







目录
神经网络优化中的挑战
Critical Point临界点
gradient为零的点统称为critical point。对抗临界点的两个方法就是batch 和 momentum
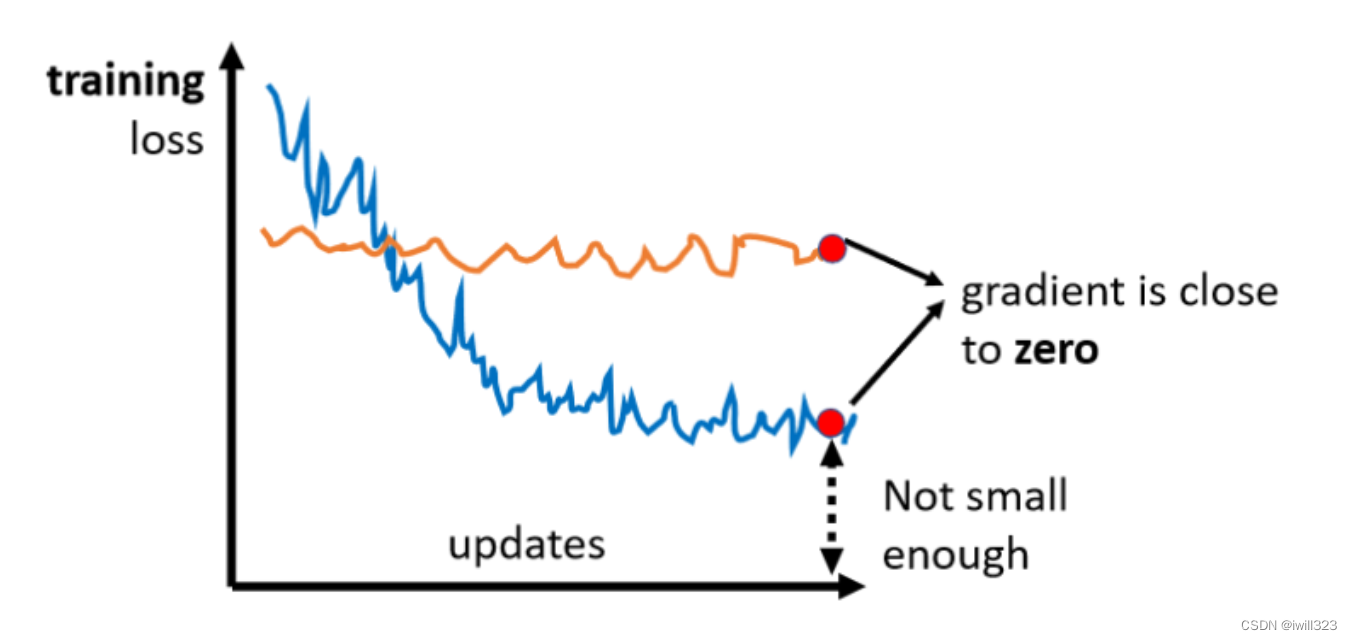
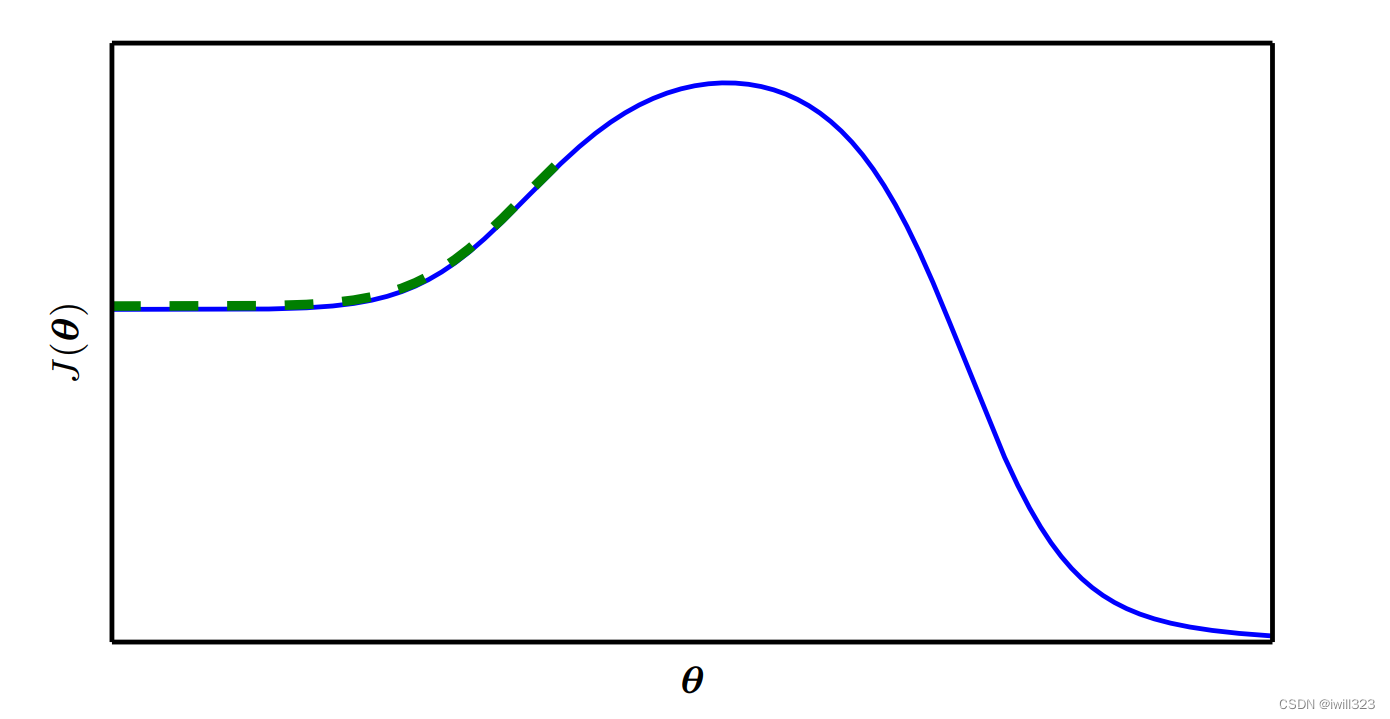
在Optimization的过程中,随着参数不断的update,training loss可能不会再下降,但是此时的loss仍然不符合要求(上图的蓝线)。比如把deep network跟linear model或shallow network比较之后发现发现效果并没有变的更好,就好像deep network没有发挥它完整的力量,此时Optimization显然是有问题的。有时候甚至发现一开始model就train不起来。一开始不管怎么update参数,loss都无法下降(上图中的橙线)。
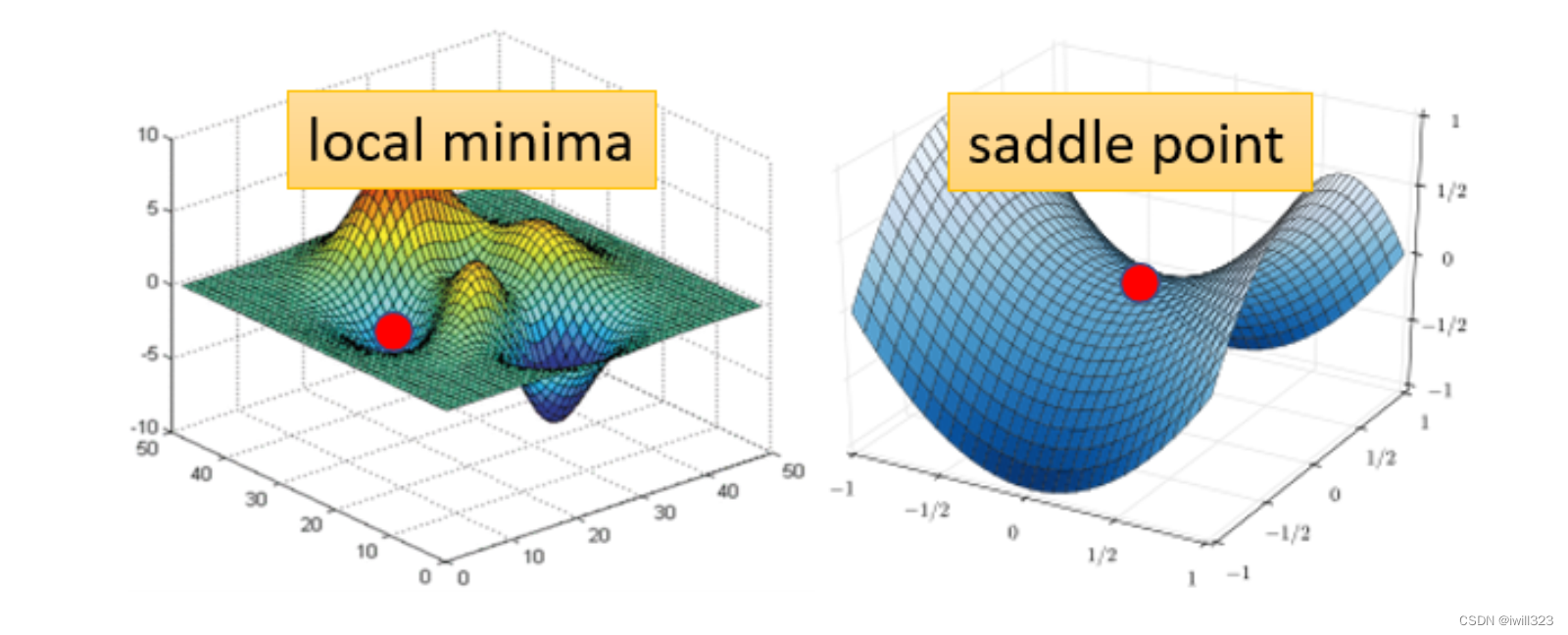
原因可能是梯度接近于 0,导致参数更新的步伐接近于0,所以参数不动,loss也就降不下去。如果是卡在local minima,那可能就没有路可以走了,但如果是卡在saddle point的话,saddle point旁边还是有路可以走的,只要逃离saddle point,就有可能让loss更低
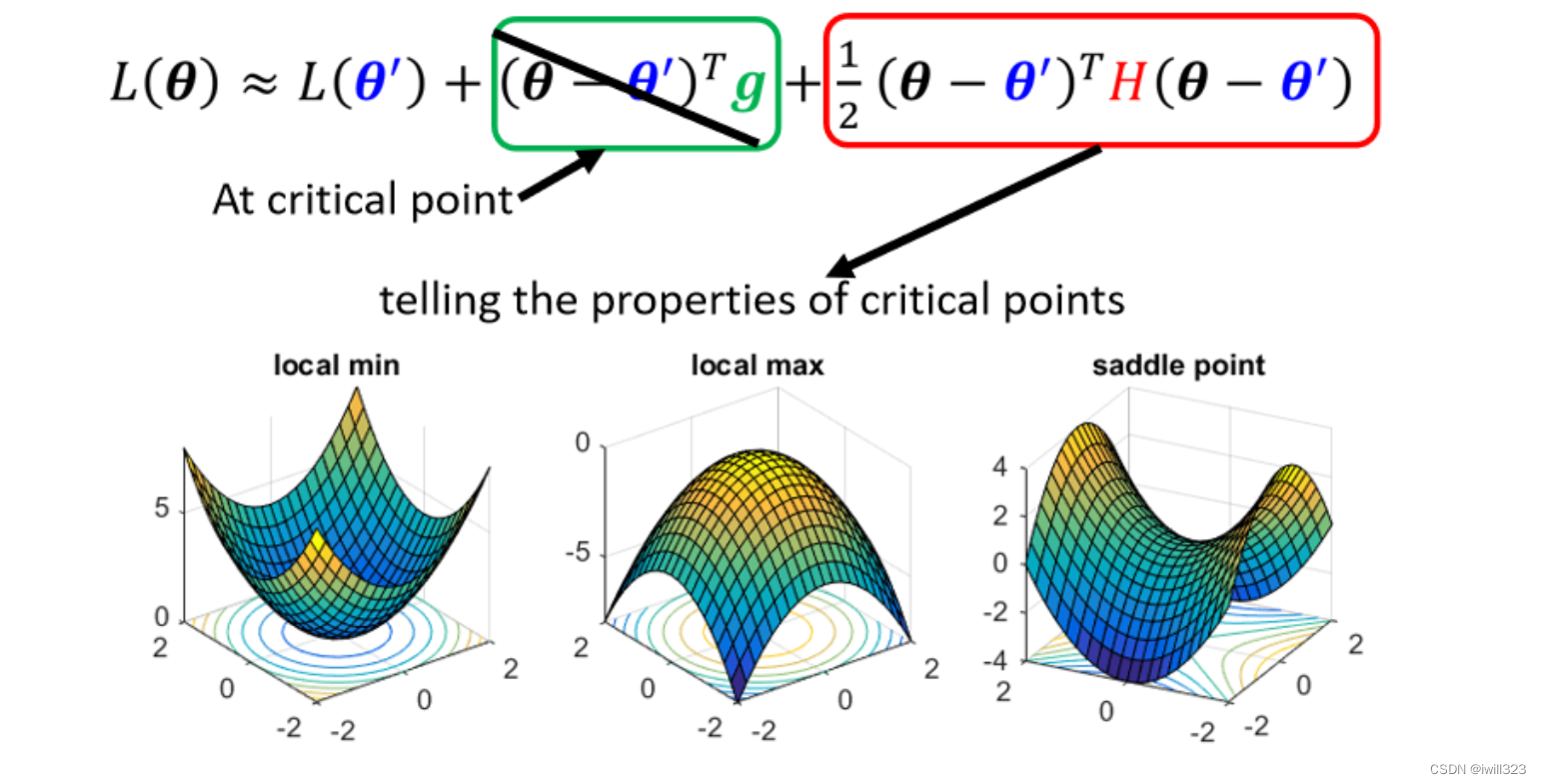
利用泰勒展开式判断临界点的类型
在 θ'附近的 的 loss 函数可以用泰勒展开式近似表示。下图中的纵坐标是 loss 值,横坐标是向量。一阶微分乘自变量差值是 y轴上的绿色长度(可以用tan来理解),二阶微分乘两个自变量差值是 y轴上的红色长度。

Hessian Matrix(黑塞矩阵),它第i个row,第j个column的值就是把θ的第i个component对L作微分,再把θ的第j个component对L作微分
在临界点位置,梯度 g 为 0,所以绿框值为 0,只要知道红框值正负,就知道在θ'附近的error surface到底长什麼样子,就可以判断θ'是一个local minima,还是一个saddle point。
为了方便起见,把(θ-θ')用向量v来表示
- 如果对任何可能的v,vᵀHv都大于零;也就是说现在θ无论为任何值,红色框里面都大于零,也就意味着L(θ)>L(θ'),所以它是local minima。
- 如果反过来说,对所有的v而言,vᵀHv都小于零,也就是说θ无论为任何值,红色框里面都小于零。也就意味着L(θ)<L(θ'),所以它是local maxima。
- 第三个,假设vᵀHv有时候大于零,有时候小于零。代入不同的v进去、代不同的θ进去,红色框里面有时候大于零,有时候小于零。意味着在θ'附近,有时候L(θ)>L(θ')、有时候L(θ)<L(θ'),这说明这是一个saddle point。
但是不可能把所有的v都代入来计算vᵀHv是大于零还是小于零,这有一个更方便的办法。在线性代数中,如果对所有的v,vтHv都大于零,那这种矩阵叫做positive definite(正定矩阵),这类矩阵的所有的eigen value(特征值)都是正的。
如果你发现
- hessian的所有eigen value都是正的,即vᵀHv大于零,也就代表这是一个local minima。
- 如果hessian的所有eigen value都是负的,即vᵀHv小于零,也就代表这是一个local maxima。
- 那如果eigen value有正有负,那就代表是saddle point。

局部极小值
如果局部极小值相比全局最小点拥有很大的代价,局部极小值会带来很大的隐患。学者们现在猜想,对于足够大的神经网络而言,大部分局部极小值都具有很小的代价函数,我们能不能找到真正的全局最小点并不重要,而是需要在参数空间中找到一个代价很小(但不是最小)的点。
一种能够排除局部极小值是主要问题的检测方法是画出梯度范数随时间的变化。如果梯度范数没有缩小到一个微小的值,那么该问题既不是局部极小值,也不是其他形式的临界点。在高维空间中,很难明确证明局部极小值是导致问题的原因。许多并非局部极小值的结构也具有很小的梯度
高原、鞍点和其他平坦区域
对于很多高维非凸函数而言, 局部极小值(以及极大值)事实上都远少于另一类梯度为零的点: 鞍点。多类随机函数表现出以下性质:低维空间中, 局部极小值很普遍;在更高维空间中, 局部极小值很罕见,而鞍点则很常见。对于这类函数 f : -> R而言, 鞍点和局部极小值的数目比率的期望随 n 指数级增长。多数的时候,你觉得你train到一个地方,gradient真的很小,所以参数不再update了,往往是因為你卡在了一个saddle point。
鞍点激增对于训练算法来说有哪些影响呢?对于只使用梯度信息的一阶优化算法而言,目前情况还不清楚。 鞍点附近的梯度通常会非常小。另一方面,实验中梯度下降似乎可以在许多情况下逃离鞍点。
和极小值一样,许多种类的随机函数的极大值在高维空间中也是指数级稀少。也可能存在恒值的、宽且平坦的区域。在这些区域,梯度和 Hessian 矩阵都是零。这种退化的情形是所有数值优化算法的主要问题。在凸问题中,一个宽而平坦的区间肯定包含全局极小值,但是对于一般的优化问题而言,这样的区域可能会对应着目标函数中一个较高的值。
如何确定鞍点处参数更新的方向
鞍点处的H矩阵中,特征值有正有负,这些正负能指导我们更新参数的方向。
假设μ是H的eigen vector(特征向量),λ是u的eigen value特征值。如果把vᵀHv中的v换成μ,由下图中间式子推导可知,特征值λ小于 0,则红色框里的值始终小于 0,也就是说L(θ) < L(θ′),这就是鞍点处 loss能继续下降的方向。所以我们只要令 v = u 即可,也就是θ=θ′ + u,求出负的特征值对应的特征向量,沿着该特征向量的方向更新得到θ,就可以让loss变小。特征向量有无穷多个,取一个即可。

上面讲的利用泰勒展开式判断临界点类型,并用 H矩阵确定参数更新方向的方法,在实际中很少用到,因为二次微分和找特征值、特征向量,需要很大的运算量,不值得。
病态
训练卡住的原因不一定是因为梯度太小,即卡在临界点。下图中,虽然训练loss不再下降,但是梯度的大小有较大的波动(红色框中),并不是真的变得很小,也许遇到的是图中左边这个error surface,梯度在error surface山谷的两个谷壁间不断的来回的震荡,loss不会再减小了。
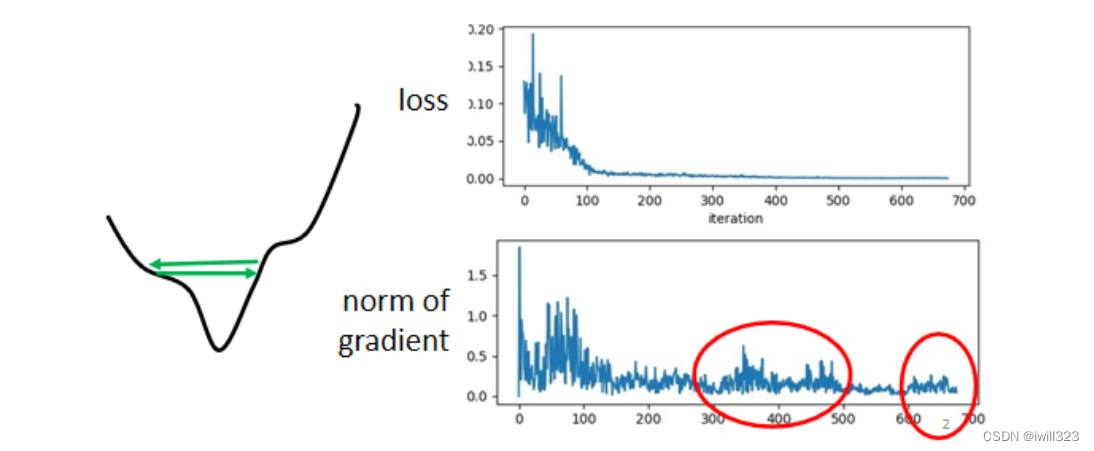
在真实的训练过程中,神经网络通常不会到达梯度很小的区域(除非是用十分特殊的梯度下降训练),这些临界点甚至不一定存在,大多数情况是在梯度还没有变小(或训练到临界点)的时候训练就停下来了。下图给出了一个失败的例子,即使没有局部极小值和鞍点,该例还是不能从局部优化中找到一个良好的代价函数值。
为什么会在非临界点处卡住
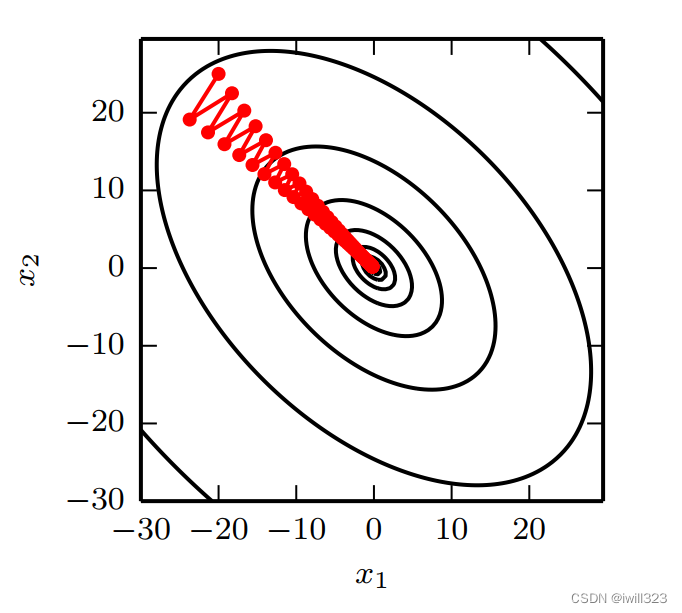
多维情况下,单个点处每个方向上的二阶导数是不同的。 Hessian 的条件数衡量这些二阶导数的变化范围(条件数表征函数相对于输入的微小变化而变化的快慢程度)。当 Hessian 的条件数很差(Hessian 矩阵病态)时,一个方向上的导数增加得很快,而在另一个方向上增加得很慢。 梯度下降不知道导数的这种变化,所以它不知道应该优先探索导数长期为负的方向。 病态条件也导致很难选择合适的步长,可能很小的更新步长也会增加代价函数。步长必须足够小,以免冲过最小值,向具有较强正曲率的方向上升。然而步长太小会导致在其他较小曲率的方向上进展不明显。
见下图,二次函数 f(x)的 Hessian 矩阵条件数为 5 ,这意味着最大曲率方向具有比最小曲率方向多五倍的曲率。红线表示梯度下降的路径。这个非常细长的二次函数类似一个长峡谷, 由于步长有点大,有超过函数底部的趋势,因此需要在下一次迭代时在对面的峡谷壁下降。梯度下降把时间浪费于在峡谷壁反复下降。
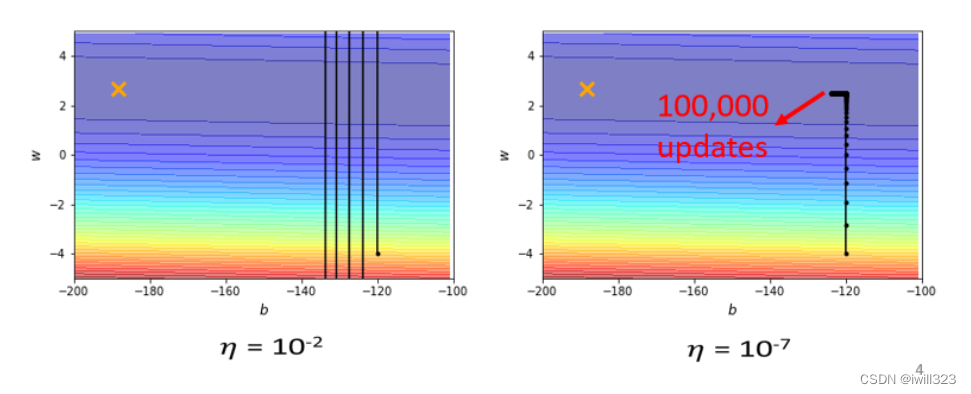
下图error surface 是凸面,横轴参数的梯度变化很小,而纵轴参数的梯度变化快,坡度陡峭。黑点是初始点,叉叉是 loss 最低点。假如设置个较大的 learning rate(左),纵轴参数更新时会振荡,导致loss掉不下去,此时的梯度仍然很大;假如设置个较小的 learning rate(右),纵轴参数能较好更新,而横轴参数却更新很慢,永远走不到终点,因为横轴坡度本来就平缓,再设个小的 lr 更新速度当然更慢了。
梯度消失和梯度爆炸
当计算图变得极深时, 变深的结构使模型神经网络优化算法丧失了学习到先前信息的能力,让优化变得极其困难。梯度消失使得我们难以知道参数朝哪个方向移动能够改进代价函数,而梯度爆炸会使得学习不稳定。多层神经网络通常存在像悬崖一样的斜率较大区域,如图所示。这是由于几个较大的权重相乘,在某些区域会产生非常大的导数。遇到斜率极大的悬崖结构时,梯度下降更新可以使参数弹射得非常远,可能会使大量已完成的优化工作成为无用功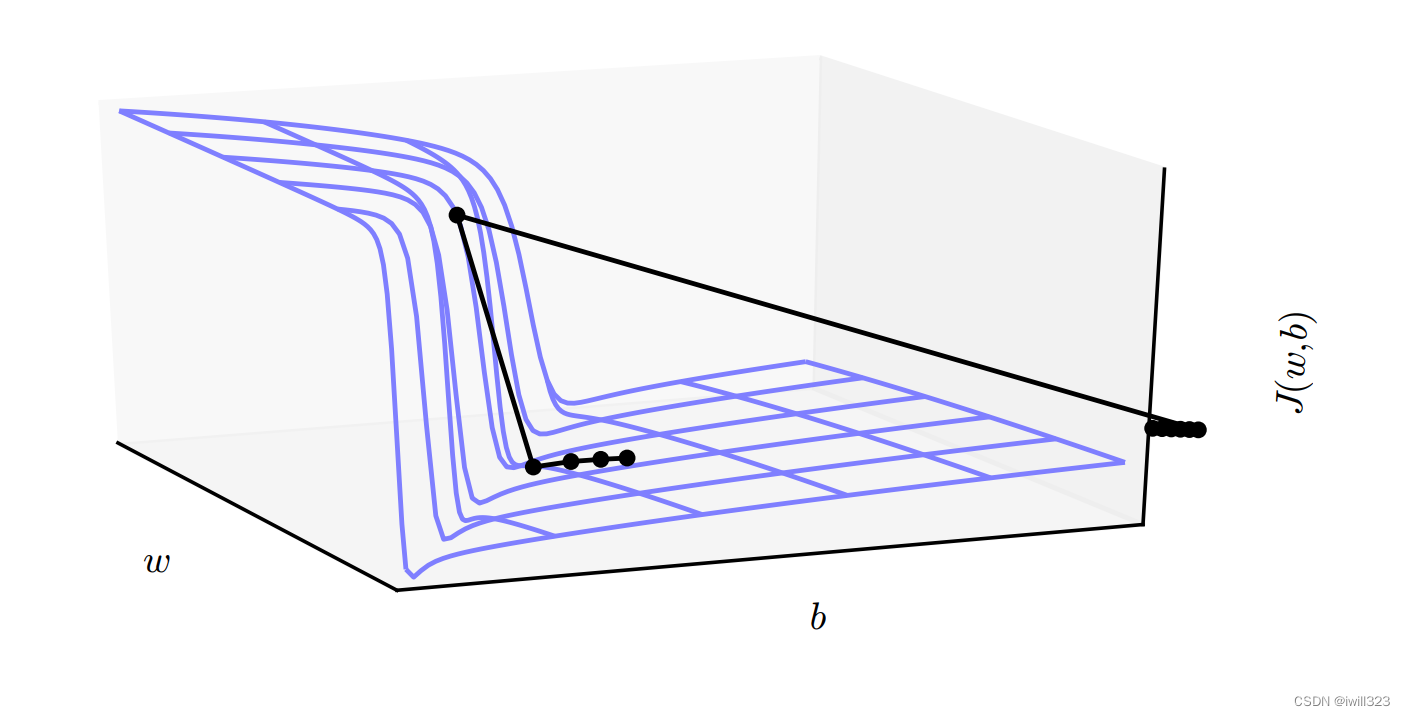
可以用使用梯度截断( gradient clipping)来避免其严重的后果。其基本想法源自梯度并没有指明最佳步长,只说明了在无限小区域内的最佳方向。当传统的梯度下降算法提议更新很大一步时,启发式梯度截断会干涉来减小步长,从而使
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 766
766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









