






升级vllm版本
vllm版本>= 0.7.1
在正常vllm serve 推理命令后增加 --enable-reasoning --reasoning-parser deepseek_r1
例如:
vllm serve /path/to/model --gpu-memory-utilization 0.95 --max-model-len 40000 --served-model-name "DeepSeek-R1-14B" --kv-cache-dtype="fp8_e4m3" --calculate-kv-scales --port 30001 --enable-reasoning --reasoning-parser deepseek_r1kv cache量化
这里我为了增加模型上下文,启用了kv cache fp8量化,因为推理模型输出非常多,上下文自然是多多益善
效果验证
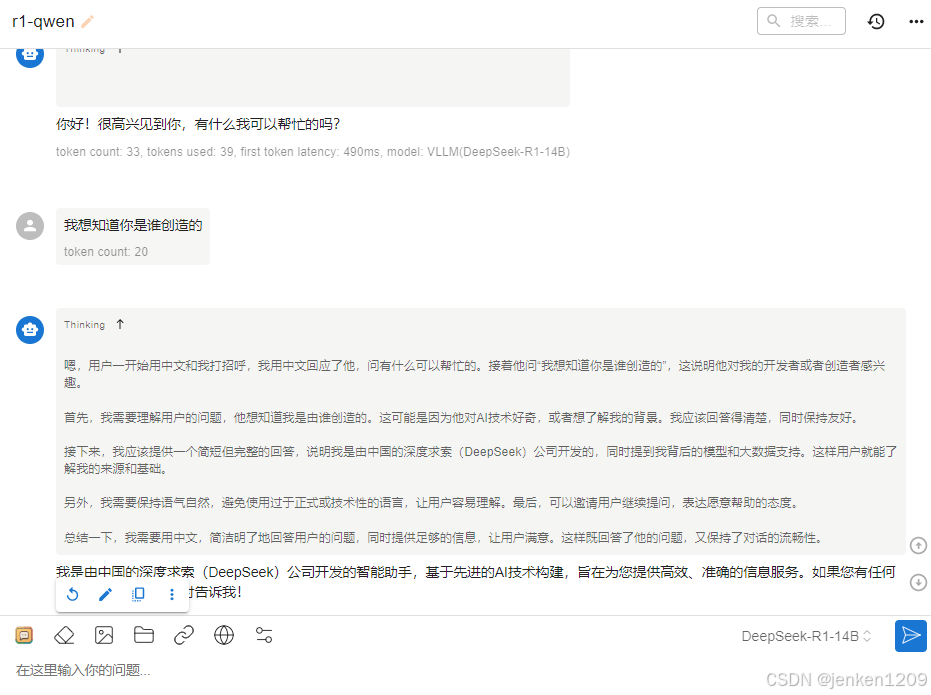
客户端侧,目前知道chatbox等接受reasoning_context参数。用1.9.8版本的chatbox对接vllm的接口,可以发现已经有思维链展示,而不是将思维链放在<think> </think>之间了

















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









