










咱们今天和大家聊聊在机器学习和深度学习领域,随机森林(Random Forest)和长短期记忆网络(LSTM)各自在处理数据时具有独特的优势。
那么,将两者结合可以发挥它们各自的优点,从而提升模型的性能~
随机森林和LSTM和时间序列预测学习下方图片获取
结合后的优势:
-
提高泛化能力:随机森林能够通过集成多个决策树来提高泛化能力,减少过拟合。而LSTM擅长处理时间序列数据,通过在时间维度上捕捉长期依赖关系。将两者结合,可以利用随机森林的集成优势和LSTM的序列建模能力。
-
处理复杂的时序数据:LSTM在时序数据中的表现非常优秀,但它可能会受到梯度消失和爆炸的影响。结合随机森林后,随机森林可以对输入特征进行预处理或特征选择,从而降低LSTM模型的复杂度,减少训练时间。
-
增强鲁棒性:随机森林作为一种集成学习方法,天然具有较强的鲁棒性,能够对输入数据的噪声具有较强的容忍度。结合LSTM后,LSTM可以处理序列中的时间依赖,而随机森林能帮助解决输入特征的噪声和不稳定性问题。
-
特征选择与降维:随机森林通过计算特征的重要性来帮助选择最有效的特征,结合LSTM时,能够减少冗余特征,降低模型的复杂度和计算成本。
随机森林和LSTM的原理
随机森林(Random Forest)
随机森林是一种集成学习方法,主要通过构建多棵决策树来进行预测。每棵决策树都是通过自助采样法(Bootstrap)从原始训练数据中随机采样得到的。每棵树在训练时都会选择一个特征子集,通过这个特征子集来进行节点分裂,从而构建多棵树。
-
训练过程:在训练过程中,随机森林首先通过Bootstrap采样从训练数据中选择多个子样本集。然后,对于每一个子样本集,训练一棵决策树。在构建每棵树时,会随机选择特征子集来决定节点分裂,这样不同的树可以有不同的决策标准,避免了过拟合。
-
预测过程:在预测时,所有的树对输入数据进行预测,最终的预测结果通过投票或平均来决定(对于分类问题是投票,回归问题是平均)。
随机森林的一个重要优势是其抗过拟合能力,通过多次训练和集成多棵树来提高模型的泛化能力。
LSTM(长短期记忆网络)
LSTM是循环神经网络(RNN)的一种特殊形式,用于处理和预测时间序列数据。LSTM通过引入门控机制,有效地解决了标准RNN中的梯度消失和爆炸问题。LSTM的结构包含三个主要的门:
-
遗忘门(Forget Gate):决定遗忘多少之前的记忆。
-
输入门(Input Gate):决定当前时刻的新信息有多少被添加到记忆单元中。
-
输出门(Output Gate):决定从记忆单元中输出多少信息。
LSTM的基本单元由一个记忆细胞(cell state)和几个门控组成,通过这些机制来控制信息的流动。
LSTM 公式
LSTM网络中的每个单元可以通过以下公式描述:
 这些公式和门控机制使得LSTM能够在长期依赖性问题中取得优异的表现。
这些公式和门控机制使得LSTM能够在长期依赖性问题中取得优异的表现。
随机森林与LSTM结合的模型
将随机森林与LSTM结合的方式:
-
数据预处理阶段:可以使用随机森林对输入的特征进行选择和处理,减少数据噪声,使得LSTM模型能够在更简洁的数据上进行训练。具体的做法是,使用随机森林训练一个模型,并通过它来筛选出最重要的特征,然后将这些特征作为LSTM的输入。
-
输出集成:一种更高级的结合方式是,将LSTM模型的输出作为输入特征,使用随机森林进行进一步的预测。具体来说,可以先使用LSTM处理时间序列数据,生成隐藏状态或输出,再将这些输出作为特征传递给随机森林进行分类或回归预测。
-
混合模型:在此方法中,可以同时训练LSTM和随机森林,并将两者的结果进行融合。随机森林和LSTM的预测可以通过加权平均、投票等方法结合,提升整体的预测性能。
总的来说,随机森林和LSTM各自具有强大的能力。随机森林能够通过集成多棵决策树来提高模型的准确性并减少过拟合,而LSTM通过引入门控机制能够处理和学习时间序列数据中的长期依赖。
将两者结合后,能够在处理复杂的时序数据时提高模型的泛化能力和鲁棒性,并且通过特征选择、降维等方式简化训练过程。这种结合不仅适用于时间序列预测,也可以用于复杂数据的分类和回归任务。
完整案例
这里,咱们是一个包括模型训练、融合随机森林和LSTM的时间序列的案例~
-
目标:结合随机森林(Random Forest,RF)和长短时记忆网络(LSTM)的优势进行时间序列预测。
-
数据集:使用虚拟数据集,模拟时间序列数据进行模型训练。
-
输出要求:通过图形展示预测效果,包括预测曲线、真实值曲线、误差曲线等图形,并阐述每个图形的意义。每个图形要具有鲜艳的配色。
-
模型融合:结合随机森林和LSTM,发挥各自的优势,提高预测精度。
1. 数据集
我们首先创建一个虚拟的时间序列数据集,模拟一维的时序数据。
这个数据集可以是任意的,但为了说明问题,我们使用正弦波叠加噪声生成数据。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
# 设置随机种子,确保实验可复现
np.random.seed(42)
# 生成时间序列数据
defgenerate_synthetic_data():
# 生成正弦波数据
time = np.linspace(0, 100, 1000)
series = np.sin(time) + 0.5 * np.random.randn(1000) # 正弦波加上噪声
return pd.DataFrame({'time': time, 'value': series})
data = generate_synthetic_data()
# 展示数据
plt.figure(figsize=(12, 6))
plt.plot(data['time'], data['value'], label='Original Time Series', color='orange')
plt.title('Generated Synthetic Time Series Data')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.grid(True)
plt.show()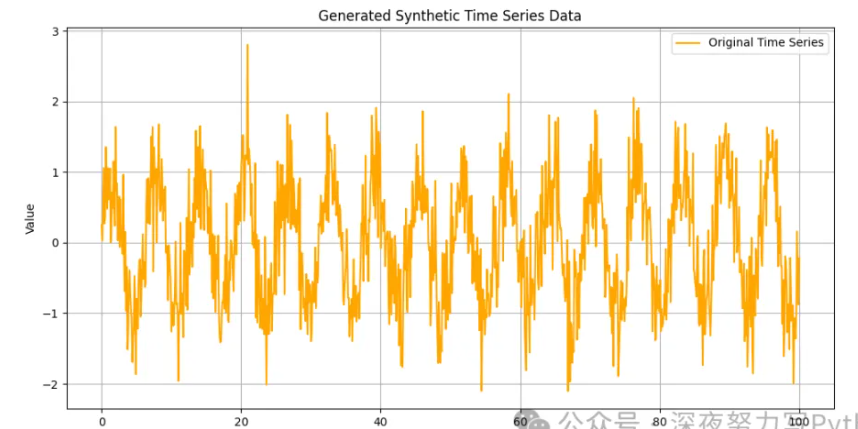
2. 实现LSTM模型
LSTM模型是基于时间序列的深度学习模型,适合捕捉时间依赖性。
import torch
import torch.nn as nn
from sklearn.preprocessing import MinMaxScaler
# 数据归一化
scaler = MinMaxScaler(feature_range=(-1, 1))
data_scaled = scaler.fit_transform(data['value'].values.reshape(-1, 1))
# 创建时间序列数据集
defcreate_dataset(data, time_step=10):
X, y = [], []
for i in range(len(data) - time_step - 1):
X.append(data[i:(i + time_step), 0])
y.append(data[i + time_step, 0])
return np.array(X), np.array(y)
time_step = 10
X, y = create_dataset(data_scaled, time_step)
# 转换为pytorch tensor
X = torch.from_numpy(X).float()
y = torch.from_numpy(y).float()
# 划分训练集和测试集
train_size = int(len(X) * 0.8)
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
# LSTM模型
classLSTMModel(nn.Module):
def__init__(self, input_size=1, hidden_layer_size=50, output_size=1):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_layer_size, batch_first=True)
self.linear = nn.Linear(hidden_layer_size, output_size)
defforward(self, x):
out, _ = self.lstm(x)
out = self.linear(out[:, -1, :]) # 取最后一个时间步的输出
return out
# 初始化模型
model_lstm = LSTMModel()
# 训练模型
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model_lstm.parameters(), lr=0.001)
epochs = 100
for epoch in range(epochs):
model_lstm.train()
optimizer.zero_grad()
outputs = model_lstm(X_train.unsqueeze(-1)) # 增加维度
loss = criterion(outputs, y_train.unsqueeze(-1))
loss.backward()
optimizer.step()
if epoch % 10 == 0:
print(f'Epoch [{epoch}/{epochs}], Loss: {loss.item():.4f}')3. 实现随机森林模型
随机森林是基于决策树的集成学习算法,可以处理非线性问题。
我们使用sklearn的随机森林模型进行训练。
from sklearn.ensemble import RandomForestRegressor
# 用训练集训练随机森林模型
model_rf = RandomForestRegressor(n_estimators=100, random_state=42)
model_rf.fit(X_train.numpy(), y_train.numpy())
# 预测
y_pred_rf = model_rf.predict(X_test.numpy())4. 模型融合
模型融合的目的是结合LSTM和随机森林模型的预测结果,得到更稳健的预测。
# LSTM模型预测
model_lstm.eval()
y_pred_lstm = model_lstm(X_test.unsqueeze(-1)).detach().numpy()
# 融合LSTM和随机森林的预测结果
y_pred_fused = (y_pred_lstm.flatten() + y_pred_rf) / 25. 可视化结果
我们使用Matplotlib绘制四个图表来展示模型的效果。
plt.figure(figsize=(14, 10))
# 真实值与LSTM预测值
plt.subplot(2, 2, 1)
plt.plot(y_test.numpy(), label='Actual', color='orange')
plt.plot(y_pred_lstm, label='LSTM Prediction', color='blue')
plt.title('LSTM Model: Actual vs Predicted')
plt.legend()
# 真实值与随机森林预测值
plt.subplot(2, 2, 2)
plt.plot(y_test.numpy(), label='Actual', color='orange')
plt.plot(y_pred_rf, label='Random Forest Prediction', color='green')
plt.title('Random Forest Model: Actual vs Predicted')
plt.legend()
# 真实值与融合后的预测值
plt.subplot(2, 2, 3)
plt.plot(y_test.numpy(), label='Actual', color='orange')
plt.plot(y_pred_fused, label='Fused Prediction', color='red')
plt.title('Fused Model: Actual vs Predicted')
plt.legend()
# 预测误差
plt.subplot(2, 2, 4)
plt.plot(y_test.numpy() - y_pred_fused, label='Prediction Error', color='purple')
plt.title('Prediction Error')
plt.legend()
plt.tight_layout()
plt.show()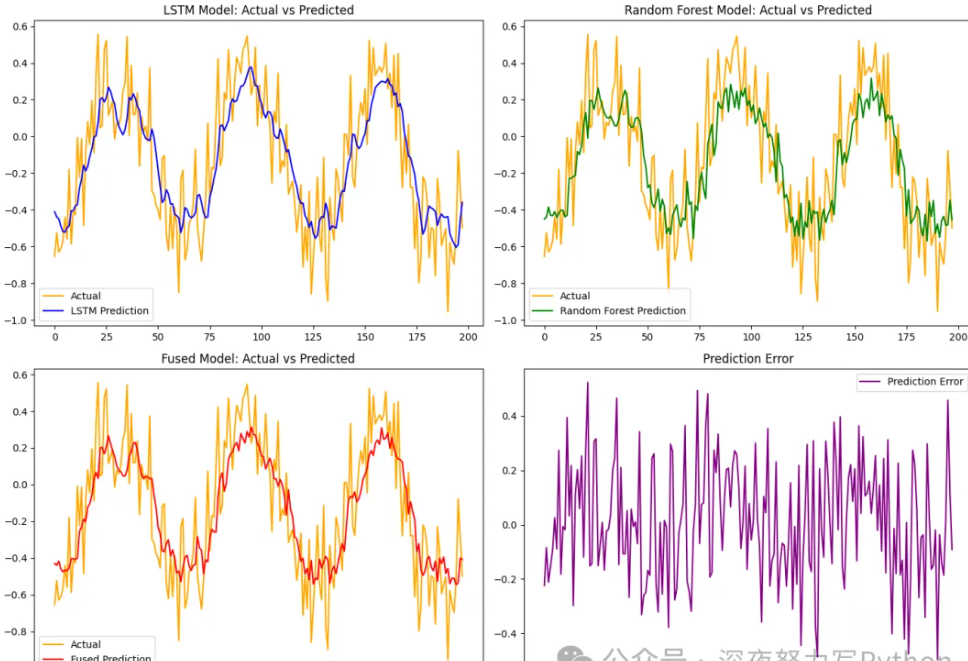
2 个优化点,大家可以参考~
-
模型超参数调优:
-
LSTM模型:可以调整
hidden_layer_size、learning_rate、batch_size等超参数。 -
随机森林:可以调整
n_estimators、max_depth、min_samples_split等超参数。
-
-
融合方法改进:目前采用简单的平均融合,可以尝试其他加权融合方法,基于模型的预测性能赋予不同的权重。
调参流程:
-
使用网格搜索(GridSearchCV)或随机搜索(RandomizedSearchCV)来寻找最优的超参数。
-
根据交叉验证的结果调整学习率、隐藏层大小、树的数量等。
-
采用早期停止(Early Stopping)策略来避免过拟合。
总的来看,使用LSTM和随机森林模型进行时间序列预测,且通过模型融合提升了预测精度。
有以下论文写作问题的可以下方加老师详聊
前沿顶会、期刊论文、综述文献浩如烟海,不知道学习路径,无从下手?
没时间读、不敢读、不愿读、读得少、读不懂、读不下去、读不透彻一篇完整的论文?
CVPR、ICCV、ECCV、ICLR、NeurlPS、AAAI……想发表顶会论文,找不到创新点?
读完论文,仍旧无法用代码复现……
然而,导师时常无法抽出时间指导,想写论文却无人指点……

















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









