









欧氏变换(Euclidean Transformation)可以看作由平移和旋转构成。
增强现实是将虚拟物体与真实物体融合。为了将三维模型放置在场景中,需要知道它关于摄像机的姿态。可在直角坐标系中使用欧式空间+变换来表示这个姿态。
三维世界中Marker的位置与其对应的二维投影,遵从以下公式:
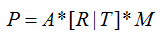
其中,
M表示三维世界中的点;
[R|T]表示欧氏变换,是一个3*4矩阵
A表示相机参数矩阵,存放相机内部参数
P表示M在二维空间的投影,是一个二维点。
在执行标记检测后,需要知道二维情形下标记的四个角点位置(在屏幕空间中的投影)。
位姿估计就是如何获取矩阵A,参数向量M,以及计算变换矩阵[R|T].
1:如何获得相机内参A请参看这篇博客。http://blog.csdn.net/chuhang_zhqr/article/details/49999143
如何导入标定好的相机内参数?
void readCameraParameter()
{
camMatrix = Mat::eye(3, 3, CV_64F);
distCoeff = Mat::zeros(8, 1, CV_64F);
FileStorage fs("/home/zhu/program_c/opencv_study/AR_CV_GL/mastering_opencv/marker_AR/camera_calibration/out_camera_data.yml",FileStorage::READ);
if (!fs.isOpened())
{
cout << "Could not open the configuration file!" << endl;
exit(1);
}
fs["Camera_Matrix"] >> camMatrix;
fs["Distortion_Coefficients"] >> distCoeff;
fs.release();
cout << camMatrix << endl;
cout << distCoeff << endl;
}
void readCameraParameter1()
{
//calibratoin data for iPad 2
camMatrix = Mat::eye(3, 3, CV_64F);
distCoeff = Mat::zeros(8, 1, CV_64F);
camMatrix(0,0) = 6.24860291e+02 * (640./352.);
camMatrix(1,1) = 6.24860291e+02 * (480./288.);
camMatrix(0,2) = 640 * 0.5f; //640
camMatrix(1,2) = 480 * 0.5f; //480,我改的!牛逼不?!
for (int i=0; i<4; i++)
distCoeff(i,0) = 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
2:标识姿态估计:
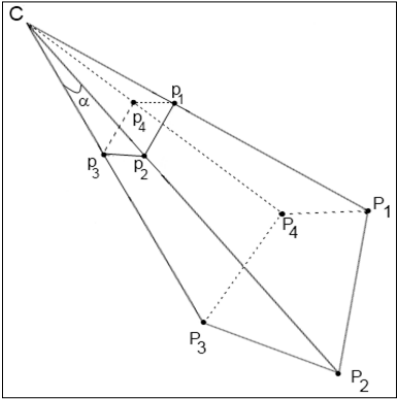
在三维空间中,可通过标记角点的精确位置来估计摄像机与标记之间的变换。此操作称为二维到三维的姿态估计。该估计过程会在物体与摄像机之间找到一个欧式空间的变换,该变换仅由旋转矩阵和平移矩阵构成[R|T]。
如上图所示,C代表相机中心,P1-P4是现实三维世界中的点,p1-p4是物体在相机图像二维平面上投影的点。姿态估计的目标就是找到p1-p4到P1-P4之间的转换关系。

现在p1-p4是已知的,就是在图像平面求到的标识的二维坐标点。
m_markerCorners2d.push_back(Point2f(0,0));
m_markerCorners2d.push_back(Point2f(markerSize.width-1,0));
m_markerCorners2d.push_back(Point2f(markerSize.width-1,markerSize.height-1));
m_markerCorners2d.push_back(Point2f(0,markerSize.height-1));
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
P1-P4如何求呢:
标记总是方形且所有顶点都在一个平面,可将标记放在XY平面上(Z分量为0),其标记的中心为点(0.0,0.0,0.0)。坐标系统的起始处就是标记的中心(Z轴是与标记平面垂直)。
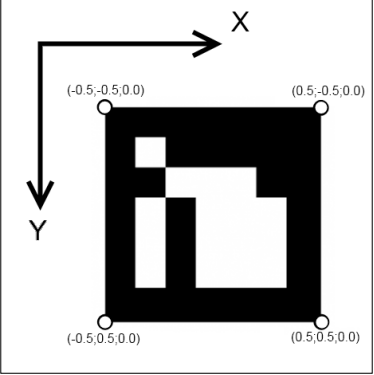
m_markerCorners3d.push_back(Point3f(-0.5f,-0.5f,0)); m_markerCorners3d.push_back(Point3f(+0.5f,-0.5f,0)); m_markerCorners3d.push_back(Point3f(+0.5f,+0.5f,0)); m_markerCorners3d.push_back(Point3f(-0.5f,+0.5f,0));然后借助OpenCV的solvePnP函数获取欧氏转换[R|T]。
//对每一个标记,求出其相对于相机的转换矩阵。找到上面监测到的标记的位置
void MarkerDetector::estimatePosition(vector<Marker>& detectedMarkers,Mat_<float>& camMatrix,Mat_<float>& distCoeff)
{
for(size_t i=0;i<detectedMarkers.size();i++)
{
Marker& m = detectedMarkers[i];
Mat Rvec;
Mat_<float> Tvec;//Mat_<float>对应的是CV_32F
Mat raux,taux;
//寻找物体投影的三维坐标和二维坐标之间的对应关系,利用已知的平面四点坐标确定摄像头相对世界坐标系的平移和旋转。在物体深度变化相对于物体到摄像机的距离比较大的时候,这个函数比较好。输出旋转向量和位移向量。
/*solvePnP( InputArray _opoints, InputArray _ipoints,
InputArray _cameraMatrix, InputArray _distCoeffs,
OutputArray _rvec, OutputArray _tvec, bool useExtrinsicGuess )
_opoints是对象坐标系的对象点集数组,应该是std::vector<cv::Point3f>对象,此处我们传标记的3维坐标系(4个点的集合)。
_ipoints是对象所对应的图像点(投影)数组。参数应该是std::vector<cv::Point2f> 或者 cv::Mat- 2 x N / N x 2,其中N是点的数量,这里我们传递我们发现的标记的角点。
_cameraMatrix:是相机的内参矩阵。
_distCoeffs:这是输入4 x 1,1×4、5 x 1或1 x 5向量的畸变系数(k1,k2,p1,p2,[k3])。如果它是空的,所有的畸变系数设置为0。
_rvec是输出把点从模型坐标系转换到相机坐标系的旋转向量。
_tvec同上,这里是输出平移向量。
useExtrinsicGuess如果是true,那么这个函数就会使用_rvec和_tvec分别作为初始的近似旋转和平移向量,然后再进一步优化。
我们用这个函数去计算相机转换将最大限度减少投影误差,也就是观察到的投影和预计的投影之间的距离平方和。
估计的转换是由旋转(rotation)(_rvec)和转换(translation)组件(_tvec)构成。这也就是所谓的欧氏变换或刚性变换。
刚性变换被定义为当一个装换作用在任何向量v,产生转换向量T(v)的形式:
T(v) = R v + t
RT=R-1(即R是一个正交变换),t是原始转换的向量,一个刚性转换满足:
det(R) = 1
这意味着R不产生反射,因此它代表一个旋转(一个保持定向正交变换)。
为了获得一个3×3旋转矩阵的旋转向量,我们将使用cv::Rodrigues 。该函数通过旋转的向量转换一个旋转参数并返回其等效旋转矢量旋转矩阵。
注:因为上面的solvePnP函数找到了相机相对于3维空间中的标记的位置,因此我们必须转换我们的成果。因此我们将得到的转换将在相机坐标系中描述标记的转换,这显然对渲染引擎更加友好。*/
//solvePnP(m_markerCorners3d,m.points,camMatrix,distCoeff,raux,taux);
solvePnP(m_markerCorners3d,m.points,camMatrix,distCoeff,raux,taux);
raux.convertTo(Rvec,CV_32F);//转换Mat的保存类型,输出Rvec
taux.convertTo(Tvec,CV_32F);
Mat_<float> rotMat(3,3);
Rodrigues(Rvec,rotMat);//罗德里格斯变换对旋转向量和旋转矩阵进行转换,输出旋转矩阵
//Copy to transformation matrix,复制旋转矩阵到标识的类变量中
for(int col=0;col<3;col++)
{
for(int row=0;row<3;row++)
{
m.transformation.r().mat[row][col] = rotMat(row,col);//copy rotation component
}
m.transformation.t().data[col] = Tvec(col);//copy translation component//复制位移向量到标识类的变量
}
//since solvePnP finds camera location,w.r.t to marker pose,to get marker pose w.r.t to the camera we invert it.
//slovePnP得到了相机相对于标识的旋转矩阵和位移向量,下面将得到标识相对于相机的旋转矩阵和位移向量。反转这个矩阵
m.transformation = m.transformation.getInverted();
}
}solvePnP(m_markerCorners3d, m.points, camMatrix, distCoeff,raux,taux);
m_markerCorners3d:Marker在三维空间坐标
m.points:Marker在二维平面坐标
camMatrix:相机内置参数
distCoeff:失真系数,本例全零
raux:旋转矩阵R
taux:平移矩阵T这个函数求得的变换是相机相对于3维空间中的标记的位置,因此我们必须反转矩阵得到的变换,求出标记在相机坐标系统中的变换,有利于进行三维渲染。
在求得旋转和平移矩阵后,可以在Marker的位置上画些东西了。我们画一个虚拟平面和一个三维坐标系,然后利用刚才的欧氏变换矩阵按照下式将三维坐标转换成相机二维平面里的坐标,式中v表示三维坐标向量。这里展示图像采用Opengl工具。
3:采用OpenGL函数渲染场景。3D可视化是增强现实的核心部分,OpenGL为创建高质量渲染提供了所有的基本功能,并且是跨平台渲染系统的唯一选择。
使用OpenGL绘制三维物体的过程:
1.清除场景。
2.启动正射投影绘制背景。
3.在视口绘制最后一个从相机获取到的图像。
4.根据相机内在参数设置透视投影。
5.把每个侦测到的标记的坐标系移动到标记的3维位置(把4x4的变换矩阵应用到opengl的模型矩阵上)。
6.呈现一个任意的3维物体。
7.展示帧缓存。
在主函数中调用的函数:
imwrite("test.bmp",src);//获取最新的一副图像,写入test.bmp
show("test.bmp",argc,argv,camMatrix, markers);//核心函数int show(const char* filename,int argc, char** argv,Mat_<float>& cameraMatrix, vector<Marker>& detectedMarkers)
{
//打开文件
FILE* pfile=fopen(filename,"rb");
if(pfile == 0) exit(0);
//读取图像大小
fseek(pfile,0x0012,SEEK_SET);
fread(&imagewidth,sizeof(imagewidth),1,pfile);
fread(&imageheight,sizeof(imageheight),1,pfile);
//计算像素数据长度
pixellength=imagewidth*3;
while(pixellength%4 != 0)pixellength++;
pixellength *= imageheight;
//读取像素数据
pixeldata = (GLubyte*)malloc(pixellength);
if(pixeldata == 0) exit(0);
fseek(pfile,54,SEEK_SET);
fread(pixeldata,pixellength,1,pfile);
//**以上是读取一个bmp图像宽高和图像数据的操作**
//关闭文件
fclose(pfile);
build_projection(cameraMatrix); //这是建立摄像机内参数矩阵,就是相机矩阵,display函数开始导入的模型就是相机矩阵
setMarker(detectedMarkers); //导入找到的标识
//初始化glut运行
glutInit(&argc,argv);
glutInitDisplayMode(GLUT_DOUBLE|GLUT_RGBA);
glutInitWindowPosition(100,100);
glutInitWindowSize(imagewidth,imageheight);
glutCreateWindow(filename);
glutDisplayFunc(&display);
glutMainLoop();
//-------------------------------------
free(pixeldata);
return 0;
}1):首先把test.bmp图像的宽高和数据读进来,然后build_projection(cameraMatrix); 就是用相机的内参数矩阵调整OpenGL投影矩阵,这一步是必须的,不然会得到错误的透视投影,会使人造物体看上去不真实。
void build_projection(Mat_<float> cameraMatrix)
{
float near = 0.01; // Near clipping distance
float far = 100; // Far clipping distance
// Camera parameters
//float f_x = cameraMatrix.data[0]; // Focal length in x axis
//float f_y = cameraMatrix.data[4]; // Focal length in y axis (usually the same?)
//float c_x = cameraMatrix.data[2]; // Camera primary point x
//float c_y = cameraMatrix.data[5]; // Camera primary point y
float f_x = cameraMatrix(0,0); // Focal length in x axis
float f_y = cameraMatrix(1,1); // Focal length in y axis (usually the same?)
float c_x = cameraMatrix(0,2); // Camera primary point x
float c_y = cameraMatrix(1,2); // Camera primary point y
projectionMatrix.data[0] = - 2.0 * f_x / imagewidth;
projectionMatrix.data[1] = 0.0;
projectionMatrix.data[2] = 0.0;
projectionMatrix.data[3] = 0.0;
projectionMatrix.data[4] = 0.0;
projectionMatrix.data[5] = 2.0 * f_y / imageheight;
projectionMatrix.data[6] = 0.0;
projectionMatrix.data[7] = 0.0;
projectionMatrix.data[8] = 2.0 * c_x / imagewidth - 1.0;
projectionMatrix.data[9] = 2.0 * c_y / imageheight - 1.0;
projectionMatrix.data[10] = -( far+near ) / ( far - near );
projectionMatrix.data[11] = -1.0;
projectionMatrix.data[12] = 0.0;
projectionMatrix.data[13] = 0.0;
projectionMatrix.data[14] = -2.0 * far * near / ( far - near );
projectionMatrix.data[15] = 0.0;
} 这段代码是由摄像机标定矩阵所创建的OpenGL投影矩阵。有了这个矩阵传递给OpenGL后,就可以画一些人造物体了。
2):任何一个变换都能够被4x4矩阵呈现并且载入到OpenGL模型视图矩阵,这一步将会把坐标系移动到世界坐标系中的标记处。
例如,让我们在每个标记的上方绘制一个坐标轴-它将会展示标记的在空间中的方向,并用渐变的矩形填充整个标记。这个视觉化操作将会像预期一样给我们视觉上反馈。
void display(void)
{
glClear(GL_COLOR_BUFFER_BIT|GL_DEPTH_BUFFER_BIT);
//绘制图片,第一、二、三、四个参数表示图象宽度、图象高度、像素数据内容、像素数据在内存中的格式,最后一个参数表示用于绘制的像素数据在内存中的位置
glDrawPixels(imagewidth,imageheight,GL_BGR_EXT,GL_UNSIGNED_BYTE,pixeldata);
/*
glMatrixMode - 指定哪一个矩阵是当前矩阵
mode 指定哪一个矩阵堆栈是下一个矩阵操作的目标,可选值: GL_MODELVIEW、GL_PROJECTION、GL_TEXTURE.
说明
glMatrixMode设置当前矩阵模式:
GL_MODELVIEW,对模型视景矩阵堆栈应用随后的矩阵操作.
GL_PROJECTION,对投影矩阵应用随后的矩阵操作.
GL_TEXTURE,对纹理矩阵堆栈应用随后的矩阵操作.
与glLoadIdentity()一同使用
glLoadIdentity():该函数的功能是重置当前指定的矩阵为单位矩阵。
在glLoadIdentity()之后我们为场景设置了透视图。glMatrixMode(GL_MODELVIEW)设置当前矩阵为模型视图矩阵,模型视图矩阵储存了有关物体的信息。
*/
//绘制坐标 ,导入相机内参数矩阵模型
glMatrixMode(GL_PROJECTION);
glLoadMatrixf(projectionMatrix.data);
glMatrixMode(GL_MODELVIEW);
glLoadIdentity();
glEnableClientState(GL_VERTEX_ARRAY); //启用客户端的某项功能
glEnableClientState(GL_NORMAL_ARRAY);
glPushMatrix();
glLineWidth(3.0f);
float lineX[] = {0,0,0,1,0,0};
float lineY[] = {0,0,0,0,1,0};
float lineZ[] = {0,0,0,0,0,1};
const GLfloat squareVertices[] = {
-0.5f, -0.5f,
0.5f, -0.5f,
-0.5f, 0.5f,
0.5f, 0.5f,
};
const GLubyte squareColors[] = {
255, 255, 0, 255,
0, 255, 255, 255,
0, 0, 0, 0,
255, 0, 255, 255,
};
for (size_t transformationIndex=0; transformationIndex<m_detectedMarkers.size(); transformationIndex++)
{
const Transformation& transformation = m_detectedMarkers[transformationIndex].transformation;
Matrix44 glMatrix = transformation.getMat44();
//导入相机外参数矩阵模型
glLoadMatrixf(reinterpret_cast<const GLfloat*>(&glMatrix.data[0])); //reinterpret_cast:任何类型的指针之间都可以互相转换,修改了操作数类型,仅仅是重新解释了给出的对象的比特模型而没有进行二进制转换
glVertexPointer(2, GL_FLOAT, 0, squareVertices); //指定顶点数组的位置,2表示每个顶点由三个量构成(x, y),GL_FLOAT表示每个量都是一个GLfloat类型的值。第三个参数0。最后的squareVertices指明了数组实际的位置。这个squareVertices是由第一个参数和要画的图形有几个顶点决定大小,理解。
glEnableClientState(GL_VERTEX_ARRAY); //表示启用顶点数组
glColorPointer(4, GL_UNSIGNED_BYTE, 0, squareColors); //RGBA颜色,四个顶点
glEnableClientState(GL_COLOR_ARRAY); //启用颜色数组
glDrawArrays(GL_TRIANGLE_STRIP, 0, 4);
glDisableClientState(GL_COLOR_ARRAY);
float scale = 0.5;
glScalef(scale, scale, scale);
glColor4f(1.0f, 0.0f, 0.0f, 1.0f);
glVertexPointer(3, GL_FLOAT, 0, lineX);
glDrawArrays(GL_LINES, 0, 2);
glColor4f(0.0f, 1.0f, 0.0f, 1.0f);
glVertexPointer(3, GL_FLOAT, 0, lineY);
glDrawArrays(GL_LINES, 0, 2);
glColor4f(0.0f, 0.0f, 1.0f, 1.0f);
glVertexPointer(3, GL_FLOAT, 0, lineZ);
glDrawArrays(GL_LINES, 0, 2);
}
glFlush();
glPopMatrix();
glDisableClientState(GL_VERTEX_ARRAY);
glutSwapBuffers();
} 一些对OpenGL函数的补充分析在http://blog.csdn.net/chuhang_zhqr/article/details/50036513
至此,大致的程序分析结束了,在Linux系统上可以实现该程序。

现在我们并没有为可视化运用3维渲染引擎,但是我们已经获得了所有必须的数据,让我们总结下我们所得:
1.来自相机的BGRA格式的一帧
2.正确的用作AR场景渲染的透视投影的矩阵
3.发现的标记姿态列表
你能够很简单的把这些数据运用到你自己的AR应用中。
如你所见,渐变填充的管道和支点都被准确的放在标记上。这个是增强现实应用的关键-真实图片和虚拟物体的无缝融合!
参考:http://blog.csdn.net/chuhang_zhqr/article/details/50036443















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









