








1. python包:lazypredict
lazypredict包功能:了解哪些模型在没有任何参数调整的情况下效果更好
1.1 安装lazypredict
- 直接用
pip安装:
pip install lazypredict
我这个是在安装xgboost时间超时报错,就下载了.whl文件后手动install xgboost,然后再install lazypredict. 【xgboost whl 该网页搜 xgboost】
1.2 使用lazypredict
官网的示例: https://pypi.org/project/lazypredict/
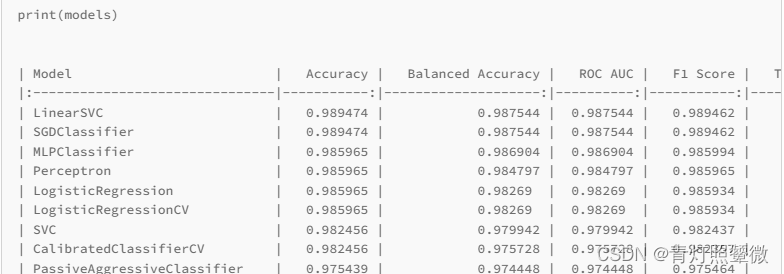
比如,使用这个lazypredict包中的分类:LazyClassifier,输出不同模型以及模型的评价参数,比如
R
2
R^2
R2。
from lazypredict.Supervised import LazyClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
data = load_breast_cancer()
X = data.data
y= data.target
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=.5,random_state =123)
clf = LazyClassifier(verbose=0,ignore_warnings=True, custom_metric=None)
models,predictions = clf.fit(X_train, X_test, y_train, y_test)
print(models)
比如,回归模型 LazyRegressor示例,也输出不同模型以及模型的评价参数,比如
R
2
R^2
R2。
from lazypredict.Supervised import LazyRegressor
from sklearn import datasets
from sklearn.utils import shuffle
import numpy as np
boston = datasets.load_boston()
X, y = shuffle(boston.data, boston.target, random_state=13)
X = X.astype(np.float32)
offset = int(X.shape[0] * 0.9)
X_train, y_train = X[:offset], y[:offset]
X_test, y_test = X[offset:], y[offset:]
reg = LazyRegressor(verbose=0, ignore_warnings=False, custom_metric=None)
models, predictions = reg.fit(X_train, X_test, y_train, y_test)
print(models)
其他参考:
https://statisticsbyjim.com/regression/curve-fitting-linear-nonlinear-regression/
https://statisticsbyjim.com/regression/choose-linear-nonlinear-regression/
https://www.jianshu.com/p/37b7f2046eaa
2. 选择模型
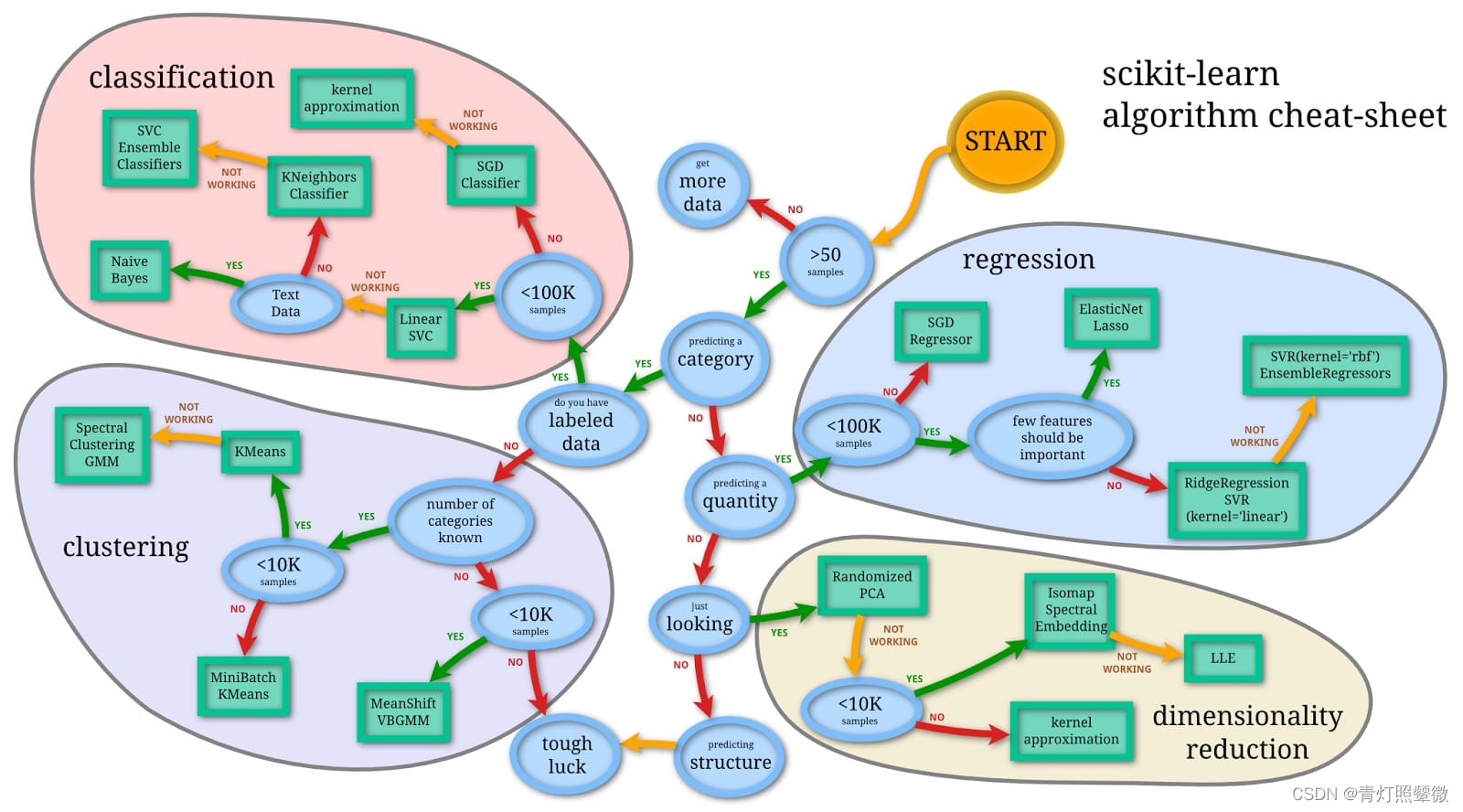
图来源:《如何选择机器学习的算法模型?》
用Python脚本梳理了一下图中的选择规则,就是用if...else...实现。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''
n: 样本个数
predicting_a_category: True: 样本数据是类别预测,False: 数据不是类别预测
data_labeled: True: 数据有标签, False: 数据没有标签
# num_categories_known: True:类别数目是已知的; False: 类别数据不是已知的 # 对于不是类别预测的数据
# predicting_a_quality: True: 是量化数据预测; False: 不是量化数据预测
# few_feature_important: True: 少数的特征是重要的;False: 多数特征是重要的
# JustLooking: True: 只是看看数据;Fals: 不只是看看
# predicting_structure: True: 是结构化预测 False: 不是结构化预测(没有具体的模型建议)
# ModelWorking: True: 当前模型起作用,False: 当前模型不起来作用
'''
import argparse
# n = '10000'
# predicting_a_category = True
# data_labeled = True
# ModelWorking = True # 默认用True, 如果提供的模型,测试后不起作用,设置False
def read_args():
parser = argparse.ArgumentParser(description=__doc__,
formatter_class=argparse.RawDescriptionHelpFormatter)
parser.add_argument('-n', '--num_samples', dest='num_samples',
metavar='INT', type=int, required=True,
help="set number of samples.")
parser.add_argument('--predicting_a_category', dest='predicting_a_category',
action='store_true', default=False,
help="set predict type is category or not, default: [False]")
parser.add_argument('--data_labeled', dest='data_labeled',
action='store_true', default=False,
help="set data is labeled or not, default: [False]")
parser.add_argument('--is_Text_Data', dest='is_Text_Data',
action='store_true', default=False,
help="set data format is text or not, default: [False]")
parser.add_argument('--num_categories_known', dest='num_categories_known',
action='store_true', default=False,
help="number of categories known or not, default: [False]")
parser.add_argument('--predicting_a_quality', dest='predicting_a_quality',
action='store_true', default=False,
help="set predict type is quality or not, default: [False]")
parser.add_argument('--few_feature_important', dest='few_feature_important',
action='store_true', default=False,
help="few feature should be inportant or not, default: [False]")
parser.add_argument('--JustLooking', dest='JustLooking',
action='store_true', default=False,
help="just looking or not, default: [False]")
parser.add_argument('--predicting_structure', dest='predicting_structure',
action='store_true', default=False,
help="set predict type is structure or not, default: [False]")
parser.add_argument('--ModelWorking', dest='ModelWorking',
action='store_true', default=False,
help="set default recommend model working or not, default: [False]")
args = parser.parse_args()
return args
def recommend_model(n, predicting_a_category, data_labeled,
is_Text_Data=False,
num_categories_known=True,
predicting_a_quality=False,
few_feature_important=False,
JustLooking=False,
predicting_structure=False,
ModelWorking=True):
model = ''
if n <= 50:
print('NOTE: need more samples! at least >=50')
exit(1) # 样本量太小,需要获取更多样本
else:
if predicting_a_category: # 如果是一个类别预测
if data_labeled: # 数据有标签
# classification,分类
if n < 100000: # n < 100,000
model = 'Linear SVC'
if not ModelWorking: # 如果该模型不起作用
if is_Text_Data: # 如果是文本数据
model = 'Naive Bayes'
else: # 如果不是文本数据
model = 'KNeighbors Classifier'
if not ModelWorking: # 如果该模型不起作用
model = 'SVC Ensemble Classifier'
else: # n >= 100,000
model = 'SGD Classifier'
if not ModelWorking:
model = 'kernel approximotion'
else:
# clustering, 聚类
if num_categories_known: # 如果类别数目已知
if n < 10000: # n < 10,000
model = 'KMeans'
if not ModelWorking:
model = 'Spectral Clustering GMM'
else:
model = 'MiniBatch KMeans'
else: # 如果类别数目未知
if n < 10000: # n < 10,000
model = 'MeanShift VBGMM'
else:
model = 'tough luck?' # 碰运气?
else:
if predicting_a_quality: # 如果是一个量化预测
if n < 100000: # n < 100,000
if few_feature_important: # 如果少数的特征是重要的
model = 'ElasticNet Lasso'
else:
model = "RidgeRegression SVR(kernel='liner')"
if not ModelWorking:
model = "SVR(kenel='rbf') EsembleRegression"
else: # n >= 100,000
model = 'SGD Regressor'
else: # 不是量化预测
if JustLooking: # 如果只是看以看?
# dimentionality reduction, 降维
model = 'Randomized PCA'
if not ModelWorking:
if n < 10000: # n < 10,000
model = 'Isomap Spectral Embedding'
if not ModelWorking:
model = 'LLE'
else: # n >= 10,000
model = 'kernel approximation'
else: # 不是只看看
if predicting_structure: # 如果是结构预测??
model = 'touch luck?' # 碰运气??
if model == '':
print('Opps, NotFound any model for you!')
else:
print('Found model: "%s" for you~' % model)
return model
if __name__ == '__main__':
params = read_args()
recommend_model(params.num_samples, params.predicting_a_category, params.data_labeled,
is_Text_Data=params.is_Text_Data,
num_categories_known=params.num_categories_known,
predicting_a_quality=params.predicting_a_quality,
few_feature_important=params.few_feature_important,
JustLooking=params.JustLooking,
predicting_structure=params.predicting_structure,
ModelWorking=params.ModelWorking)
3. 常用第三方库
神经网络、线性代数、可视化等代码速查表-github 这个速查表中列出了一些常见库的基本用法.
比如, pandas:

-
pandas: 最常用的数据处理库; -
matplotlib: 画图常用库; 还有ggplot库用法(R语言); -
numpy: 多维数组的操作进行数值运算, 是一个基础库; -
scipy: 在numpy基础上扩展, 专注于科学计算的常用库; -
sklear: 机器学习常用库; -
tensorflow: google开发维护的机器学习库. 主要用于用于深度学习任务,如图像分类、自然语言处理、语音识别等. 特点包括: [来自chatGPT]- 计算图:TensorFlow使用计算图来表示机器学习模型。计算图是一种有向无环图,其中节点表示操作(例如加法、乘法)或变量(例如权重、偏置),边表示数据流。这种计算图的表示方式使得TensorFlow能够高效地执行大规模的计算任务,并且可以方便地进行分布式计算。
- 自动求导:TensorFlow提供了自动求导的功能,可以自动计算模型中各个参数对损失函数的梯度。这使得模型的训练过程更加简单,可以使用各种优化算法更新模型的参数,以最小化损失函数。
- 多平台支持:TensorFlow可以在多种硬件平台上运行,包括CPU、GPU和TPU(Tensor Processing Unit)。这使得您可以根据需要选择最适合的硬件来加速计算,并处理大规模的数据集。
- 高级抽象:TensorFlow提供了高级抽象层,如Keras和Estimator API,使得构建模型变得更加简单。这些API提供了一组易于使用的接口,可以快速搭建各种类型的机器学习模型。
示例:构建和执行计算图
import tensorflow as tf # 创建计算图 a = tf.constant(5, name="input_a") b = tf.constant(3, name="input_b") c = tf.multiply(a, b, name="mul_c") d = tf.add(a, b, name="add_d") e = tf.add(c, d, name="add_e") # 创建会话(Session)并执行计算图 with tf.Session() as sess: result = sess.run(e) print("计算结果:", result) -
kears: 深度学习常用库, 底层使用了其他深度学习框架(如TensorFlow)作为计算引擎. Keras特点包括:[chagGPT]- 简单易用:Keras提供了一系列简单易懂的API,使得深度学习模型的构建变得非常直观和容易上手。
- 模块化:Keras的设计理念是模块化的,用户可以根据需要选择合适的层和模型组件,并将它们组合成更复杂的模型。
- 可扩展性:Keras提供了丰富的层和模型组件库,用户可以通过组合这些组件来创建自定义的深度学习模型,并方便地扩展和定制模型结构。
- 多后端支持:Keras可以基于多个后端计算引擎实现,包括TensorFlow、Theano和CNTK等。这意味着用户可以根据自己的需求选择适合的后端,来进行模型的训练和预测。
-
spark: 用于大规模数据处理和分析的高级引擎, 一个快速、通用且易于使用的大数据处理框架。它支持在集群上进行分布式数据处理,可以处理大规模数据集,并提供了各种数据处理和分析工具,如数据清洗、转换、聚合、机器学习和图形处理等。主要用途包括:[chatGPT]- 大规模数据处理:Python Spark可以处理大型数据集,内置的分布式计算引擎使得可以进行高效的数据处理和分析操作,如过滤、映射、聚合和排序等。
- 数据清洗和转换:Python Spark提供了各种功能强大的操作和函数,用于清洗、转换和整理数据,以便后续分析任务使用。您可以使用Python的代码编写复杂的数据处理逻辑。
- 分布式机器学习:Python Spark提供了机器学习库(MLlib),其中包含了丰富的机器学习算法和工具,可用于构建和训练大规模的机器学习模型。MLlib支持常见的机器学习任务,如分类、回归、聚类和推荐等。
- 流处理和实时分析:Python Spark支持流式数据处理(Spark Streaming),可以处理实时数据流,并在数据到达时进行实时计算和分析。
- 图形处理和图计算:Python Spark提供了一个图形处理库(GraphX),可以进行图形分析和图计算任务,如社交网络分析、路径查找和图形可视化等。
from pyspark.sql import SparkSession from graphframes import GraphFrame # 创建SparkSession spark = SparkSession.builder.appName("GraphVisualizationExample").getOrCreate() # 创建顶点DataFrame vertices = spark.createDataFrame([ ("A", "Alice"), ("B", "Bob"), ("C", "Charlie"), ("D", "David"), ("E", "Esther"), ("F", "Fanny") ], ["id", "name"]) # 创建边DataFrame edges = spark.createDataFrame([ ("A", "B", "friend"), ("B", "C", "follow"), ("C", "D", "friend"), ("D", "E", "follow"), ("E", "F", "friend"), ("F", "A", "follow") ], ["src", "dst", "relationship"]) # 创建图对象 graph = GraphFrame(vertices, edges) # 执行路径查找 paths = graph.find("(a)-[e]->(b); (b)-[e2]->(c)").filter("a.id != c.id") # 输出路径 paths.show() # 可视化图形 graph.vertices.show() graph.edges.show() # 停止SparkSession spark.stop()spark安装命令:# pip install pyspark pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple pip install graphframes -
bokeh: 交互式数据可视化的Python库。Bokeh的设计目标是使数据科学家和分析师能够快速有效地探索和传达数据。特点包括: [来自chatGPT]- 交互性:Bokeh可以生成交互式图表,使用户能够与图表进行交互,如缩放、平移、悬停等。这使得用户能够以多个角度查看数据并进行详细分析。
- 多种图表类型:Bokeh支持多种常见的图表类型,包括折线图、散点图、柱状图、饼图、箱线图等。您可以使用Bokeh轻松创建各种类型的图表,并根据需要自定义样式和布局。
- Web浏览器展示:Bokeh生成的图表可以直接在Web浏览器中展示,无需任何插件或额外的软件。这意味着您可以轻松地将Bokeh图表集成到Web应用程序、报告或演示文稿中。
- 与其他Python库的集成:Bokeh可以与其他流行的Python库(如Pandas和NumPy)无缝集成。您可以使用这些库来处理和分析数据,然后使用Bokeh轻松地将结果可视化。
- 丰富的布局选项:Bokeh提供了多种布局选项,使您能够创建复杂的可视化仪表盘。您可以灵活地安排图表、小部件和控件,以便在一个页面上展示多个图表并进行交互。
- 大型社区和生态系统:TensorFlow有一个庞大的开发者社区,提供了大量的文档、教程和示例代码,以帮助新用户入门。此外,TensorFlow还有丰富的生态系统,支持各种常用的机器学习任务和技术。
from bokeh.plotting import figure, show from bokeh.models import HoverTool # 创建一个新的绘图对象 p = figure(title="折线图", x_axis_label="x轴", y_axis_label="y轴") # 添加一条折线 x = [1, 2, 3, 4, 5] y = [6, 7, 2, 4, 5] p.line(x, y, legend_label="折线", line_width=2) # 添加悬停工具 hover = HoverTool(tooltips=[("x", "$x"), ("y", "$y")]) p.add_tools(hover) # 显示图表 show(p) -
除了一些常用库的介绍, 还有数据结构/复杂度O()/排序算法的复杂度等
weka:基于Java编程的机器学习软件工具,用于数据挖掘和数据分析。它提供了大量的机器学习算法和工具,可用于预处理数据、特征选择、分类、聚类、回归等任务。
简要介绍了有哪些"比较流行的机器学习算法"。
不同类别的算法:图片来源《如何学习机器学习算法》


















 2435
2435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









