







1、背景描述
这是一个“简单的”回归问题,为了锻炼自己的炼丹能力,我把函数关系搞得特别复杂:
x_raw = torch.rand((1000, 10)) * 2
y_raw = torch.cat((x_raw[:, [0]] * x_raw[:, [1]],
-x_raw[:, [2]] * x_raw[:, [3]],
x_raw[:, [9]] / x_raw[:, [8]] - x_raw[:, [7]],
-x_raw[:, [6]].abs() ** 0.5 + x_raw[:, [5]] + 2,
-x_raw[:, [4]] / x_raw[:, [0]]), dim=1).sum(dim=1, keepdim=True)
你看这是一个十变量函数
y
=
x
0
x
1
−
x
2
x
3
+
x
9
x
8
−
x
7
−
∣
x
6
∣
+
x
5
+
2
−
x
4
x
0
y=x_0x_1-x_2x_3+\frac{x_9}{x_8}-x_7-\sqrt{|x_6|}+x_5+2-\frac{x_4}{x_0}
y=x0x1−x2x3+x8x9−x7−∣x6∣+x5+2−x0x4
按理来说神经网络能够拟合任意函数,只要网络够深,参数够多。但偏偏我昨天训练的时候就发生了过拟合!
网络结构是四层MLP,毕竟这种回归问题应该用不到什么fancy的layer。
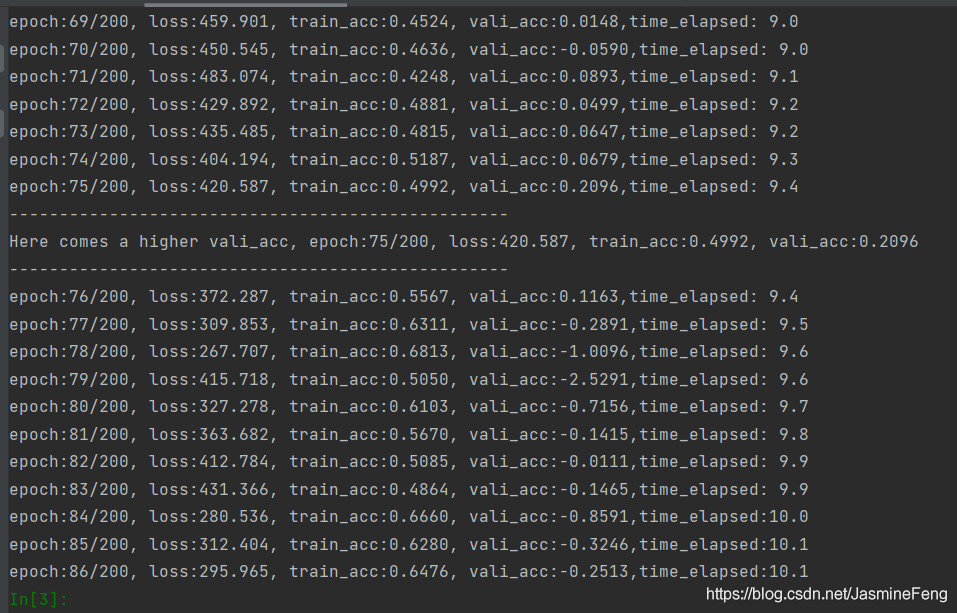
这边train_acc和vali_acc都是
A
d
j
u
s
t
e
d
R
2
\mathrm{Adjusted}\ R^2
Adjusted R2,可以看到vali_acc甚至出现了负值,而train_acc比vali_acc高得多
过拟合咋办呢,常见的方法我都试了,权重衰减、Dropout、BatchNorm、flooding、提前终止,但没什么用,比方说稍微改大一点权重衰减的系数,就出现了欠拟合!
2、原因探析
- 深入想想,为啥会过拟合?为啥权重衰减可以抑制过拟合?不正是因为权重太大了,要控制权重再一定范围内吗?一个过大的权重,会使得模型对输入变得十分敏感——输入稍微改动一下,可能输出就会有很大的波动。因此才会想到要权重衰减。
进一步,那为什么神经网络会学到很大的权重?我想可能是因为回归标签本来就很大吧,一个值为1000的标签,如果网络权重都很小,输入又做了标准化(归一化),那怎么可能预测出1000这么大的数呢,所以至少在网络最后一层权重会比较大,这样Loss也会比较大,进而导致梯度大,这又带来梯度爆炸的问题了。 - 另一方面,数据集可能不是很好,会出现一些outliers异常值,但网络并不知道那些是异常值啊,为了使预测接近异常值,预测出的曲线(单个特征)或曲面(两个特征)自己波动就很大,那就很容易过拟合了,也会表现出对输入的敏感性。
3、问题解决
考虑到上面两点,我们要对标签值进行一些预处理。我以前是只对样本特征预处理的,但是这次也要preprocess标签。
相应地,一方面,要控制标签整体的范围,不能太大,因此做标准化处理。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
y = torch.from_numpy(scaler.fit_transform(y_raw)).type(torch.float32)
P.S. 
另一方面,删除异常值,这里异常值的判断标准是与均值的距离超出1.96个标准差。
y_range = (y.mean() - 1.96 * y.std(), y.mean() + 1.96 * y.std())
y_normal_ind = ((y < y_range[1]) & (y > y_range[0])).flatten()
y = y[y_normal_ind]
x = x[y_normal_ind, :]
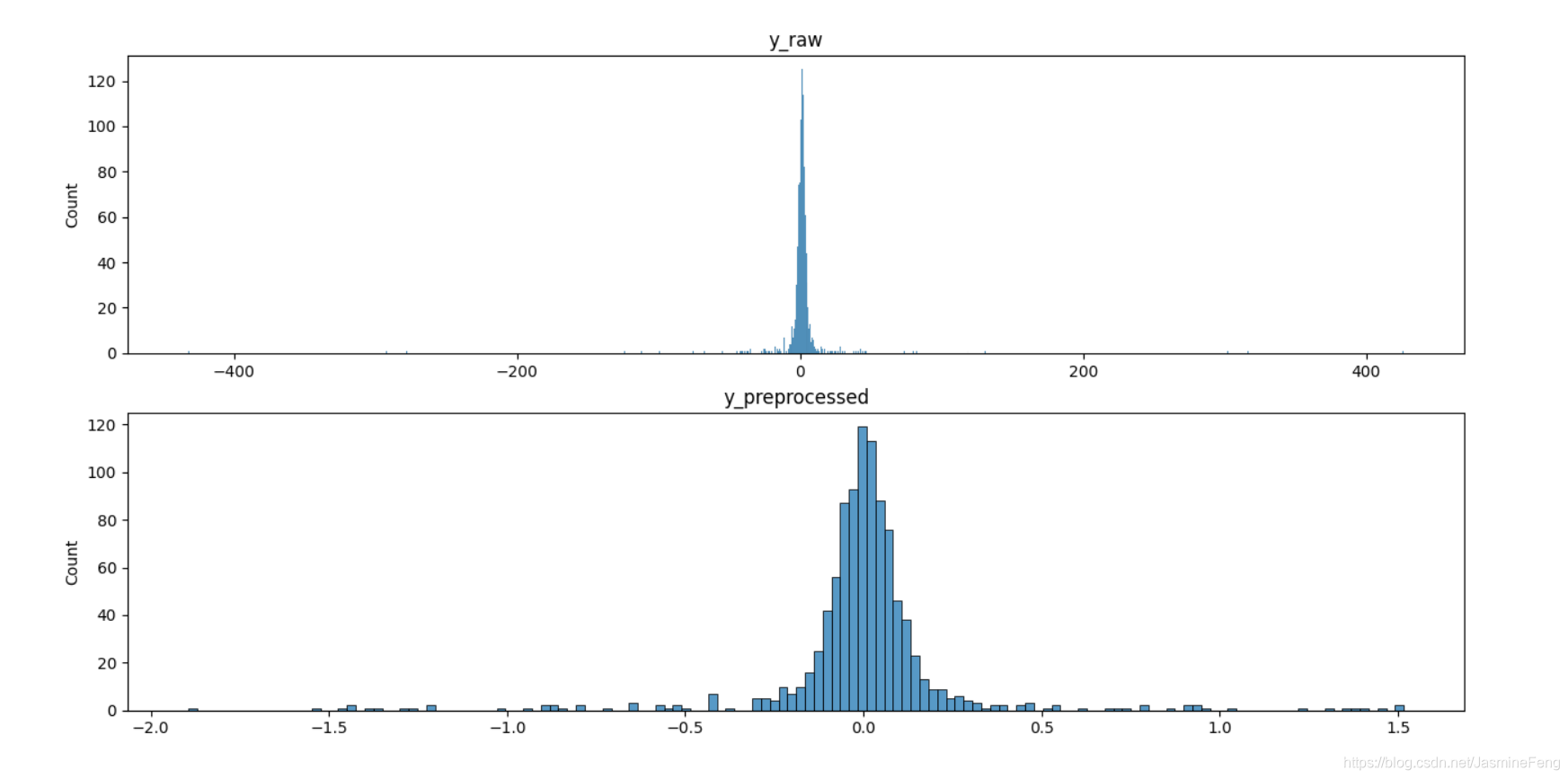
可以对比一下处理前后的标签值分布~
处理前,标签里有几个零星的绝对值为几百的数以及不少绝对值为十几的数,当然大部分数还是集中在2附近,处理过后之后范围大大缩小了。
4、改进效果
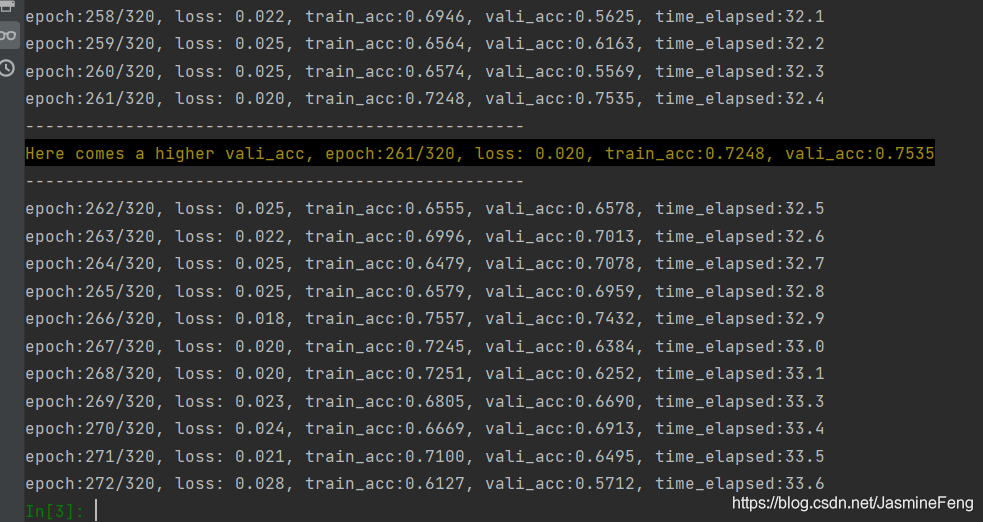
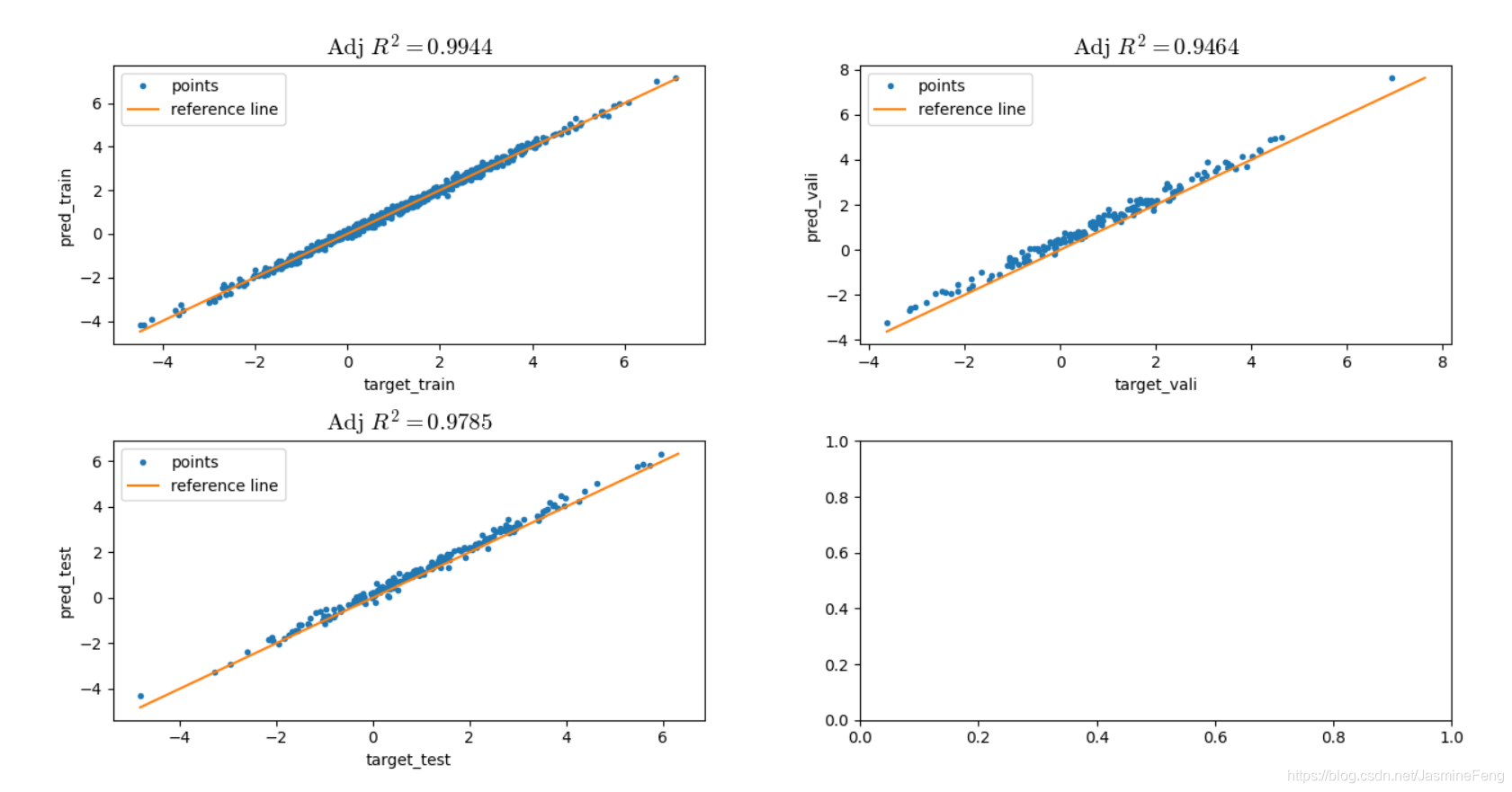
训练比之前稳定多了~
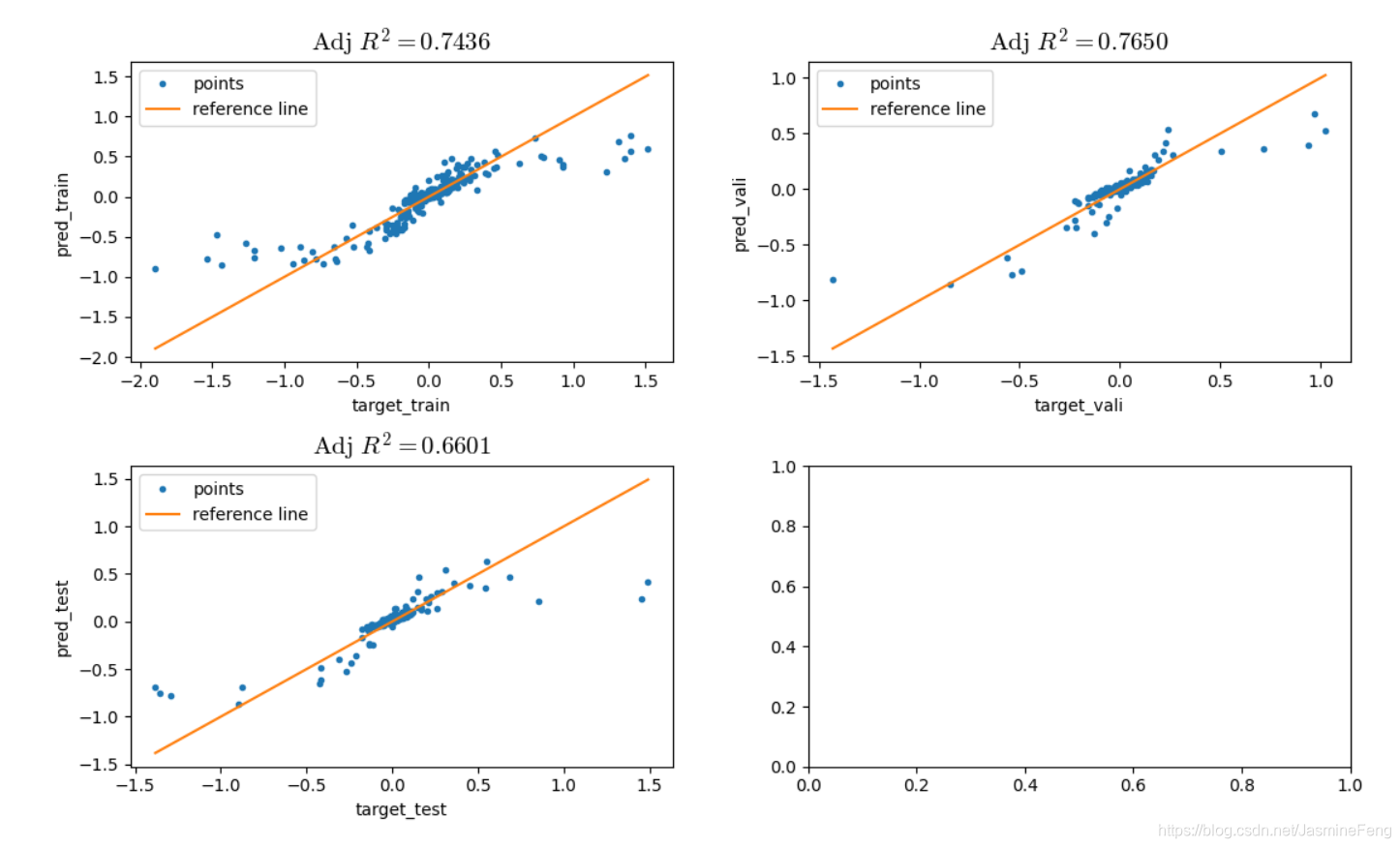
训练集、验证集、测试集上预测效果都还不错。
5、数据标签真的很丑!
后来我进一步分析,为什么数据标签会这么丑呢?这肯定跟函数关系式有关,我的关系式中有两个分式,而所有的变量服从(-2,2)的均匀分布,难保分母不会有一个很接近于0的值,进而导致该项很大很大,从而使得标签在某个点的值突然上升或突然下降。
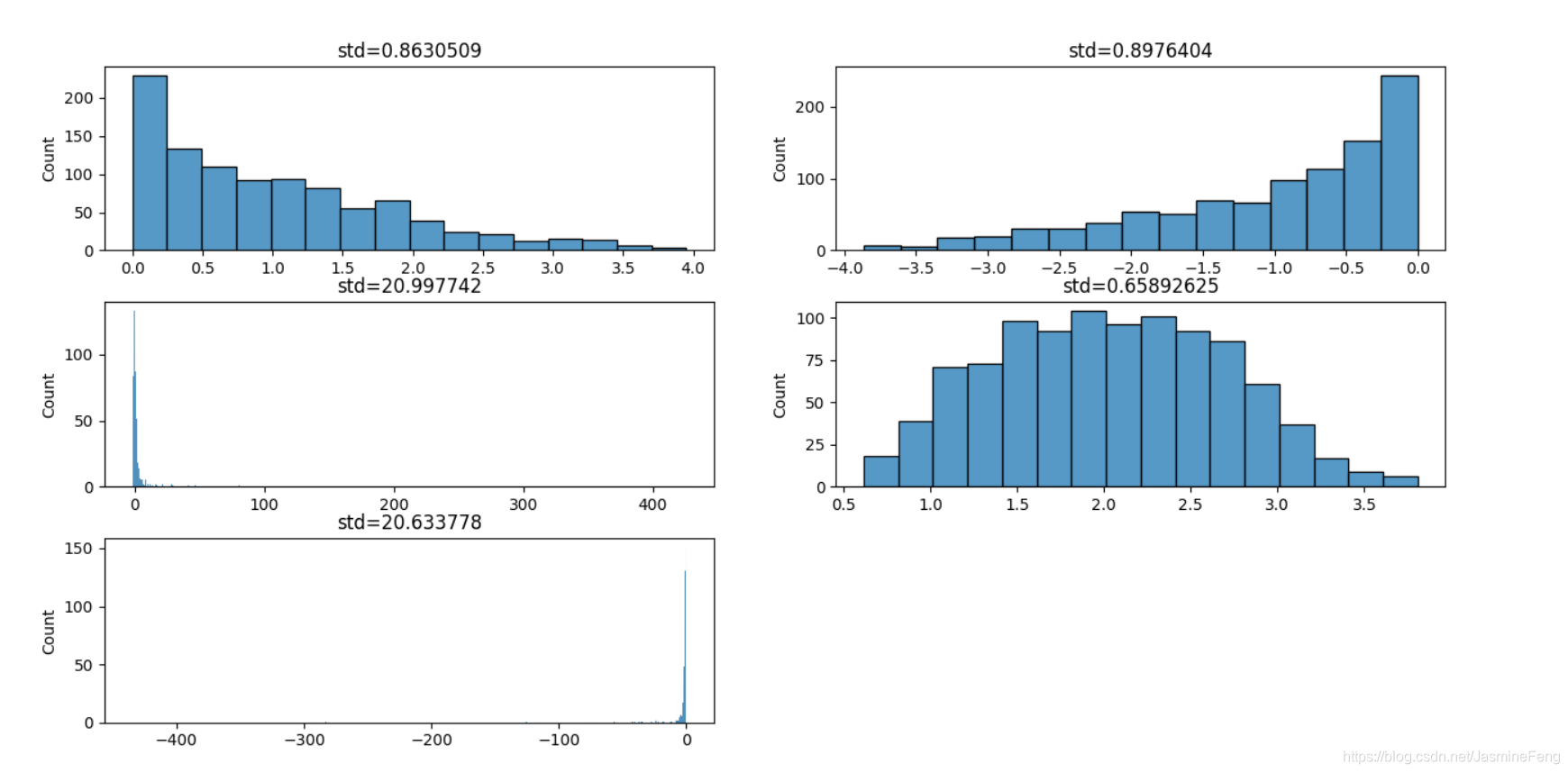
上图中,(1,1),(1,2),(2,1),(2,2),(3,1)分别是函数第1、2、3、4、5项,可以看到,分式项分布范围很广,甚至可以达到三四百这么大的值,神经网络学习有多么困难,可想而知。
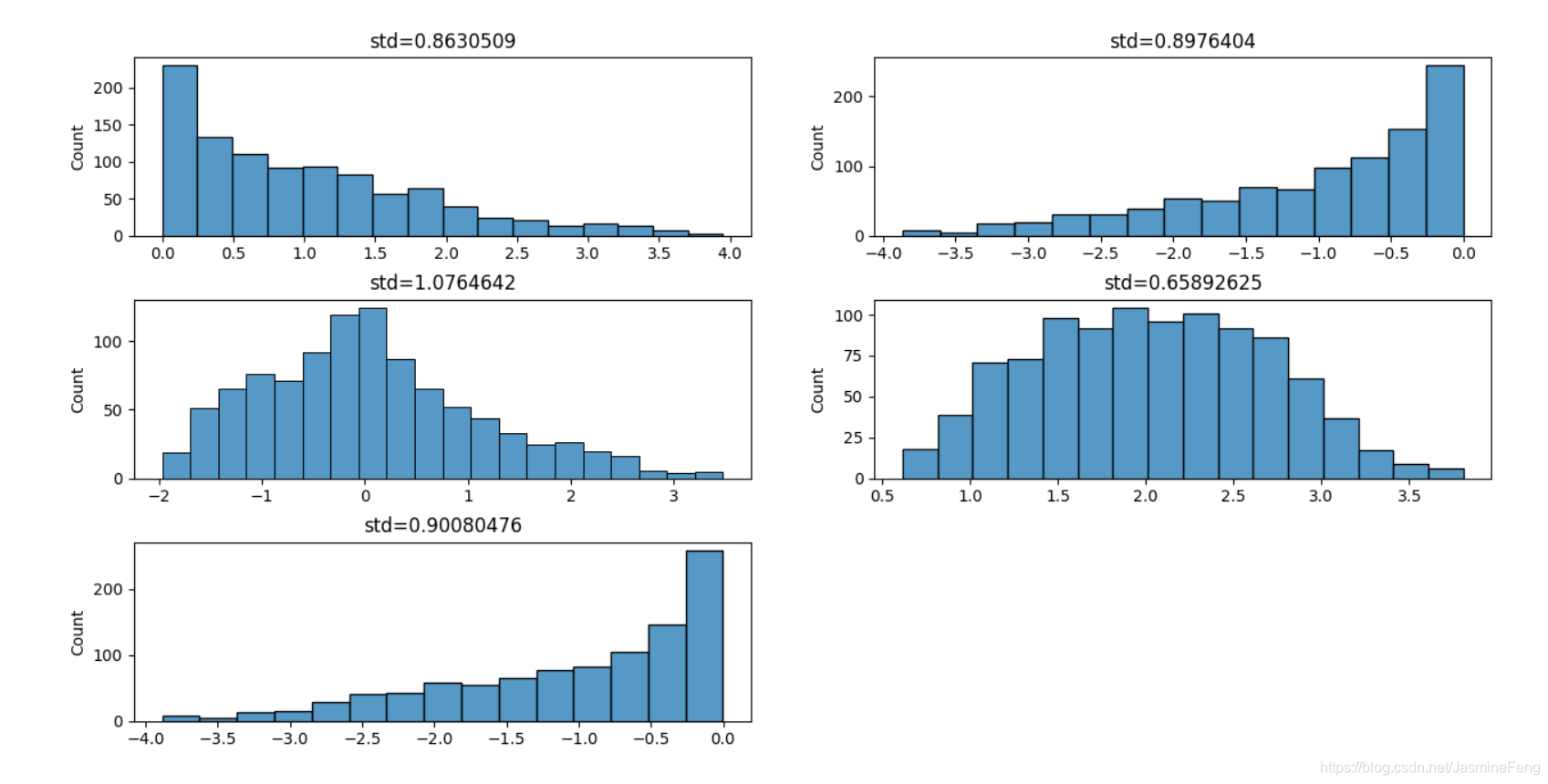
我把除法运算都改成了乘法运算后,分布都在差不多的较小范围里了。
再次训练网络,调整R2达到了0.99以上!!!啊啊啊!
好家伙,不愧是我!














 6453
6453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









