







训练自己的 AI 模型比你想象的要容易得多。
我将向你展示如何仅使用基本的开发技能来做到这一点,对我们来说,这种方式比使用 OpenAI 提供的现成大型模型更快、更便宜、效果更好。
但首先,为什么不直接使用 LLM?
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、为什么不直接使用 LLM?
根据我们的经验,我们尝试将 LLM 应用于我们的问题,例如 OpenAI 的 GPT-3 或 GPT-4,但结果对我们的用例非常令人失望。它非常慢、非常昂贵、非常不可预测,并且很难定制。
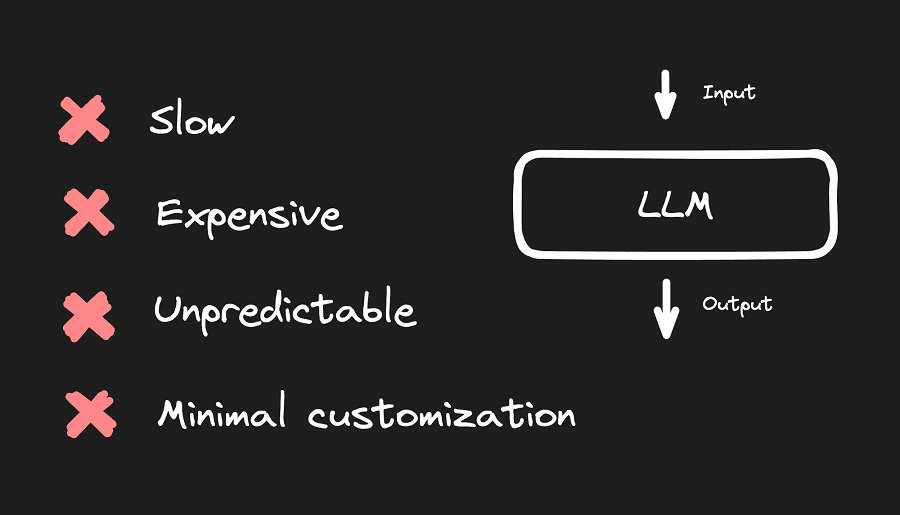
因此,我们改为训练自己的模型。
这并不像我们预期的那么具有挑战性,而且由于我们的模型很小且很专业,因此结果就是它们的速度快了 1,000 倍以上,而且成本更低。
它们不仅更好地满足了我们的用例,而且更可预测、更可靠,当然,可定制性也更高。
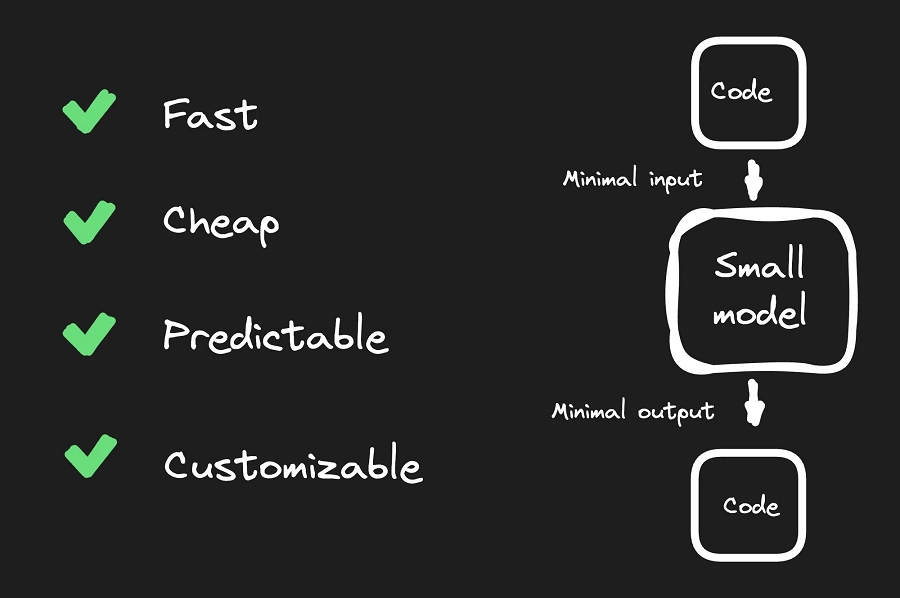
那么,让我们来分析一下如何像我们一样训练自己的专用 AI 模型。
2、分解问题
首先,你需要将问题分解成更小的部分。在我们的案例中,我们希望采用任何 Figma 设计并将其自动转换为高质量代码。
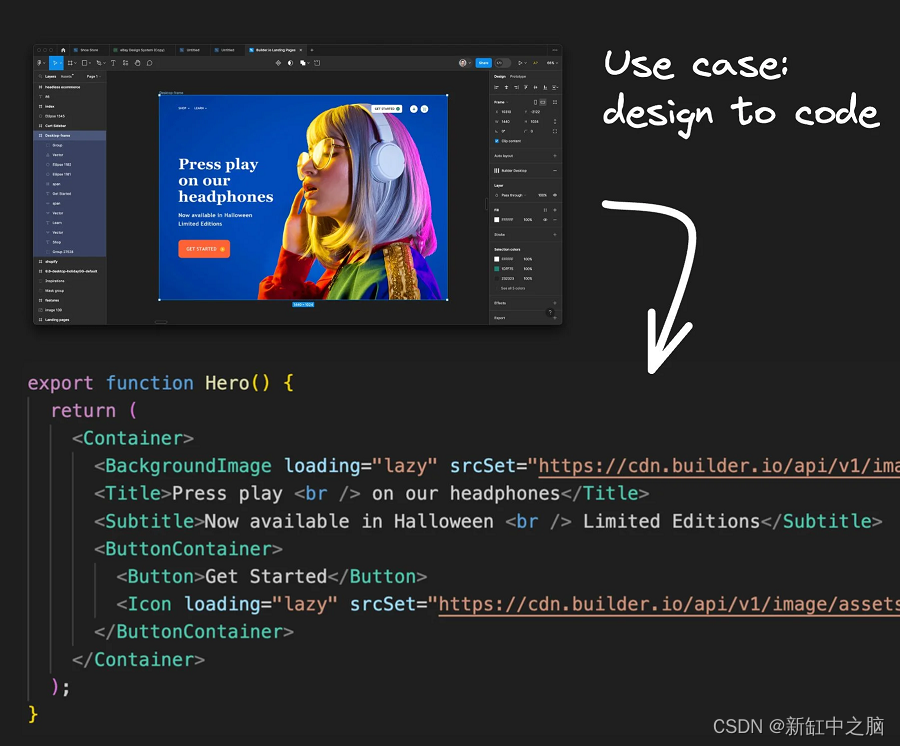
为了解决这个问题,我们首先探索了各种选择。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









