







 1.平方差损失函数 && Sigmoid激活函数1.1 Sigmoid函数 Sigmoid函数的表达式为:σ(z)=11+e−z\sigma(z)=\frac{1}{1+e^{-z}}σ(z)=1+e−z1 对...
1.平方差损失函数 && Sigmoid激活函数1.1 Sigmoid函数 Sigmoid函数的表达式为:σ(z)=11+e−z\sigma(z)=\frac{1}{1+e^{-z}}σ(z)=1+e−z1 对...
文章目录
1.平方差损失函数 && Sigmoid激活函数
1.1 Sigmoid函数
Sigmoid函数的表达式为: σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1 对应的函数图像为:
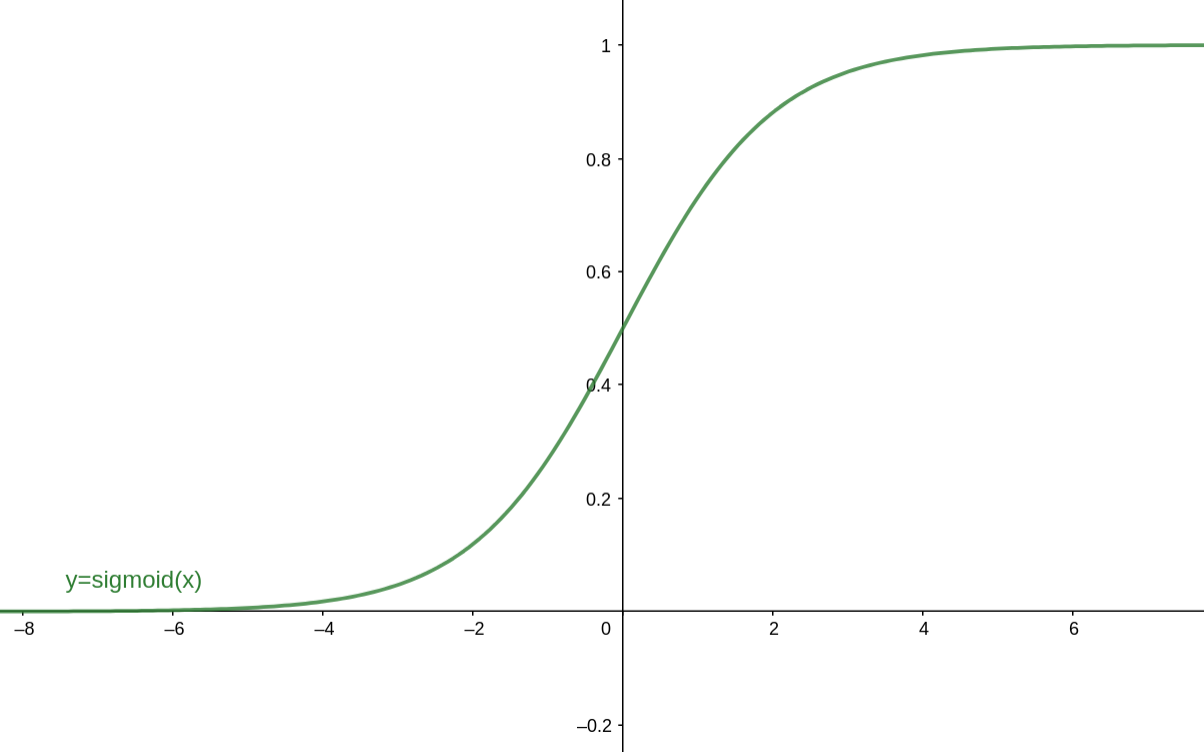
在以前,Sigmoid函数因为具有良好的神经元激活频率的解释(从完全不激活0到完全激活状态1),经常被用作神经网络的激活函数,然而现在不太受欢迎了,主要是因为以下三个缺点:
1.Sigmoid函数饱和时使梯度消失。Sigmoid神经元有一个不好的特性,就是当神经元的激活值在接近0或1处会饱和,在这些区域,会导致梯度几乎为0(从图像可以看到,导数值几乎为0)!回顾一下,在反向传播的时候,我们更新 W l 和 b l W^l和b^l Wl和bl梯度时,都会乘上Sigmoid的梯度,如果这个Sigmoid的梯度非常小,那么就会导致相乘的最终结果为接近0,即导致梯度消失。(文章下面会有详细公式说明)
2.Sigmoid函数的输出不是零中心的,这没有满足我们想要的性质。在神经网络后面层中的神经元,得到的输入值(上一层的激活值)数据不是零中心的,如果输入的数据总是正数,那么关于w的梯度,在反向传播的过程中,将会要么全是正数,要么全是负数,导致梯度更新时,权重出现Z字型抖动,导致收敛的速度会变得很慢。不过如果采用批量梯度下降法时,整个批量的数据的梯度加起来,权重的更新会有不同的正负,收敛速度加快,因此相比于上个问题而言,这只是一个小问题。
3.Sigmoid函数中,涉及到指数运算,相比于其他的激活函数而言,这个计算起来较慢。
1.2 平方差损失函数在反向传播时的 W l 和 b l W^l和b^l Wl和bl梯度更新式
根据上一节所学,可知梯度的计算如下:
∂ J ( W , b , a , y ) ∂ W l = ∂ J ( W , b , a , y ) ∂ z l ∂ z l ∂ W l = δ l ( a l − 1 ) T ∂ J ( W , b , a , y ) ∂ b l = ∂ J ( W , b , a , y ) ∂ z l ∂ z l ∂ b L = δ l \begin{aligned} \frac{\partial J(W, b, a, y)}{\partial W^{l}} &=\frac{\partial J(W, b, a, y)}{\partial z^{l}} \frac{\partial z^{l}}{\partial W^{l}}=\delta^{l}\left(a^{l-1}\right)^{T} \\\\ \frac{\partial J(W, b, a, y)}{\partial b^{l}} &=\frac{\partial J(W, b, a, y)}{\partial z^{l}} \frac{\partial z^{l}}{\partial b^{L}}=\delta^{l} \end{aligned} ∂Wl∂J(W,b,a,y)∂bl∂J(W,b,a,y)=∂zl∂J(W,b,a,y)∂Wl∂zl=δl(al−1)T=∂zl∂J(W,b,a,y)∂bL∂zl=δl 其中, δ l \delta^l δl为:
δ l = δ l + 1 ∂ z l + 1 ∂ z l = ( W l + 1 ) T δ l + 1 ⊙ σ ′ ( z l ) \delta^{l}=\delta^{l+1} \frac{\partial z^{l+1}}{\partial z^{l}}=\left(W^{l+1}\right)^{T} \delta^{l+1} \odot \sigma^{\prime}\left(z^{l}\right) δl=δl+1∂zl∂zl+1=(W
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









