







论文链接:
https://arxiv.org/abs/2405.15364
Github链接:
https://github.com/ZHU-Zhiyu/NVS_Solver
01 研究目的与结果展示
通过利用预训练的大型视频扩散模型的强大生成能力,我们提出了 NVS-Solver,这是一种新的视角合成(NVS)范式,它在操作时无需训练。NVS-Solver 能够根据给定的视图自适应地调节扩散采样过程,从而从静态场景的单一或多个视图,或动态场景的单目视频中创造出令人瞩目的视觉体验。
具体而言,基于我们的理论建模,我们通过迭代调节得分函数,并用变形的输入视图表示给定场景先验,以控制视频扩散过程。此外,通过理论上探索估计误差的边界,我们根据视图姿态和扩散步骤的数量以自适应的方式进行调节。在静态和动态场景上的广泛评估证实了我们的 NVS-Solver 在定量和定性上都显著优于现有的最先进方法。
接下来我们首先展示,不同环境下的 NVS 渲染结果。首先为基于单图(single-view)的新视点合成。(请关注下图水面的非朗博反射)





同时对于 monocular video,NVS-Solver 也可以生成惊艳的新视点渲染效果。






本文贡献主要聚焦于以下几个方面:
-
我们提出了一种利用预训练的视频扩散模型的无需训练的新视角合成范式;
-
我们从理论上构建了自适应利用给定场景信息以控制视频扩散过程的方法;
-
我们展示了我们的范式在各种场景下显著的性能表现。
02 方法
2.1 基础知识
我们首先快速讲解一下关于 diffusion 的基础知识(详情可见 song yang 大神的一系列论文,与知乎的各路讲解)。
diffusion model 前向为如下公式,其中为 drift 与 diffusion 系数
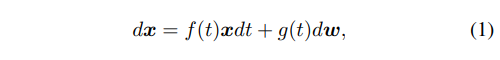
反向过程如下
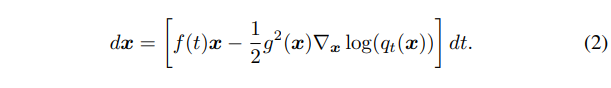
使用可学习的 score function 来估计数据梯度我们可以得到
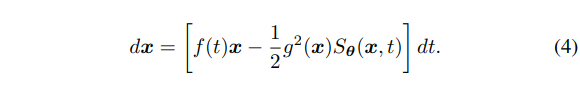
由于当前性能比较突出的 diffusion model 为 stability AI 推出的 SVD,我们基于其 variance exploding(VE)的特性,得到以下 reverse process 的 ODE formulation。并且我们接下来的分析将基于以下 formulation。
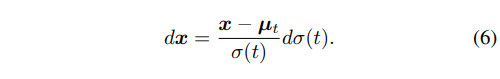
2.2 调制NVS导向的Diffusion Score Function
针对 video diffusion, 我们分解每一帧(其中 表示 diffusion 的 step, 表示某一帧的 pose) 的 diffusion 过程如下
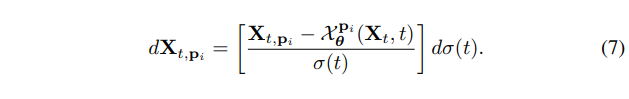
其中 为网络从 noised latent 中得到的对某一帧 的期望, 是 score function 中可学习的部分, 也是我们接下来建模的关键。OK, 得出 diffusion 过程关于不同 pose(也就是 frame) 的 formulation 之后, 我们再来看下, 如何借助已知 view 的信息来辅助修正 score function。这里我们借助到 intensity function 的泰勒展开来关联 target view 和 given views 。
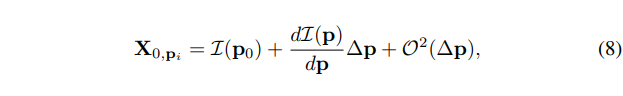
其中表示 intensity function, 代表不同 pose 下观察空间某点的亮度值。由于不同 pose 下同一空间点在 pixel 空间的投影位置不同, 我们利用如下 warp function 可以的到已知 view 在下的投影。其中 为相机参数矩阵, 代表深度值, 为已知像素坐标。
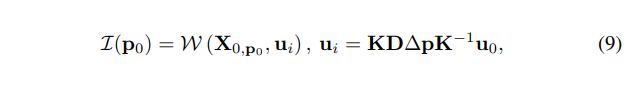
但是真实深度往往不好获得,我们于是再次展开 warp function,得到利用估计深度的如下表示:
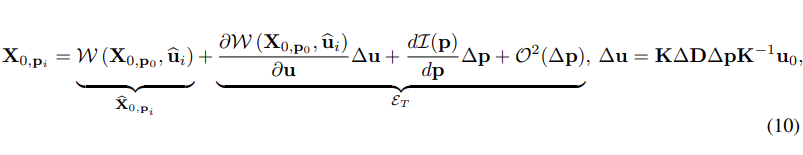
其中估计项, 为对应误差项。在得到 warp 估计项后 我们开始进行 score function 的调制, 特指其可学习部分 Eq.(6)的 或者 Eq. (7) 的。我们将某个 view 的期望表示为两个 terms 组合, 其中 为组合权重。
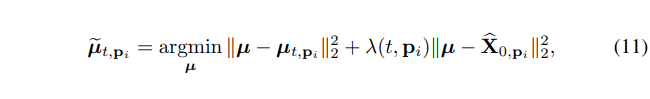
能够非常简单地得到:
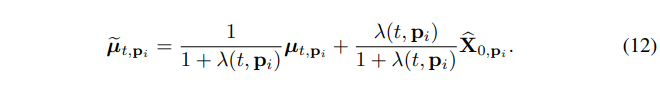
根据如何将的信息注入到 noise latent,我们提出两种 NVS-Solver 的变体:
NVS-Solver(GDS)直接替代到 Eq.(7)中进行 diffusion
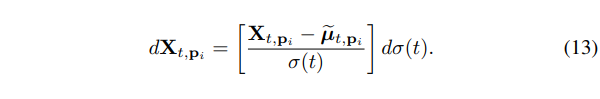
NVS-Solver(Post)后验采样,利用梯度使用 的信息
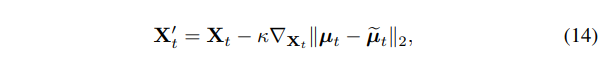
至此,我们初步完成了 NVS-Solver 的框架,但是其中还有一个问题亟待解决就是 的确定。
2.3 确定
我们通过 minimize 整个系统的误差来确定 的解析式,这里我们假定为 optimal 的 value,这里我们可以得到误差的上限为如下表达式
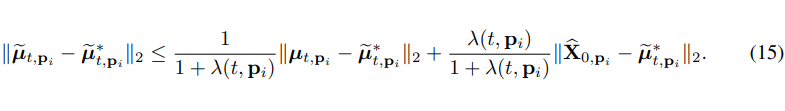
由于具体的误差比较难求,我们退而求其次,一个比较好的策略应该有尽量小的误差期望。
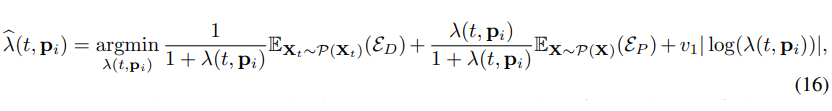
其中, 最后一项为正则化项防止误差 overfitting 到我们 empirically estimated 误差期望上面。接着我们继续分析误差项 和 的特性。对于 diffusion 误差项 , 相关工作证实在噪声相对较大时, score function 会有比较剧烈的变化。同时在高噪声区域, 网络也很难直接预测高质量的图像(当然我们暂时不讨论 recertified flow 和 consistency model 这类)。
所以我们认为误差期望是与噪声强度成正比的。同时对于 intensity 函数截断误差 , 其与 相同, 如公式 10 所示。在忽略高阶项后, 其中变量只有 .(其中 对于某一场景是固定的)。这样我们假设 的期望正比于 。
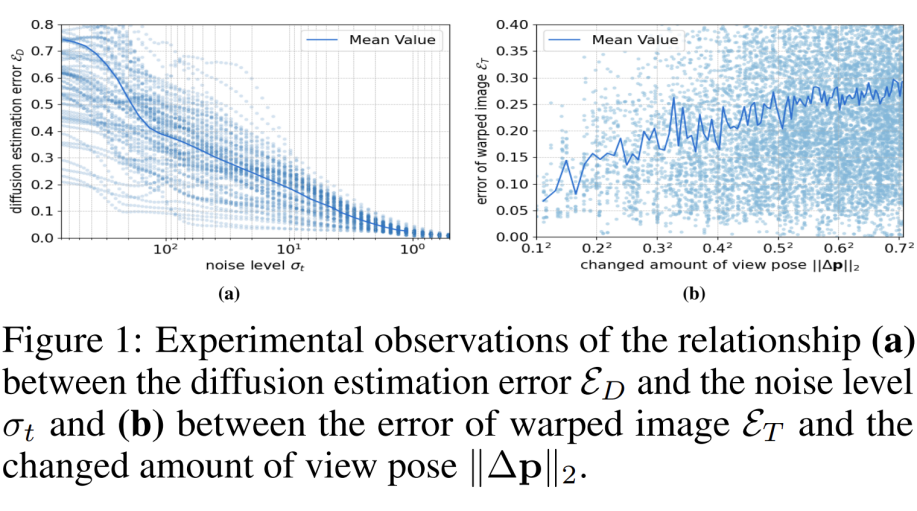
根据我们上面的误差分析和实验验证, 误差项 和 有如上特性。我们最后可以得到 的表达式:
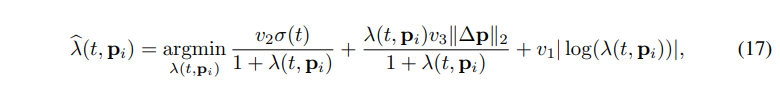
其中 为比例系数, 则其闭式解为:
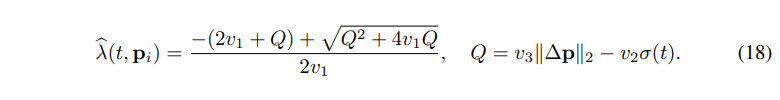
03 消融实验
这里我们进行消融实验,可以看到所提出的方案确实可以减小 warp 的误差第一二四场景( in Eq.10)和非朗博反射体现在 intensity 的展开项的第三场景(in Eq.10)(更多的对比试验请见论文)。
















 88
88

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









