









 该文章介绍了一种利用GPT3.5的向量接口和Qdrant向量数据库构建本地知识库的方法,旨在实现智能回复并限制ChatGPT的使用范围,从而节省调用成本。通过将文本数据转化为向量并存储在Qdrant中,然后使用Flask应用处理查询,结合OpenAI的ChatCompletionAPI生成回答。
该文章介绍了一种利用GPT3.5的向量接口和Qdrant向量数据库构建本地知识库的方法,旨在实现智能回复并限制ChatGPT的使用范围,从而节省调用成本。通过将文本数据转化为向量并存储在Qdrant中,然后使用Flask应用处理查询,结合OpenAI的ChatCompletionAPI生成回答。
原文:基于GPT3.5实现本地知识库解决方案-利用向量数据库和GPT向量接口-实现智能回复并限制ChatGPT回答的范围 - 腾讯云开发者社区-腾讯云
标题有点长,但是基本也说明出了这篇文章的主旨,那就是利用GPT AI智能回答自己设置好的问题
既能实现自己的AI知识库机器人,又能节省ChatGPT调用的token成本费用。
代码仓库地址
document.ai: 基于GPT3.5的通用本地知识库解决方案
下面图片是整个流程:
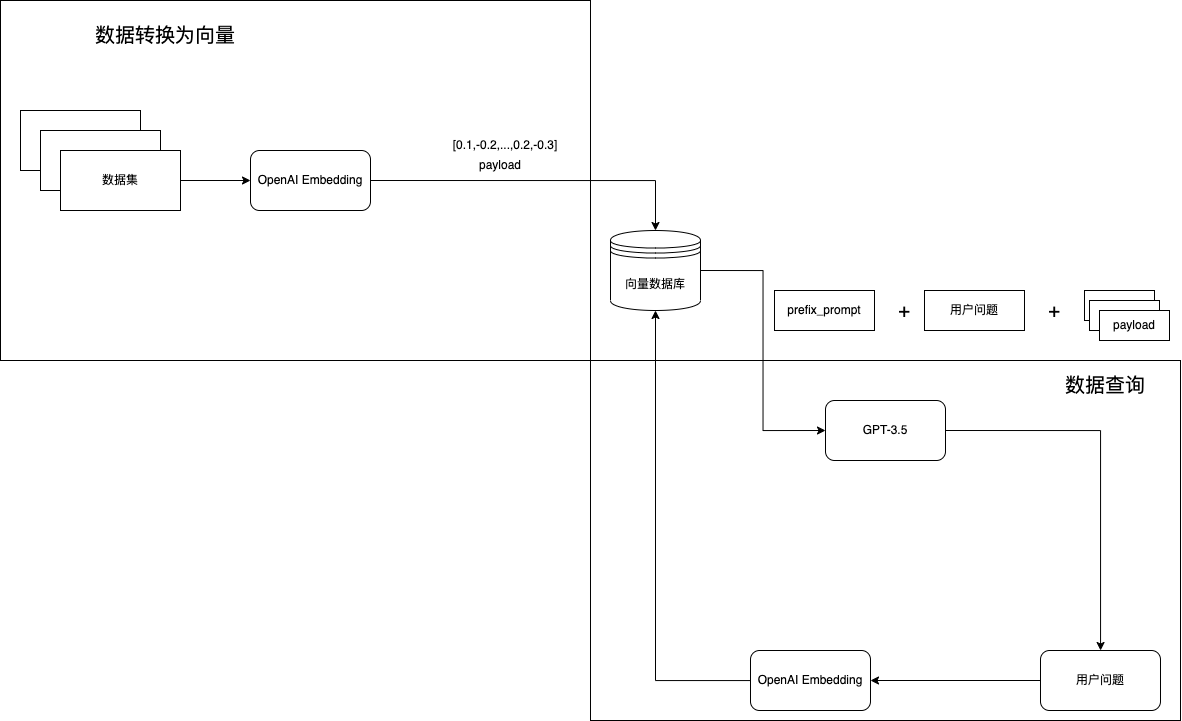
导入知识库数据
利用openai的向量接口生成向量数据,然后导入到向量数据库qdrant
这段代码会将指定目录下的所有文件读取出来,然后将文件中的文本内容进行分割,分割后的结果会被传入到
to_embeddings函数中,该函数会使用 OpenAI 的 API 将文本内容转换为向量。最后,将向量和文件名、文件内容一起作为一个文档插入到 Qdrant 数据库中。
具体来说,这段代码会遍历 ./source_data目录下的所有文件,对于每个文件,它会读取文件内容,然后将文件内容按照 #####进行分割
分割后的结果会被传入到 to_embeddings函数中。
to_embeddings函数会使用 OpenAI 的 API 将文本内容转换为向量,最后返回一个包含文件名、文件内容和向量的列表。
接下来,将向量和文件名、文件内容一起作为一个文档插入到 Qdrant 数据库中。
其中,count变量用于记录插入的文档数量,client.upsert函数用于将文档插入到 Qdrant 数据库中。
需要在目录里创建.env文件,里面放OPENAI_API_KEY
OPENAI_API_KEY=sk-Zxxxxxxxxddddddddd
from qdrant_client import QdrantClient
from qdrant_client.http.models import Distance, VectorParams
from qdrant_client.http.models import PointStruct
from dotenv import load_dotenv
import os
import tqdm
import openai
def to_embeddings(items):
sentence_embeddings = openai.Embedding.create(
model="text-embedding-ada-002",
input=items[1]
)
return [items[0], items[1], sentence_embeddings["data"][0]["embedding"]]
if __name__ == '__main__':
client = QdrantClient("127.0.0.1", port=6333)
collection_name = "data_collection"
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
# 创建collection
client.recreate_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=1536, distance=Distance.COSINE),
)
count = 0
for root, dirs, files in os.walk("./source_data"):
for file in tqdm.tqdm(files):
file_path = os.path.join(root, file)
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
parts = text.split('#####')
item = to_embeddings(parts)
client.upsert(
collection_name=collection_name,
wait=True,
points=[
PointStruct(id=count, vector=item[2], payload={"title": item[0], "text": item[1]}),
],
)
count += 1复制
查询知识库数据
这是一个基于flask的web应用,主要功能是根据用户输入的问题,从Qdrant中搜索相关的文本,然后使用openai的ChatCompletion API进行对话生成,最后将生成的回答返回给用户。
from flask import Flask
from flask import render_template
from flask import request
from dotenv import load_dotenv
from qdrant_client import QdrantClient
import openai
import os
app = Flask(__name__)
def prompt(question, answers):
"""
生成对话的示例提示语句,格式如下:
demo_q:
使用以下段落来回答问题,如果段落内容不相关就返回未查到相关信息:"成人头疼,流鼻涕是感冒还是过敏?"
1. 普通感冒:您会出现喉咙发痒或喉咙痛,流鼻涕,流清澈的稀鼻涕(液体),有时轻度发热。
2. 常年过敏:症状包括鼻塞或流鼻涕,鼻、口或喉咙发痒,眼睛流泪、发红、发痒、肿胀,打喷嚏。
demo_a:
成人出现头痛和流鼻涕的症状,可能是由于普通感冒或常年过敏引起的。如果病人出现咽喉痛和咳嗽,感冒的可能性比较大;而如果出现口、喉咙发痒、眼睛肿胀等症状,常年过敏的可能性比较大。
system:
你是一个医院问诊机器人
"""
demo_q = '使用以下段落来回答问题:"成人头疼,流鼻涕是感冒还是过敏?"\n1. 普通感冒:您会出现喉咙发痒或喉咙痛,流鼻涕,流清澈的稀鼻涕(液体),有时轻度发热。\n2. 常年过敏:症状包括鼻塞或流鼻涕,鼻、口或喉咙发痒,眼睛流泪、发红、发痒、肿胀,打喷嚏。'
demo_a = '成人出现头痛和流鼻涕的症状,可能是由于普通感冒或常年过敏引起的。如果病人出现咽喉痛和咳嗽,感冒的可能性比较大;而如果出现口、喉咙发痒、眼睛肿胀等症状,常年过敏的可能性比较大。'
system = '你是一个医院问诊机器人'
q = '使用以下段落来回答问题,如果段落内容不相关就返回未查到相关信息:"'
q += question + '"'
# 带有索引的格式
for index, answer in enumerate(answers):
q += str(index + 1) + '. ' + str(answer['title']) + ': ' + str(answer['text']) + '\n'
"""
system:代表的是你要让GPT生成内容的方向,在这个案例中我要让GPT生成的内容是医院问诊机器人的回答,所以我把system设置为医院问诊机器人
前面的user和assistant是我自己定义的,代表的是用户和医院问诊机器人的示例对话,主要规范输入和输出格式
下面的user代表的是实际的提问
"""
res = [
{'role': 'system', 'content': system},
{'role': 'user', 'content': demo_q},
{'role': 'assistant', 'content': demo_a},
{'role': 'user', 'content': q},
]
return res
def query(text):
"""
执行逻辑:
首先使用openai的Embedding API将输入的文本转换为向量
然后使用Qdrant的search API进行搜索,搜索结果中包含了向量和payload
payload中包含了title和text,title是疾病的标题,text是摘要
最后使用openai的ChatCompletion API进行对话生成
"""
client = QdrantClient("127.0.0.1", port=6333)
collection_name = "data_collection"
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
sentence_embeddings = openai.Embedding.create(
model="text-embedding-ada-002",
input=text
)
"""
因为提示词的长度有限,所以我只取了搜索结果的前三个,如果想要更多的搜索结果,可以把limit设置为更大的值
"""
search_result = client.search(
collection_name=collection_name,
query_vector=sentence_embeddings["data"][0]["embedding"],
limit=3,
search_params={"exact": False, "hnsw_ef": 128}
)
answers = []
tags = []
"""
因为提示词的长度有限,每个匹配的相关摘要我在这里只取了前300个字符,如果想要更多的相关摘要,可以把这里的300改为更大的值
"""
for result in search_result:
if len(result.payload["text"]) > 300:
summary = result.payload["text"][:300]
else:
summary = result.payload["text"]
answers.append({"title": result.payload["title"], "text": summary})
completion = openai.ChatCompletion.create(
temperature=0.7,
model="gpt-3.5-turbo",
messages=prompt(text, answers),
)
return {
"answer": completion.choices[0].message.content,
"tags": tags,
}
@app.route('/')
def hello_world():
return render_template('index.html')
@app.route('/search', methods=['POST'])
def search():
data = request.get_json()
search = data['search']
res = query(search)
return {
"code": 200,
"data": {
"search": search,
"answer": res["answer"],
"tags": res["tags"],
},
}
if __name__ == '__main__':
app.run(host='0.0.0.0', port=3000)复制
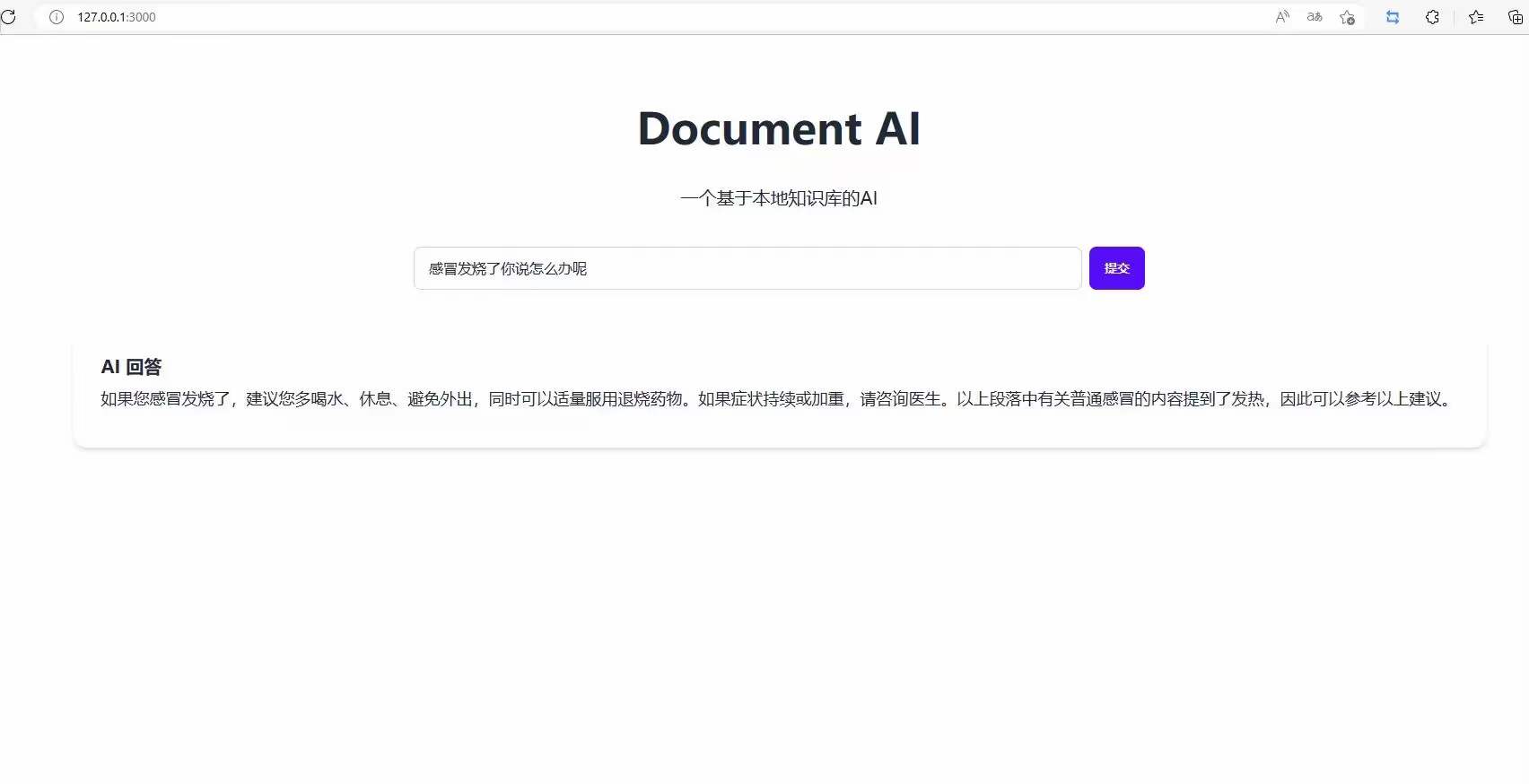
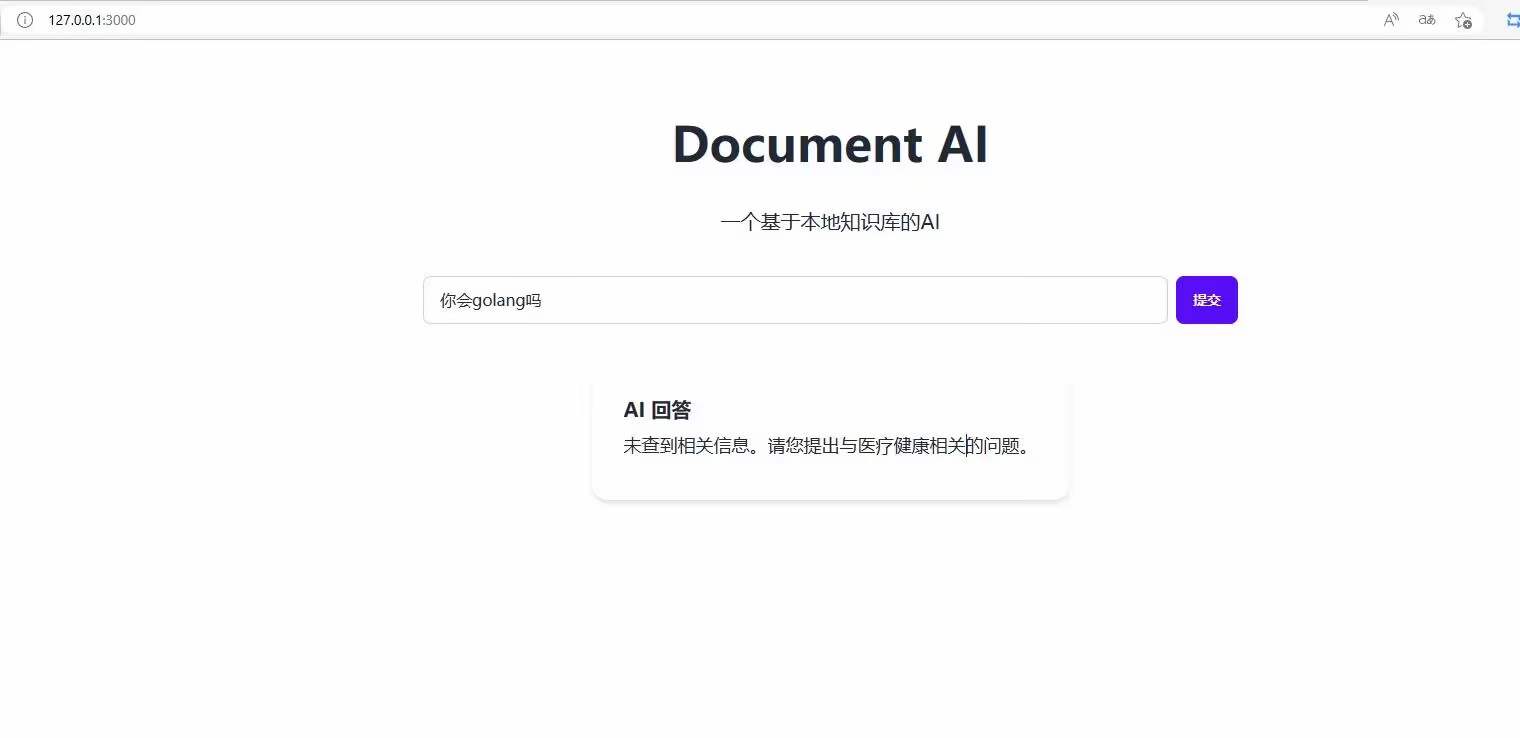
原文地址:基于GPT3.5实现本地知识库解决方案-利用向量数据库和GPT向量接口-实现智能回复并限制ChatGPT回答的范围-唯一在线客服系统-私有云独立部署在线客服系统源码-网站客服系统


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









