







许多重要问题都可以抽象为变长序列学习问题(sequence to sequence learning),如语音识别、机器翻译、字符识别。这类问题的特点是,1) 输入和输入都是序列(如连续值语音信号/特征、离散值的字符),2) 序列长度都不固定,3)并且输入输出序列长度没有对应关系。因此,传统的神经网络模型(DNN, CNN, RNN)不能直接以端到端的方式解决这类问题的建模和学习问题。
解决变长序列的端到端学习,目前有两种主流的思路:一种是 CTC (Connectionist Temporal Classification,连接时序分类);另一种是 Encoder-Decoder(以下简称 En-De)的思路。CTC 最早用于手写体字符识别上[19],并且一度是语音识别的研究热点[20-23]。这里,我们关注的是后一种思路。
变长序列学习的 En-De 方法中,本文重点关注 Google 和 Yoshua Bengio 两个团队的工作。这两个团队这个方向上研究都比较早,也分别能代表性工业界和学界的风格。
下面首先介绍 Google 的 seq2seq 模型,然后介绍 Bengio 团队的 RNNenc 模型。可以看到两种模型基本思路一致,但在具体细节上,有着显著的不同。至于 attention-base encoder-decoder,则会在将来另文讨论。
1. seq2seq 模型
1.1 模型结构
Seq2seq 模型由文章[5]为解决机器翻译问题提出,其中基本结构可以由图1概括。
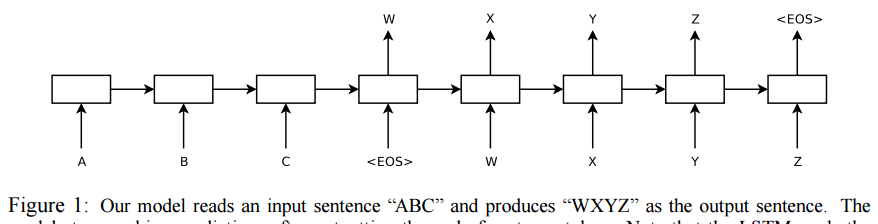
图1 seq2seq 模型 [5]
seq2seq 模型由 encoder(编码器) 和 decoder(解码器)两部分组成。
1. encoder 是一个若干层的 RNN 网络。输入序列由 encoder 从左到右,依次处理,得到各层最后一个 timestep 的隐层状态。
2. decoder 是一个与 encoder 结构完成相同的 RNN 网络。本质上,decoder 是一个 RNN 语言模型(RNNLM)[2,3]。decoder 的输入是 + ground truth,对应的目标输出是 ground truth + 。其中, 是一个特殊的符合,用来标记序列的开始和结束。
可以看到,decoder 是一个典型的输入输出一一对应的监督学习结构,因此,可以用常规的方法进行训练。与 RNNLM 唯一的不同在于,encoder 的各层 RNN 的初始状态是于 encoder 的最后 timestep 的状态复制而来。因此,encoder 是一个条件化的(conditional) RNNLM,它所依赖的条件(condition)即是由 encoder 编码而来的信息(隐层状态)。
通过隐层状态的共享(复制),在训练过程中,decoder 的误差可以返传回 encoder,从而实现端到端的训练。
一个由于三层 LSTM 构成的 seq2seq 模型如图2所示。
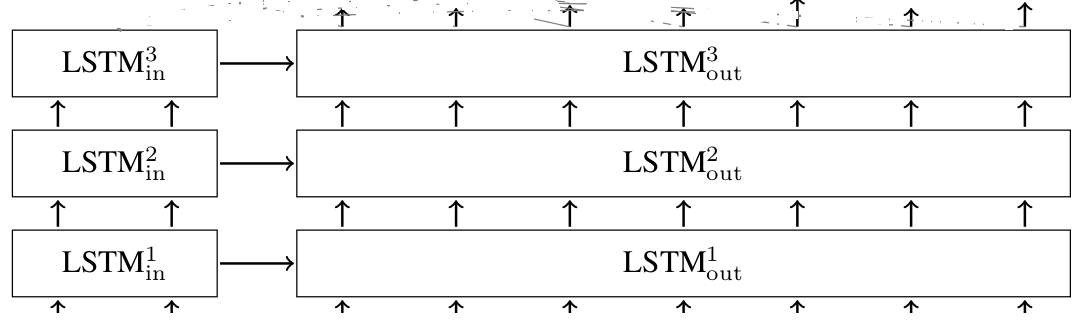
图2 3层 LSTM seq2seq
实验对比
如果把 seq2seq 视作 conditional RNNLM,很难想象,这种略显”简陋”的模型能为我们做什么严肃的事情。也许是 deep learning 就自带三分 black art 属性。
实验是在 WMT’14 英语到法语的翻译任务上进行的。具体实验设置和训练见文献[5]。值得指出的是,输入序列(source sentences)是按逆序处理的(e.g. good morning . -> . morning good),实验表明这样能够显著改善模型性能。
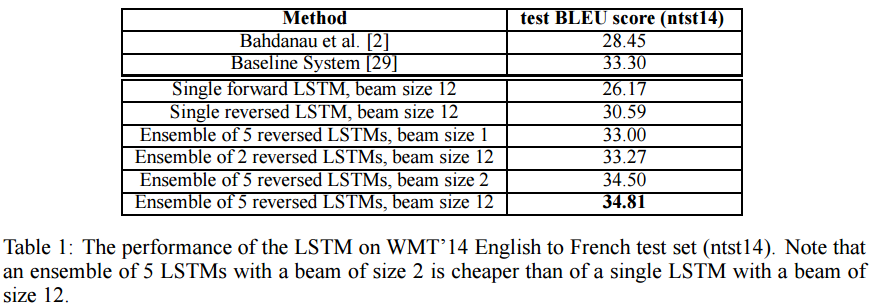
图3 seq2seq 模型性能(得分越大越好)[5]
直接用训练好的系统进行测试,结果如图3。基于 seq2seq 的模型,性能已经好于当时 attention 机制的 NTM(图3第一行,介绍 attention 模型时会讨论)(注:放这里比较不公平,两个模型参数量相差很多)。Emsemble 5个后,性能超过了基线系统。

图 4 用 seq2seq 做 rescore 的性能 [5]
如果将 seq2seq 用于 rescore,可以看到,性能已经明显好于基线,虽然还是要比最好的系统差。
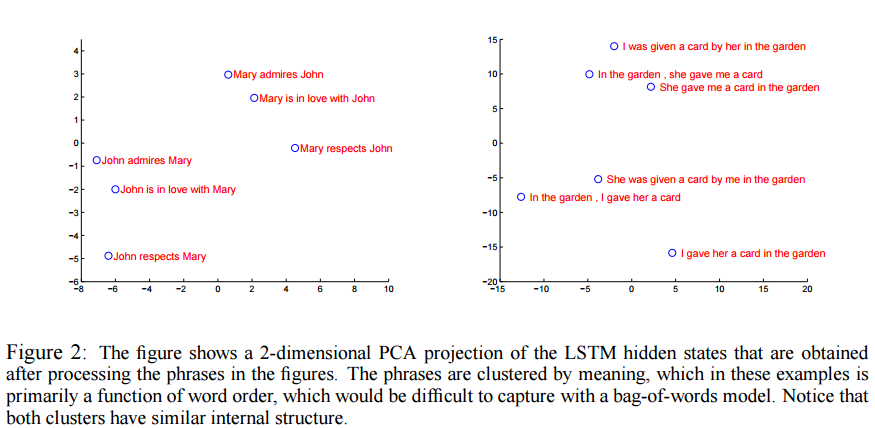
图5 encoder 隐层状态分布(PCA 降到 2 维)[5]
最后,图5展示了 encoder 得到最后的隐层状态。直觉上,encoder 确实编码到了有用的语义信息(sent2vector)。
由实验结果可知,前途是光明的,过程是曲折的:1) seq2seq 确实能很好的解决 nontrivial 的问题(机器翻译);2)基于 seq2seq 的系统还不足以取代翻译系(和 state-of-the-art 差距还很大)。
使用完全相同的模型,将平行语料数据替换为对话的文本数据,就可以训练一个数据驱动的对话系统 [6]。
source code
基于已有的 RNN 实现 seq2seq 只需要很少很少的代码量 。比如,Google 官方的 seq2seq 实现(tensorflow)。
Variant: image captioning
以上是标准的 seq2seq 的模型。在一些应用场景下可以需要灵活的变通。比如 [7] 中的“看图说话”任务(Image captioning)(图6)。
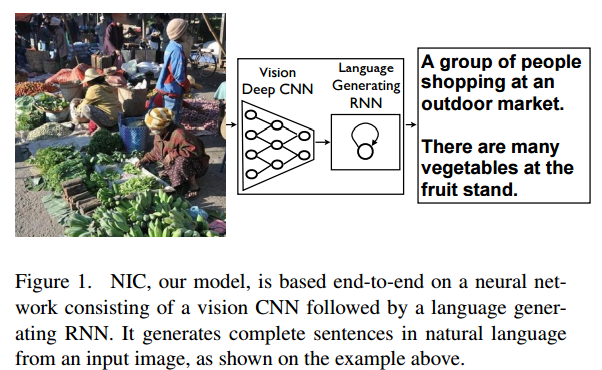
图6 自动生成图像标题/描述[7]
原则上,我们可以把图像做为一个序列,直接应用 seq2seq 模型。然而,我们知道,在 CV 领域,已经发展出了许多以 CNN 为核心的网络结构及(在大量数据集上)预训练好的网络权值,这些网络在图像领域被证明是非常效的。
为了利用已有成果,[7] 对 seq2seq 进行了一些合理改造。1) encoder 替换为一个在 ImageNet 上预训练好的 Inception CNN,最后一层的输出做为 encoder 的编码结果; 2) 由于 encoder-decoder 对称性的破坏,将编码结果做为 decoder RNN 的第一步输入,做为 condition 注入 decoder。
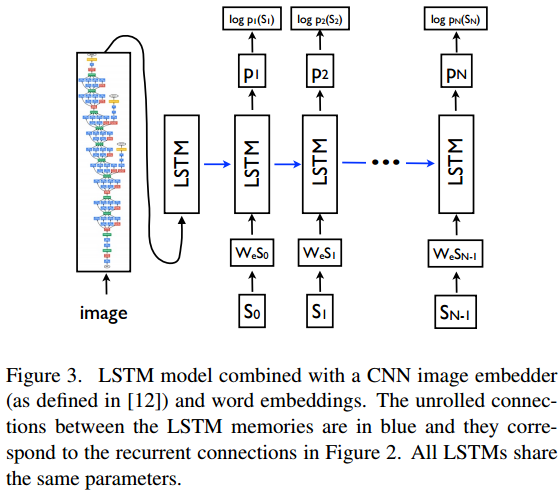
图7 Structure of Neural Image Caption Generator[7]
RNNenc 模型
与 seq2seq [5] 的工作几乎同时,Bengio 团队也提出了一种思想上很类似的 Encoder-Decoder 模型[8]。
但由于 Bengio 团队很快转向了性能更好的 attention-based Encoder-decoder 模型,因此这个模型的生命周期只有短短几个月。([8] 的更重要的一点在于提出了 GRU 模型)。这里依然介绍 RNNenc 是因为,一方面可以和 seq2seq 对照,可以明显看到业界和学界研究风格的差别;另一方面,由 RNNenc 可以更自然的扩展出 attention-based encoder-decoder。
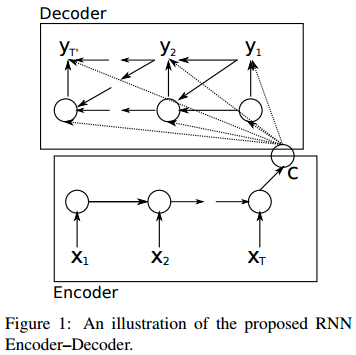
图8 RNNenc[8]
模型结构
RNNenc 模型的基本结构如图8所示。
1. Encoder 没有采用 vanilla RNN 或 LSTM,而是新提出了一个类似 LSTM 的 RNN,称为 GRU(Gated Recurrent Unit)。经验研究表明 LSTM 和 GRU 的性能相当[23][24]。不过 GRU 少个 gate,计算量会少一些。
encoder vector 是最后一层的状态,并且作为 decoder 的每一步的输入的一部分。
Decoder 也是 GRU, 当前状态由上一步状态及输入(编码向量 c 、历史解码结果)计算得到。
因为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1892
1892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









