tpr_2)
plt.show()
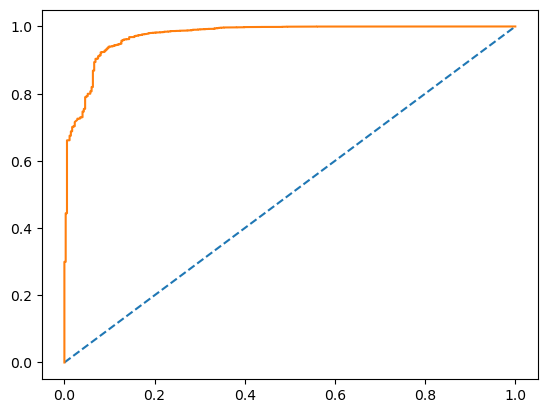
可以看一看,几乎完美。ROC 的面积非常的大,它的面积有0.97这么高。
所以,GCN 的特征提取能力对比 LSTM,这个例子里面比较明显,还是比较强的。后续的分类器其实都是一样的,都是 FC,差别就在特征提取。
然后再把用 GCN 的这张图给画出来,看看他提取出来的特征。
result = torch.zeros(1, 9517)
for i in H_list_model_1:
result = torch.cat([result, i.cpu()], 0)
X_result = result.numpy()[1:]
visualize_pca(X_result, y_test)
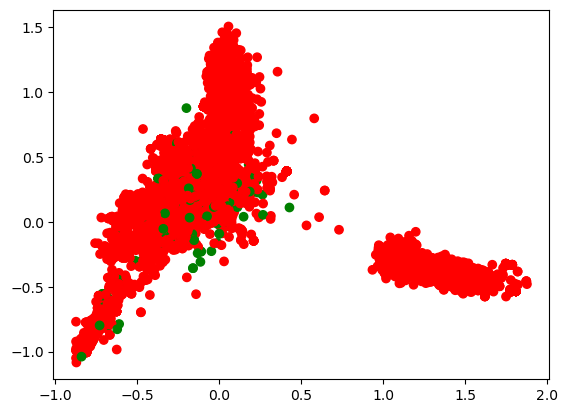
这个提取出来以后放到二维的图里面,跟之前去比,对于模型来说认为这种方式更方便后续的计算。
以上就把整个项目流程给大家讲完了。简单梳理一下,针对目前的这个问题是把它看成了图,只有把它看成图才能用图的 Embedding 的策略。如果把它看成图,提取的是邻接矩阵表的信息。所以前面实际上是自己写了一个邻接矩阵表,就是针对前面输入的数据构造一个邻接矩阵表,提取特征用的是 A,然后通过 GCN 的方式去做一个模拟。
我们跟 LSTM 做了一个对比,相同两轮的情况下 GCN 高了很多。从图的 AUC 以及整个特征的表达上来去看还是能看出来 GCN 的效果会更明显一点。
前两年 GCN 非常的火热,在一些顶会上面也有很多的人去做 GCN 的研究。它的热体现在两个方面,第一个就是在学术上面比较热。总会有一些人用于新的网络模型的一些搭建;还有一个就是工程上也比较热,淘宝早在大概 19 还是 20 年已经把 GCN 用于推荐系统,而且都是全量的方式在使用。
如果对神经网络定义还不太清楚,除了那咱们课上的代码模型跑一跑,最好还是回过头去好好看看我之前关于机器学习的部分基础课程,来理解神经网络到底是怎么一回事,特别是《18. 深度学习 - 从零理解神经网络》 这一章开始往后的几章。
大家更主要的是要去了解,怎么样去利用 GCN 去做特征提取,不是特别的复杂,逻辑应该还是比较清晰的。可能有些语法会不太清楚,可以多去看一看。
对于样本不均衡来说,也能看出来 AUC 的效果比较明显一点。GCN 这套方法可以用的场景还是比较多的,社交网络、知识图谱等,任何非欧几里得数据
,只要看成图都可以用它来做特征提取。
这节课中是对恶意软件的 API 调用序列做了特征提取,把它看成图还是比较直观的。拉普拉斯特征提取的方式有三种,作者在论文里使用的是 Symmetric normalized Laplacian,咱们课程中用的是 Random walk normalized Laplacian,具体的区别大家可以去看上一节课程的内容《34. BI - 美国大学生足球队的 GCN 案例》。
现在咱们一起来想一想,除了本次项目之外,在推荐系统里怎么做呢?
Netflix 是一个电影的网站,经常会让观众给电影来去打分。原来我们做推荐系统的时候并没有看成图,只是看成一个矩阵。其实用户和商品之间是有竞争关系,除了这种维度信息还有一些其他维度信息。比如用户和用户是好友,商品和商品之间可能有相同的导演、相同的分类,它们也有关系。
所以原始数据的特征维度远不只是用户的一个打分情况,可能还会有一些关系的层面,你可以把所有的这些数据都放在一张大图上面来学习。
这里的大图不一定是一种类型的顶点,至少有两种类型的顶点。user 作为 node,还有电影作为 node。这样好处就是,可以一起来做一个联合的训练,既可以得到商品的 Embedding,也可以得到用户的 Embedding。这样一起来做训练可以学出来的维度的信息会更全面一些,所以只要把它看成图就可以做 GCN 的特征提取。
GCN 的使用场景还是比较广泛的,之前的课程里也给大家说了,在朋友圈的投放也是基于图的特征去完成后续的投放,所以特征要选的准。和咱们这节课中找恶意软件是一样的,种子用户特征学的好,后续的推广,分类的结果就会更理想一些。
好,咱们下节课中,就来看看强化学习的内容。
















 2708
2708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











