






引言
在魔搭社区,我们可以通过低代码或无代码的方式快速搭建并部署机器学习模型。这篇文章将详细介绍如何通过 Python 构建一个完整的机器学习工作流,包括数据加载、可视化、模型训练、预测和评估等步骤。
一、加载数据并初步探索
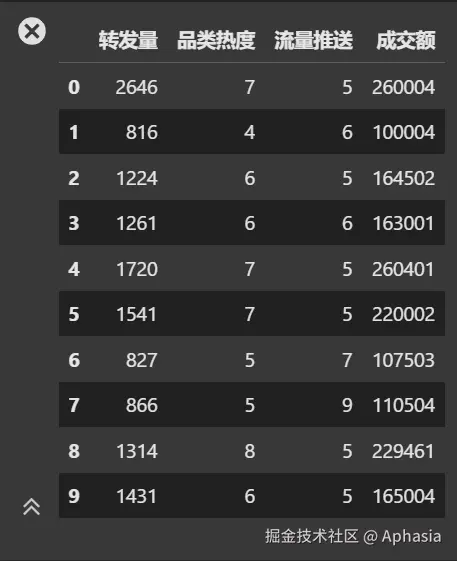
机器学习的第一步是加载数据并了解其基本结构。这可以帮助我们快速识别数据中的特征和潜在问题。导入一个csv文件到虚拟机上,这里我们使用 Pandas 读取数据,并查看前几行内容。
代码示例:
ini 代码解读复制代码# python 模块引入
# python 最流行的数据分析库
import pandas as pd
# js 异步的 IO 操作
# python 同步
df_ads = pd.read_csv("直播带货.csv")
# 数据样本的尺寸
# print(df_ads.size)
# 不传参数默认返回五条
df_ads.head(10)
目的:
- 了解数据结构,包括列名、数据类型和样本大小。
- 确定目标值(成交额)和特征(如转发量)。
二、数据可视化:直观理解数据
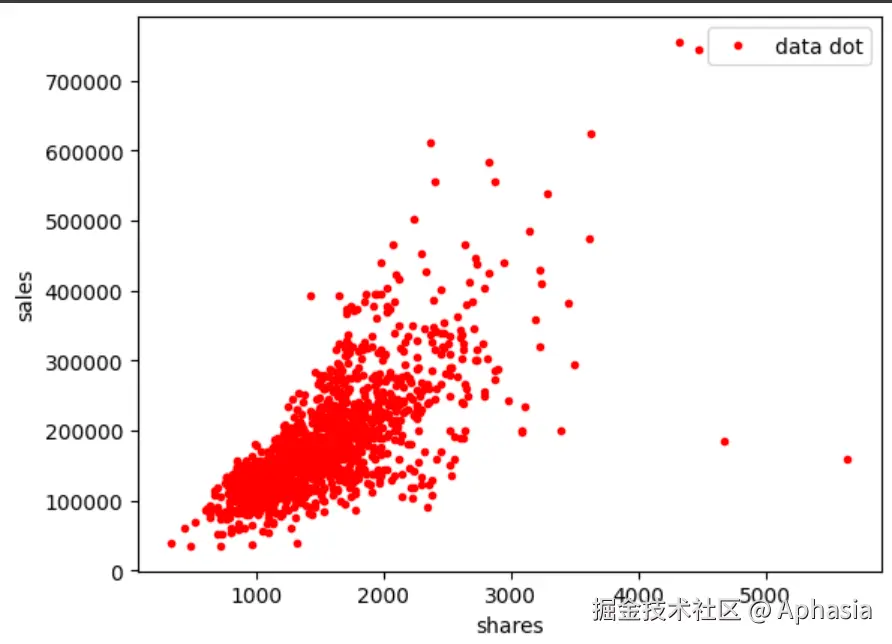
通过数据可视化,我们可以更清晰地观察特征之间的关系。例如,分析“转发量”和“成交额”的相关性。
代码示例:
dart 代码解读复制代码import matplotlib.pyplot as plt
plt.plot(df_ads['转发量'], df_ads['成交额'], 'r.', label='data dot')
plt.xlabel('shares')
plt.ylabel('sales')
plt.legend()
plt.show()
目的:
- 观察特征间是否存在线性关系,为选择模型提供参考。
三、数据清洗与预处理
分离特征和目标值
ini 代码解读复制代码# 移除成交额这一列
# 影响成交额的影响因子拿出来 训练
X = df_ads.drop(["成交额"], axis = 1)
# X
# 成交额 特征
y = df_ads.成交额
print(X.head())
y.head()
 目的:
目的:
- 确保数据完整、格式正确,为模型训练做好准备。
四、划分训练集和测试集
为了验证模型的泛化能力,我们将数据分为训练集(80%)和测试集(20%)。
代码示例:
ini 代码解读复制代码# 数据训练
# 简单模型,线性回归
from sklearn.linear_model import LinearRegression
# 线性回归算法的模型实例
model = LinearRegression()
# 训练 测试
from sklearn.model_selection import train_test_split
# train_test_split 将数据分成 训练数据,测试部分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
X_train.size
X_test.size

目的:
- 训练集用于训练模型,测试集用于评估模型的性能。
五、构建模型并训练
我们选择线性回归模型,这是最简单的机器学习模型之一,用于预测成交额。
代码示例:
bash 代码解读复制代码# 训练 y= ax + b 趋势
model.fit(X_train, y_train)
 目的:
目的:
- 通过拟合训练集数据,构建预测模型。
拓展之线性回归
线性回归对已有数据进行建模,可以对未来数据进行预测。线性回归是所有机器学习技术的一个最好起点,很多复杂的机器学习技术以及当前大火的深度神经网络都或多或少基于线性回归。上述使用的是一元线性回归方程 y = ax + b。
六、预测与结果展示
训练完成后,我们使用测试集进行预测,并将真实值与预测值进行对比。
代码示例:
scss 代码解读复制代码# 拷贝测试集数据
df_ads_pred = X_test.copy()
df_ads_pred.head()
df_ads_pred['成交额真值'] = y_test
df_ads_pred['成交额预测值'] = y_pred
df_ads_pred
 目的:
目的:
- 检查模型对未知数据的预测能力。
七、模型评估
通过评价指标,量化模型的性能。常用指标包括模型评分(R²)和均方误差(MSE)。
代码示例:
bash 代码解读复制代码# 大模型自己打分
# 预期的结果数据 衡量模型的训练质量
y_pred = model.predict(X_test)
print("线性回归预测集评分", model.score(X_test, y_test))
print("线性回归训练集评分", model.score(X_train, y_train))
 目的:
目的:
- 确定模型对训练集和测试集的拟合程度。
八、可视化预测结果
通过图表展示真实值与预测值的对比,直观了解模型的表现。
代码示例:
ini 代码解读复制代码X = df_ads[['转发量']]
X.head()
y = df_ads.成交额
y.head()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# 画布 大小是 10x6
plt.figure(figsize=(10, 6))
# 散点图
plt.scatter(X_test, y_test, color='red',label="true value")
plt.plot(X_test, y_pred, color='red',
linewidth=2, label="predict value")
plt.xlabel("shares")
plt.ylabel("selles")
plt.title('shares VS selles')
plt.legend()
plt.grid(True)
plt.show()
 目的:
目的:
- 清晰展示模型预测的偏差。
总结与展望
通过本文介绍的步骤,我们完成了一个简单的机器学习工作流,包括数据加载、探索、预处理、建模、预测和评估。
求求官方别限流啦

如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】



















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











