






 本文深入解析BERT模型原理,涵盖安装、预训练模型、Fine-Tuning流程及数据处理,同时探讨分词、源码解读与性能优化策略。
本文深入解析BERT模型原理,涵盖安装、预训练模型、Fine-Tuning流程及数据处理,同时探讨分词、源码解读与性能优化策略。
目录
一、什么是BERT?
首先我们先看官方的介绍:
BERT is a method of pre-training language representations, meaning that we train a general-purpose "language understanding" model on a large text corpus (like Wikipedia), and then use that model for downstream NLP tasks that we care about (like question answering). BERT outperforms previous methods because it is the first unsupervised, deeply bidirectional system for pre-training NLP.
划重点:the first unsupervised, deeply bidirectional system for pre-training NLP.
无监督意味着BERT可以仅使用纯文本语料库进行训练,这是非常重要的特性,因为大量纯文本数据在网络上以多种语言公开。

(上面左图,红色的是ELMo,右二是BERT)
预训练方法可以粗略分为不联系上下文的词袋模型等和联系上下文的方法。其中联系上下文的方法可以进一步分为单向和双向联系上下文两种。诸如NNLM、Skip-Gram、 Glove等词袋模型,是一种单层Shallow模型,无法联系上下文;而LSTM、Transformer为典型的可以联系上下文的深层次网络模型。

BERT是在现有预训练工作的基础上对现有的技术的良好整合与一定的创新。现有的这些模型都是单向或浅双向的。每个单词仅使用左侧(或右侧)的单词进行语境化。例如,在句子中
I have fallen in love with a girl.
单向表示love仅基于I have fallen in 但不 基于with a girl。之前有一些模型也有可以联系上下文的,但仅以单层"shallow"的方式。BERT能联系上下文来表示“love” ----- I have fallen in ... with a girl。是一种深层次、双向的深度神经网络模型。
使用BERT有两个阶段:预训练和微调。
Pre-training 硬件成本相当昂贵(4--16个云TPU需4天),但是每种语言都只需要训练一次(目前的模型主要为英语)。为节省计算资源,谷歌正在发布一些预先培训的模型。
Fine-tuning 硬件成本相对较低。文中的实践可以在单个云TPU上(最多1小时)或者在GPU(几小时)复现出来。BERT的另一个重要方面是它可以适应许多类型的NLP任务:
- 句子级别(例如,SST-2)
- 句子对级别(例如,MultiNLI)
- 单词级别(例如,NER)
- 文本阅读(例如,SQuAD)
二、BERT安装
Google提供的BERT代码在这里,可以直接git clone下来。注意运行它需要Tensorflow 1.11及其以上的版本,低版本的Tensorflow不能运行。
三、预训练模型
由于从头开始(from scratch)训练需要巨大的计算资源,因此Google提供了预训练的模型(的checkpoint),目前包括英语、汉语和多语言3类模型:
BERT-Base, Uncased:12层,768隐藏,12头,110M参数BERT-Large, Uncased:24层,1024个隐藏,16个头,340M参数BERT-Base, Cased:12层,768隐藏,12头,110M参数BERT-Large, Cased:24层,1024个隐藏,16个头,340M参数BERT-Base, Multilingual Cased (New, recommended):104种语言,12层,768隐藏,12头,110M参数BERT-Base, Multilingual Uncased (Orig, not recommended)(不推荐使用,Multilingual Cased代替使用):102种语言,12层,768隐藏,12头,110M参数BERT-Base, Chinese:中文简体和繁体,12层,768隐藏,12头,110M参数
Uncased的意思是在预处理的时候都变成了小写,而cased是保留大小写。
这么多版本应该如何选择呢?
如果我们处理的问题只包含英文,那么我们应该选择英语的版本(模型大效果好但是参数多训练慢而且需要更多内存/显存)。如果我们只处理中文,那么应该使用中文的版本。如果是其他语言就使用多语言的版本。
四、运行Fine-Tuning
对于大部分情况,不需要重新Pretraining。我们要做的只是根据具体的任务进行Fine-Tuning,因此我们首先介绍Fine-Tuning。这里我们已GLUE的MRPC为例子,我们首先需要下载预训练的模型然后解压,比如作者解压后的位置是:
/home/chai/data/chinese_L-12_H-768_A-12
# 为了方便我们需要定义环境变量
export BERT_BASE_DIR=/home/chai/data/chinese_L-12_H-768_A-12
环境变量BERT_BASE_DIR是BERT Pretraining的目录,它包含如下内容:
~/data/chinese_L-12_H-768_A-12$ ls -1
bert_config.json
bert_model.ckpt.data-00000-of-00001
bert_model.ckpt.index
bert_model.ckpt.meta
vocab.txt
vocab.txt是模型的词典,这个文件会经常要用到,后面会讲到。
bert_config.json是BERT的配置(超参数),比如网络的层数,通常我们不需要修改,但是也会经常用到。
bert_model.ckpt*,这是预训练好的模型的checkpoint
Fine-Tuning模型的初始值就是来自于这些文件,然后根据不同的任务进行Fine-Tuning。
接下来我们需要下载GLUE数据,这可以使用这个脚本下载,可能需要代理才能下载。
但是大概率下载不下来,能下载的步骤也很麻烦,建议下载网盘的备份版本:
链接:https://pan.baidu.com/s/1-b4I3ocYhiuhu3bpSmCJ_Q
提取码:z6mk
假设下载后的位置是:
/home/chai/data/glue_data
# 同样为了方便,我们定义如下的环境变量
export GLUE_DIR=/home/chai/data/glue_data
GLUE有很多任务,我们来看其中的MRPC任务。
chai:~/data/glue_data/MRPC$ head test.tsv
index #1 ID #2 ID #1 String #2 String
0 1089874 1089925 PCCW 's chief operating officer , Mike Butcher , and Alex Arena , the chief financial officer , will report directly to Mr So . Current Chief Operating Officer Mike Butcher and Group Chief Financial Officer Alex Arena will report to So .
1 3019446 3019327 The world 's two largest automakers said their U.S. sales declined more than predicted last month as a late summer sales frenzy caused more of an industry backlash than expected . Domestic sales at both GM and No. 2 Ford Motor Co. declined more than predicted as a late summer sales frenzy prompted a larger-than-expected industry backlash .
数据是tsv(tab分割)文件,每行有4个用Tab分割的字段,分别表示index,第一个句子的id,第二个句子的id,第一个句子,第二个句子。也就是输入两个句子,模型判断它们是否同一个意思(Paraphrase)。如果是测试数据,那么第一列就是index(无意义),如果是训练数据,那么第一列就是0或者1,其中0代表不同的意思而1代表相同意思。接下来就可以运行如下命令来进行Fine-Tuning了:
python run_classifier.py \
--task_name=MRPC \
--do_train=true \
--do_eval=true \
--data_dir=$GLUE_DIR/MRPC \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=8 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=/tmp/mrpc_output/
这里简单的解释一下参数的含义,在后面的代码阅读里读者可以更加详细的了解其意义。
- task_name 任务的名字,这里我们Fine-Tuning MRPC任务
- do_train 是否训练,这里为True
- do_eval 是否在训练结束后验证,这里为True
- data_dir 训练数据目录,配置了环境变量后不需要修改,否则填入绝对路径
- vocab_file BERT模型的词典
- bert_config_file BERT模型的配置文件
- init_checkpoint Fine-Tuning的初始化参数
- max_seq_length Token序列的最大长度,这里是128
- train_batch_size batch大小,对于普通8GB的GPU,最大batch大小只能是8,再大就会OOM
- learning_rate
- num_train_epochs 训练的epoch次数,根据任务进行调整
- output_dir 训练得到的模型的存放目录
这里最常见的问题就是内存不够,通常我们的GPU只有8G作用的显存,因此对于小的模型(bert-base),我们最多使用batchsize=8,而如果要使用bert-large,那么batchsize只能设置成1。运行结束后可能得到类似如下的结果:
***** Eval results *****
eval_accuracy = 0.845588
eval_loss = 0.505248
global_step = 343
loss = 0.505248
这说明在验证集上的准确率是0.84左右。
五、数据读取源码阅读
(一) DataProcessor
我们首先来看数据是怎么读入的。这是一个抽象基类,定义了get_train_examples、get_dev_examples、get_test_examples和get_labels等4个需要子类实现的方法,另外提供了一个_read_tsv函数用于读取tsv文件。下面我们通过一个实现类MrpcProcessor来了解怎么实现这个抽象基类,如果读者想使用自己的数据,那么就需要自己实现一个新的子类。
(二) MrpcProcessor
对于MRPC任务,这里定义了MrpcProcessor来基础DataProcessor。我们来看其中的get_labels和get_train_examples,其余两个抽象方法是类似的。首先是get_labels,它非常简单,这任务只有两个label。
def get_labels(self):
return ["0", "1"]
接下来是get_train_examples:
def get_train_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
这个函数首先使用_read_tsv读入训练文件train.tsv,然后使用_create_examples函数把每一行变成一个InputExample对象。
def _create_examples(self, lines, set_type):
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
text_a = tokenization.convert_to_unicode(line[3])
text_b = tokenization.convert_to_unicode(line[4])
if set_type == "test":
label = "0"
else:
label = tokenization.convert_to_unicode(line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return examples
代码非常简单,line是一个list,line[3]和line[4]分别代表两个句子,如果是训练集合和验证集合,那么第一列line[0]就是真正的label,而如果是测试集合,label就没有意义,随便赋值成”0”。然后对于所有的字符串都使用tokenization.convert_to_unicode把字符串变成unicode的字符串。这是为了兼容Python2和Python3,因为Python3的str就是unicode,而Python2的str其实是bytearray,Python2却有一个专门的unicode类型。感兴趣的读者可以参考其实现,不感兴趣的可以忽略。
最终构造出一个InputExample对象来,它有4个属性:guid、text_a、text_b和label,guid只是个唯一的id而已。text_a代表第一个句子,text_b代表第二个句子,第二个句子可以为None,label代表分类标签。
六、分词源码阅读
分词是我们需要重点关注的代码,因为如果想要把BERT产品化,我们需要使用Tensorflow Serving,Tensorflow Serving的输入是Tensor,把原始输入变成Tensor一般需要在Client端完成。BERT的分词是Python的代码,如果我们使用其它语言的gRPC Client,那么需要用其它语言实现同样的分词算法,否则预测时会出现问题。
这部分代码需要读者有Unicode的基础知识,了解什么是CodePoint,什么是Unicode Block。Python2和Python3的str有什么区别,Python2的unicode类等价于Python3的str等等。不熟悉的读者可以参考一些资料。
(一)FullTokenizer
BERT里分词主要是由FullTokenizer类来实现的。
class FullTokenizer(object):
def __init__(self, vocab_file, do_lower_case=True):
self.vocab = load_vocab(vocab_file)
self.basic_tokenizer = BasicTokenizer(do_lower_case=do_lower_case)
self.wordpiece_tokenizer = WordpieceTokenizer(vocab=self.vocab)
def tokenize(self, text):
split_tokens = []
for token in self.basic_tokenizer.tokenize(text):
for sub_token in self.wordpiece_tokenizer.tokenize(token):
split_tokens.append(sub_token)
return split_tokens
def convert_tokens_to_ids(self, tokens):
return convert_tokens_to_ids(self.vocab, tokens)
FullTokenizer的构造函数需要传入参数词典vocab_file和do_lower_case。如果我们自己从头开始训练模型(后面会介绍),那么do_lower_case决定了我们的某些是否区分大小写。如果我们只是Fine-Tuning,那么这个参数需要与模型一致,比如模型是chinese_L-12_H-768_A-12,那么do_lower_case就必须为True。
函数首先调用load_vocab加载词典,建立词到id的映射关系。下面是文件chinese_L-12_H-768_A-12/vocab.txt的部分内容
馬
高
龍
龸
fi
fl
!
(
)
,
-
.
/
:
?
~
the
of
and
in
to
接下来是构造BasicTokenizer和WordpieceTokenizer。前者是根据空格等进行普通的分词,而后者会把前者的结果再细粒度的切分为WordPiece。
tokenize函数实现分词,它先调用BasicTokenizer进行分词,接着调用WordpieceTokenizer把前者的结果再做细粒度切分。下面我们来详细阅读这两个类的代码。我们首先来看BasicTokenizer的tokenize方法。
def tokenize(self, text):
text = convert_to_unicode(text)
text = self._clean_text(text)
# 这是2018年11月1日为了支持多语言和中文增加的代码。这个代码也可以用于英语模型,因为在
# 英语的训练数据中基本不会出现中文字符(但是某些wiki里偶尔也可能出现中文)。
text = self._tokenize_chinese_chars(text)
orig_tokens = whitespace_tokenize(text)
split_tokens = []
for token in orig_tokens:
if self.do_lower_case:
token = token.lower()
token = self._run_strip_accents(token)
split_tokens.extend(self._run_split_on_punc(token))
output_tokens = whitespace_tokenize(" ".join(split_tokens))
return output_tokens
首先是用convert_to_unicode把输入变成unicode,这个函数前面也介绍过了。接下来是_clean_text函数,它的作用是去除一些无意义的字符。
def _clean_text(self, text):
"""去除一些无意义的字符以及whitespace"""
output = []
for char in text:
cp = ord(char)
if cp == 0 or cp == 0xfffd or _is_control(char):
continue
if _is_whitespace(char):
output.append(" ")
else:
output.append(char)
return "".join(output)
codepoint为0的是无意义的字符,0xfffd(U+FFFD)显示为�,通常用于替换未知的字符。_is_control用于判断一个字符是否是控制字符(control character),所谓的控制字符就是用于控制屏幕的显示,比如\n告诉(控制)屏幕把光标移到下一行的开始。读者可以参考这里。
def _is_control(char):
"""检查字符char是否是控制字符"""
# 回车换行和tab理论上是控制字符,但是这里我们把它认为是whitespace而不是控制字符
if char == "\t" or char == "\n" or char == "\r":
return False
cat = unicodedata.category(char)
if cat.startswith("C"):
return True
return False
这里使用了unicodedata.category这个函数,它返回这个Unicode字符的Category,这里C开头的都被认为是控制字符,读者可以参考这里。
接下来是调用_is_whitespace函数,把whitespace变成空格。
def _is_whitespace(char):
"""Checks whether `chars` is a whitespace character."""
# \t, \n, and \r are technically contorl characters but we treat them
# as whitespace since they are generally considered as such.
if char == " " or char == "\t" or char == "\n" or char == "\r":
return True
cat = unicodedata.category(char)
if cat == "Zs":
return True
return False
这里把category为Zs的字符以及空格、tab、换行和回车当成whitespace。然后是_tokenize_chinese_chars,用于切分中文,这里的中文分词很简单,就是切分成一个一个的汉字。也就是在中文字符的前后加上空格,这样后续的分词流程会把没一个字符当成一个词。
def _tokenize_chinese_chars(self, text):
output = []
for char in text:
cp = ord(char)
if self._is_chinese_char(cp):
output.append(" ")
output.append(char)
output.append(" ")
else:
output.append(char)
return "".join(output)
这里的关键是调用_is_chinese_char函数,这个函数用于判断一个unicode字符是否中文字符。
def _is_chinese_char(self, cp):
if ((cp >= 0x4E00 and cp <= 0x9FFF) or #
(cp >= 0x3400 and cp <= 0x4DBF) or #
(cp >= 0x20000 and cp <= 0x2A6DF) or #
(cp >= 0x2A700 and cp <= 0x2B73F) or #
(cp >= 0x2B740 and cp <= 0x2B81F) or #
(cp >= 0x2B820 and cp <= 0x2CEAF) or
(cp >= 0xF900 and cp <= 0xFAFF) or #
(cp >= 0x2F800 and cp <= 0x2FA1F)): #
return True
return False
很多网上的判断汉字的正则表达式都只包括4E00-9FA5,但这是不全的,比如 㐈 就不再这个范围内。读者可以参考这里。
接下来是使用whitespace进行分词,这是通过函数whitespace_tokenize来实现的。它直接调用split函数来实现分词。Python里whitespace包括’\t\n\x0b\x0c\r ‘。然后遍历每一个词,如果需要变成小写,那么先用lower()函数变成小写,接着调用_run_strip_accents函数去除accent。它的代码为:
def _run_strip_accents(self, text):
text = unicodedata.normalize("NFD", text)
output = []
for char in text:
cat = unicodedata.category(char)
if cat == "Mn":
continue
output.append(char)
return "".join(output)
它首先调用unicodedata.normalize(“NFD”, text)对text进行归一化。这个函数有什么作用呢?我们先看一下下面的代码:
>>> s1 = 'café'
>>> s2 = 'cafe\u0301'
>>> s1, s2
('café', 'café')
>>> len(s1), len(s2)
(4, 5)
>>> s1 == s2
False
我们”看到”的é其实可以有两种表示方法,一是用一个codepoint直接表示”é”,另外一种是用”e”再加上特殊的codepoint U+0301两个字符来表示。U+0301是COMBINING ACUTE ACCENT,它跟在e之后就变成了”é”。类似的”a\u0301”显示出来就是”á”。注意:这只是打印出来一模一样而已,但是在计算机内部的表示它们完全不同的,前者é是一个codepoint,值为0xe9,而后者是两个codepoint,分别是0x65和0x301。unicodedata.normalize(“NFD”, text)就会把0xe9变成0x65和0x301,比如下面的测试代码。
接下来遍历每一个codepoint,把category为Mn的去掉,比如前面的U+0301,COMBINING ACUTE ACCENT就会被去掉。category为Mn的所有Unicode字符完整列表在这里。
s = unicodedata.normalize("NFD", "é")
for c in s:
print("%#x" %(ord(c)))
# 输出为:
0x65
0x301
处理完大小写和accent之后得到的Token通过函数_run_split_on_punc再次用标点切分。这个函数会对输入字符串用标点进行切分,返回一个list,list的每一个元素都是一个char。比如输入he’s,则输出是[[h,e], [’],[s]]。代码很简单,这里就不赘述。里面它会调用函数_is_punctuation来判断一个字符是否标点。
def _is_punctuation(char):
cp = ord(char)
# 我们把ASCII里非字母数字都当成标点。
# 在Unicode的category定义里, "^", "$", and "`" 等都不是标点,但是我们这里都认为是标点。
if ((cp >= 33 and cp <= 47) or (cp >= 58 and cp <= 64) or
(cp >= 91 and cp <= 96) or (cp >= 123 and cp <= 126)):
return True
cat = unicodedata.category(char)
# category是P开头的都是标点,参考https://en.wikipedia.org/wiki/Unicode_character_property
if cat.startswith("P"):
return True
return False
(二) WordpieceTokenizer
WordpieceTokenizer的作用是把词再切分成更细粒度的WordPiece。WordPiece(Byte Pair Encoding)是一种解决OOV问题的方法,如果不管细节,我们把它看成比词更小的基本单位就行。对于中文来说,WordpieceTokenizer什么也不干,因为之前的分词已经是基于字符的了。有兴趣的读者可以参考这个开源项目。一般情况我们不需要自己重新生成WordPiece,使用BERT模型里自带的就行。
WordpieceTokenizer的代码为:
def tokenize(self, text):
# 把一段文字切分成word piece。这其实是贪心的最大正向匹配算法。
# 比如:
# input = "unaffable"
# output = ["un", "##aff", "##able"]
text = convert_to_unicode(text)
output_tokens = []
for token in whitespace_tokenize(text):
chars = list(token)
if len(chars) > self.max_input_chars_per_word:
output_tokens.append(self.unk_token)
continue
is_bad = False
start = 0
sub_tokens = []
while start < len(chars):
end = len(chars)
cur_substr = None
while start < end:
substr = "".join(chars[start:end])
if start > 0:
substr = "##" + substr
if substr in self.vocab:
cur_substr = substr
break
end -= 1
if cur_substr is None:
is_bad = True
break
sub_tokens.append(cur_substr)
start = end
if is_bad:
output_tokens.append(self.unk_token)
else:
output_tokens.extend(sub_tokens)
return output_tokens
代码有点长,但是很简单,就是贪心的最大正向匹配。其实为了加速,是可以把词典加载到一个Double Array Trie里的。我们用一个例子来看代码的执行过程。比如假设输入是”unaffable”。我们跳到while循环部分,这是start=0,end=len(chars)=9,也就是先看看unaffable在不在词典里,如果在,那么直接作为一个WordPiece,如果不再,那么end-=1,也就是看unaffabl在不在词典里,最终发现”un”在词典里,把un加到结果里。
接着start=2,看affable在不在,不在再看affabl,…,最后发现 ##aff 在词典里。注意:##表示这个词是接着前面的,这样使得WordPiece切分是可逆的——我们可以恢复出“真正”的词。
七、run_classifier.py的main函数
main函数的主要代码为:
main()
bert_config = modeling.BertConfig.from_json_file(FLAGS.bert_config_file)
task_name = FLAGS.task_name.lower()
processor = processors[task_name]()
label_list = processor.get_labels()
tokenizer = tokenization.FullTokenizer(
vocab_file=FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case)
run_config = tf.contrib.tpu.RunConfig(
cluster=tpu_cluster_resolver,
master=FLAGS.master,
model_dir=FLAGS.output_dir,
save_checkpoints_steps=FLAGS.save_checkpoints_steps,
tpu_config=tf.contrib.tpu.TPUConfig(
iterations_per_loop=FLAGS.iterations_per_loop,
num_shards=FLAGS.num_tpu_cores,
per_host_input_for_training=is_per_host))
train_examples = None
num_train_steps = None
num_warmup_steps = None
if FLAGS.do_train:
train_examples = processor.get_train_examples(FLAGS.data_dir)
num_train_steps = int(
len(train_examples) / FLAGS.train_batch_size * FLAGS.num_train_epochs)
num_warmup_steps = int(num_train_steps * FLAGS.warmup_proportion)
model_fn = model_fn_builder(
bert_config=bert_config,
num_labels=len(label_list),
init_checkpoint=FLAGS.init_checkpoint,
learning_rate=FLAGS.learning_rate,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
use_tpu=FLAGS.use_tpu,
use_one_hot_embeddings=FLAGS.use_tpu)
# 如果没有TPU,那么会使用GPU或者CPU
estimator = tf.contrib.tpu.TPUEstimator(
use_tpu=FLAGS.use_tpu,
model_fn=model_fn,
config=run_config,
train_batch_size=FLAGS.train_batch_size,
eval_batch_size=FLAGS.eval_batch_size,
predict_batch_size=FLAGS.predict_batch_size)
if FLAGS.do_train:
train_file = os.path.join(FLAGS.output_dir, "train.tf_record")
file_based_convert_examples_to_features(
train_examples, label_list, FLAGS.max_seq_length, tokenizer, train_file)
train_input_fn = file_based_input_fn_builder(
input_file=train_file,
seq_length=FLAGS.max_seq_length,
is_training=True,
drop_remainder=True)
estimator.train(input_fn=train_input_fn, max_steps=num_train_steps)
if FLAGS.do_eval:
eval_examples = processor.get_dev_examples(FLAGS.data_dir)
eval_file = os.path.join(FLAGS.output_dir, "eval.tf_record")
file_based_convert_examples_to_features(
eval_examples, label_list, FLAGS.max_seq_length, tokenizer, eval_file)
# This tells the estimator to run through the entire set.
eval_steps = None
eval_drop_remainder = True if FLAGS.use_tpu else False
eval_input_fn = file_based_input_fn_builder(
input_file=eval_file,
seq_length=FLAGS.max_seq_length,
is_training=False,
drop_remainder=eval_drop_remainder)
result = estimator.evaluate(input_fn=eval_input_fn, steps=eval_steps)
if FLAGS.do_predict:
predict_examples = processor.get_test_examples(FLAGS.data_dir)
predict_file = os.path.join(FLAGS.output_dir, "predict.tf_record")
file_based_convert_examples_to_features(predict_examples, label_list,
FLAGS.max_seq_length, tokenizer, predict_file)
predict_drop_remainder = True if FLAGS.use_tpu else False
predict_input_fn = file_based_input_fn_builder(
input_file=predict_file,
seq_length=FLAGS.max_seq_length,
is_training=False,
drop_remainder=predict_drop_remainder)
result = estimator.predict(input_fn=predict_input_fn)
这里使用的是Tensorflow的Estimator API,这里只介绍训练部分的代码。
首先是通过file_based_convert_examples_to_features函数把输入的tsv文件变成TFRecord文件,便于Tensorflow处理。
train_file = os.path.join(FLAGS.output_dir, "train.tf_record")
file_based_convert_examples_to_features(
train_examples, label_list, FLAGS.max_seq_length, tokenizer, train_file)
def file_based_convert_examples_to_features(
examples, label_list, max_seq_length, tokenizer, output_file):
writer = tf.python_io.TFRecordWriter(output_file)
for (ex_index, example) in enumerate(examples):
feature = convert_single_example(ex_index, example, label_list,
max_seq_length, tokenizer)
def create_int_feature(values):
f = tf.train.Feature(int64_list=tf.train.Int64List(value=list(values)))
return f
features = collections.OrderedDict()
features["input_ids"] = create_int_feature(feature.input_ids)
features["input_mask"] = create_int_feature(feature.input_mask)
features["segment_ids"] = create_int_feature(feature.segment_ids)
features["label_ids"] = create_int_feature([feature.label_id])
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
writer.write(tf_example.SerializeToString())
file_based_convert_examples_to_features函数遍历每一个example(InputExample类的对象)。然后使用convert_single_example函数把每个InputExample对象变成InputFeature。InputFeature就是一个存放特征的对象,它包括input_ids、input_mask、segment_ids和label_id,这4个属性除了label_id是一个int之外,其它都是int的列表,因此使用create_int_feature函数把它变成tf.train.Feature,而label_id需要构造一个只有一个元素的列表,最后构造tf.train.Example对象,然后写到TFRecord文件里。后面Estimator的input_fn会用到它。
这里的最关键是convert_single_example函数,读懂了它就真正明白BERT把输入表示成向量的过程,所以请读者仔细阅读代码和其中的注释。
def convert_single_example(ex_index, example, label_list, max_seq_length,
tokenizer):
"""把一个`InputExample`对象变成`InputFeatures`."""
# label_map把label变成id,这个函数每个example都需要执行一次,其实是可以优化的。
# 只需要在可以再外面执行一次传入即可。
label_map = {}
for (i, label) in enumerate(label_list):
label_map[label] = i
tokens_a = tokenizer.tokenize(example.text_a)
tokens_b = None
if example.text_b:
tokens_b = tokenizer.tokenize(example.text_b)
if tokens_b:
# 如果有b,那么需要保留3个特殊Token[CLS], [SEP]和[SEP]
# 如果两个序列加起来太长,就需要去掉一些。
_truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3)
else:
# 没有b则只需要保留[CLS]和[SEP]两个特殊字符
# 如果Token太多,就直接截取掉后面的部分。
if len(tokens_a) > max_seq_length - 2:
tokens_a = tokens_a[0:(max_seq_length - 2)]
# BERT的约定是:
# (a) 对于两个序列:
# tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]
# type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1
# (b) 对于一个序列:
# tokens: [CLS] the dog is hairy . [SEP]
# type_ids: 0 0 0 0 0 0 0
#
# 这里"type_ids"用于区分一个Token是来自第一个还是第二个序列
# 对于type=0和type=1,模型会学习出两个Embedding向量。
# 虽然理论上这是不必要的,因为[SEP]隐式的确定了它们的边界。
# 但是实际加上type后,模型能够更加容易的知道这个词属于那个序列。
#
# 对于分类任务,[CLS]对应的向量可以被看成 "sentence vector"
# 注意:一定需要Fine-Tuning之后才有意义
tokens = []
segment_ids = []
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
tokens.append("[SEP]")
segment_ids.append(0)
if tokens_b:
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
tokens.append("[SEP]")
segment_ids.append(1)
input_ids = tokenizer.convert_tokens_to_ids(tokens)
# mask是1表示是"真正"的Token,0则是Padding出来的。在后面的Attention时会通过tricky的技巧让
# 模型不能attend to这些padding出来的Token上。
input_mask = [1] * len(input_ids)
# padding使得序列长度正好等于max_seq_length
while len(input_ids) < max_seq_length:
input_ids.append(0)
input_mask.append(0)
segment_ids.append(0)
label_id = label_map[example.label]
feature = InputFeatures(
input_ids=input_ids,
input_mask=input_mask,
segment_ids=segment_ids,
label_id=label_id)
return feature
如果两个Token序列的长度太长,那么需要去掉一些,这会用到_truncate_seq_pair函数:
def _truncate_seq_pair(tokens_a, tokens_b, max_length):
while True:
total_length = len(tokens_a) + len(tokens_b)
if total_length <= max_length:
break
if len(tokens_a) > len(tokens_b):
tokens_a.pop()
else:
tokens_b.pop()
这个函数很简单,如果两个序列的长度小于max_length,那么不用truncate,否则在tokens_a和tokens_b中选择长的那个序列来pop掉最后面的那个Token,这样的结果是使得两个Token序列一样长(或者最多a比b多一个Token)。对于Estimator API来说,最重要的是实现model_fn和input_fn。我们先看input_fn,它是由file_based_input_fn_builder构造出来的。代码如下:
def file_based_input_fn_builder(input_file, seq_length, is_training,
drop_remainder):
name_to_features = {
"input_ids": tf.FixedLenFeature([seq_length], tf.int64),
"input_mask": tf.FixedLenFeature([seq_length], tf.int64),
"segment_ids": tf.FixedLenFeature([seq_length], tf.int64),
"label_ids": tf.FixedLenFeature([], tf.int64),
}
def _decode_record(record, name_to_features):
# 把record decode成TensorFlow example.
example = tf.parse_single_example(record, name_to_features)
# tf.Example只支持tf.int64,但是TPU只支持tf.int32.
# 因此我们把所有的int64变成int32.
for name in list(example.keys()):
t = example[name]
if t.dtype == tf.int64:
t = tf.to_int32(t)
example[name] = t
return example
def input_fn(params):
batch_size = params["batch_size"]
# 对于训练来说,我们会重复的读取和shuffling
# 对于验证和测试,我们不需要shuffling和并行读取。
d = tf.data.TFRecordDataset(input_file)
if is_training:
d = d.repeat()
d = d.shuffle(buffer_size=100)
d = d.apply(
tf.contrib.data.map_and_batch(
lambda record: _decode_record(record, name_to_features),
batch_size=batch_size,
drop_remainder=drop_remainder))
return d
return input_fn
这个函数返回一个函数input_fn。这个input_fn函数首先从文件得到TFRecordDataset,然后根据是否训练来shuffle和重复读取。然后用applay函数对每一个TFRecord进行map_and_batch,调用_decode_record函数对record进行parsing。从而把TFRecord的一条Record变成tf.Example对象,这个对象包括了input_ids等4个用于训练的Tensor。
接下来是model_fn_builder,它用于构造Estimator使用的model_fn。下面是它的主要代码(一些无关的log和TPU相关代码去掉了):
def model_fn_builder(bert_config, num_labels, init_checkpoint, learning_rate,
num_train_steps, num_warmup_steps, use_tpu,
use_one_hot_embeddings):
# 注意:在model_fn的设计里,features表示输入(特征),而labels表示输出
# 但是这里的实现有点不好,把label也放到了features里。
def model_fn(features, labels, mode, params):
input_ids = features["input_ids"]
input_mask = features["input_mask"]
segment_ids = features["segment_ids"]
label_ids = features["label_ids"]
is_training = (mode == tf.estimator.ModeKeys.TRAIN)
# 创建Transformer模型,这是最主要的代码。
(total_loss, per_example_loss, logits, probabilities) = create_model(
bert_config, is_training, input_ids, input_mask, segment_ids, label_ids,
num_labels, use_one_hot_embeddings)
tvars = tf.trainable_variables()
# 从checkpoint恢复参数
if init_checkpoint:
(assignment_map, initialized_variable_names) =
modeling.get_assignment_map_from_checkpoint(tvars, init_checkpoint)
tf.train.init_from_checkpoint(init_checkpoint, assignment_map)
output_spec = None
# 构造训练的spec
if mode == tf.estimator.ModeKeys.TRAIN:
train_op = optimization.create_optimizer(total_loss, learning_rate,
num_train_steps, num_warmup_steps, use_tpu)
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
train_op=train_op,
scaffold_fn=scaffold_fn)
# 构造eval的spec
elif mode == tf.estimator.ModeKeys.EVAL:
def metric_fn(per_example_loss, label_ids, logits):
predictions = tf.argmax(logits, axis=-1, output_type=tf.int32)
accuracy = tf.metrics.accuracy(label_ids, predictions)
loss = tf.metrics.mean(per_example_loss)
return {
"eval_accuracy": accuracy,
"eval_loss": loss,
}
eval_metrics = (metric_fn, [per_example_loss, label_ids, logits])
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
loss=total_loss,
eval_metrics=eval_metrics,
scaffold_fn=scaffold_fn)
# 预测的spec
else:
output_spec = tf.contrib.tpu.TPUEstimatorSpec(
mode=mode,
predictions=probabilities,
scaffold_fn=scaffold_fn)
return output_spec
return model_fn
这里的代码都是一些boilerplate代码,没什么可说的,最重要的是调用create_model”真正”的创建Transformer模型。下面我们来看这个函数的代码:
def create_model(bert_config, is_training, input_ids, input_mask, segment_ids,
labels, num_labels, use_one_hot_embeddings):
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
# 在这里,我们是用来做分类,因此我们只需要得到[CLS]最后一层的输出。
# 如果需要做序列标注,那么可以使用model.get_sequence_output()
# 默认参数下它返回的output_layer是[8, 768]
output_layer = model.get_pooled_output()
# 默认是768
hidden_size = output_layer.shape[-1].value
output_weights = tf.get_variable(
"output_weights", [num_labels, hidden_size],
initializer=tf.truncated_normal_initializer(stddev=0.02))
output_bias = tf.get_variable(
"output_bias", [num_labels], initializer=tf.zeros_initializer())
with tf.variable_scope("loss"):
if is_training:
# 0.1的概率会dropout
output_layer = tf.nn.dropout(output_layer, keep_prob=0.9)
# 对[CLS]输出的768的向量再做一个线性变换,输出为label的个数。得到logits
logits = tf.matmul(output_layer, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
probabilities = tf.nn.softmax(logits, axis=-1)
log_probs = tf.nn.log_softmax(logits, axis=-1)
one_hot_labels = tf.one_hot(labels, depth=num_labels, dtype=tf.float32)
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)
loss = tf.reduce_mean(per_example_loss)
return (loss, per_example_loss, logits, probabilities)
上面代码调用modeling.BertModel得到BERT模型,然后使用它的get_pooled_output方法得到[CLS]最后一层的输出,这是一个768(默认参数下)的向量,然后就是常规的接一个全连接层得到logits,然后softmax得到概率,之后就可以根据真实的分类标签计算loss。我们这时候发现关键的代码是modeling.BertModel。
八、BertModel类
这个类是最终定义模型的地方,代码比较多,我们会按照执行和调用的顺序逐个阅读。因为文字只能线性描述,但是函数的调用关系很复杂,所以建议读者对照源代码来阅读。
我们首先来看这个类的用法,把它当成黑盒。前面的create_model也用到了BertModel,这里我们在详细的介绍一下。下面的代码演示了BertModel的使用方法:
# 假设输入已经分词并且变成WordPiece的id了
# 输入是[2, 3],表示batch=2,max_seq_length=3
input_ids = tf.constant([[31, 51, 99], [15, 5, 0]])
# 第一个例子实际长度为3,第二个例子长度为2
input_mask = tf.constant([[1, 1, 1], [1, 1, 0]])
# 第一个例子的3个Token中前两个属于句子1,第三个属于句子2
# 而第二个例子的第一个Token属于句子1,第二个属于句子2(第三个是padding)
token_type_ids = tf.constant([[0, 0, 1], [0, 1, 0]])
# 创建一个BertConfig,词典大小是32000,Transformer的隐单元个数是512
# 8个Transformer block,每个block有6个Attention Head,全连接层的隐单元是1024
config = modeling.BertConfig(vocab_size=32000, hidden_size=512,
num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
# 创建BertModel
model = modeling.BertModel(config=config, is_training=True,
input_ids=input_ids, input_mask=input_mask, token_type_ids=token_type_ids)
# label_embeddings用于把512的隐单元变换成logits
label_embeddings = tf.get_variable(...)
# 得到[CLS]最后一层输出,把它看成句子的Embedding(Encoding)
pooled_output = model.get_pooled_output()
# 计算logits
logits = tf.matmul(pooled_output, label_embeddings)
接下来我们看一下BertModel的构造函数:
def __init__(self,
config,
is_training,
input_ids,
input_mask=None,
token_type_ids=None,
use_one_hot_embeddings=True,
scope=None):
# Args:
# config: `BertConfig` 对象
# is_training: bool 表示训练还是eval,是会影响dropout
# input_ids: int32 Tensor shape是[batch_size, seq_length]
# input_mask: (可选) int32 Tensor shape是[batch_size, seq_length]
# token_type_ids: (可选) int32 Tensor shape是[batch_size, seq_length]
# use_one_hot_embeddings: (可选) bool
# 如果True,使用矩阵乘法实现提取词的Embedding;否则用tf.embedding_lookup()
# 对于TPU,使用前者更快,对于GPU和CPU,后者更快。
# scope: (可选) 变量的scope。默认是"bert"
# Raises:
# ValueError: 如果config或者输入tensor的shape有问题就会抛出这个异常
config = copy.deepcopy(config)
if not is_training:
config.hidden_dropout_prob = 0.0
config.attention_probs_dropout_prob = 0.0
input_shape = get_shape_list(input_ids, expected_rank=2)
batch_size = input_shape[0]
seq_length = input_shape[1]
if input_mask is None:
input_mask = tf.ones(shape=[batch_size, seq_length], dtype=tf.int32)
if token_type_ids is None:
token_type_ids = tf.zeros(shape=[batch_size, seq_length], dtype=tf.int32)
with tf.variable_scope(scope, default_name="bert"):
with tf.variable_scope("embeddings"):
# 词的Embedding lookup
(self.embedding_output, self.embedding_table) = embedding_lookup(
input_ids=input_ids,
vocab_size=config.vocab_size,
embedding_size=config.hidden_size,
initializer_range=config.initializer_range,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=use_one_hot_embeddings)
# 增加位置embeddings和token type的embeddings,然后是
# layer normalize和dropout。
self.embedding_output = embedding_postprocessor(
input_tensor=self.embedding_output,
use_token_type=True,
token_type_ids=token_type_ids,
token_type_vocab_size=config.type_vocab_size,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=config.initializer_range,
max_position_embeddings=config.max_position_embeddings,
dropout_prob=config.hidden_dropout_prob)
with tf.variable_scope("encoder"):
# 把shape为[batch_size, seq_length]的2D mask变成
# shape为[batch_size, seq_length, seq_length]的3D mask
# 以便后向的attention计算,读者可以对比之前的Transformer的代码。
attention_mask = create_attention_mask_from_input_mask(
input_ids, input_mask)
# 多个Transformer模型stack起来。
# all_encoder_layers是一个list,长度为num_hidden_layers(默认12),每一层对应一个值。
# 每一个值都是一个shape为[batch_size, seq_length, hidden_size]的tensor。
self.all_encoder_layers = transformer_model(
input_tensor=self.embedding_output,
attention_mask=attention_mask,
hidden_size=config.hidden_size,
num_hidden_layers=config.num_hidden_layers,
num_attention_heads=config.num_attention_heads,
intermediate_size=config.intermediate_size,
intermediate_act_fn=get_activation(config.hidden_act),
hidden_dropout_prob=config.hidden_dropout_prob,
attention_probs_dropout_prob=config.attention_probs_dropout_prob,
initializer_range=config.initializer_range,
do_return_all_layers=True)
# `sequence_output` 是最后一层的输出,shape是[batch_size, seq_length, hidden_size]
self.sequence_output = self.all_encoder_layers[-1]
with tf.variable_scope("pooler"):
# 取最后一层的第一个时刻[CLS]对应的tensor
# 从[batch_size, seq_length, hidden_size]变成[batch_size, hidden_size]
# sequence_output[:, 0:1, :]得到的是[batch_size, 1, hidden_size]
# 我们需要用squeeze把第二维去掉。
first_token_tensor = tf.squeeze(self.sequence_output[:, 0:1, :], axis=1)
# 然后再加一个全连接层,输出仍然是[batch_size, hidden_size]
self.pooled_output = tf.layers.dense(
first_token_tensor,
config.hidden_size,
activation=tf.tanh,
kernel_initializer=create_initializer(config.initializer_range))
代码很长,但是其实很简单。首先是对config(BertConfig对象)深度拷贝一份,如果不是训练,那么把dropout都置为零。如果输入的input_mask为None,那么构造一个shape合适值全为1的input_mask,这表示输入都是”真实”的输入,没有padding的内容。如果token_type_ids为None,那么构造一个shape合适并且值全为0的tensor,表示所有Token都属于第一个句子。
然后使用embedding_lookup函数构造词的Embedding,用embedding_postprocessor函数增加位置embeddings和token type的embeddings,然后是layer normalize和dropout。
接着用transformer_model函数构造多个Transformer SubLayer然后stack在一起。得到的all_encoder_layers是一个list,长度为num_hidden_layers(默认12),每一层对应一个值。 每一个值都是一个shape为[batch_size, seq_length, hidden_size]的tensor。
self.sequence_output是最后一层的输出,shape是[batch_size, seq_length, hidden_size]。first_token_tensor是第一个Token([CLS])最后一层的输出,shape是[batch_size, hidden_size]。最后对self.sequence_output再加一个线性变换,得到的tensor仍然是[batch_size, hidden_size]。
embedding_lookup函数用于实现Embedding,它有两种方式:使用tf.nn.embedding_lookup和矩阵乘法(one_hot_embedding=True)。前者适合于CPU与GPU,后者适合于TPU。所谓的one-hot方法是把输入id表示成one-hot的向量,当然输入id序列就变成了one-hot的矩阵,然后乘以Embedding矩阵。而tf.nn.embedding_lookup是直接用id当下标提取Embedding矩阵对应的向量。一般认为tf.nn.embedding_lookup更快一点,但是TPU上似乎不是这样,作者也不太了解原因是什么,猜测可能是TPU的没有快捷的办法提取矩阵的某一行/列?
def embedding_lookup(input_ids,
vocab_size,
embedding_size=128,
initializer_range=0.02,
word_embedding_name="word_embeddings",
use_one_hot_embeddings=False):
"""word embedding
Args:
input_ids: int32 Tensor shape为[batch_size, seq_length],表示WordPiece的id
vocab_size: int 词典大小,需要于vocab.txt一致
embedding_size: int embedding后向量的大小
initializer_range: float 随机初始化的范围
word_embedding_name: string 名字,默认是"word_embeddings"
use_one_hot_embeddings: bool 如果True,使用one-hot方法实现embedding;否则使用
`tf.nn.embedding_lookup()`. TPU适合用One hot方法。
Returns:
float Tensor shape为[batch_size, seq_length, embedding_size]
"""
# 这个函数假设输入的shape是[batch_size, seq_length, num_inputs]
# 普通的Embeding一般假设输入是[batch_size, seq_length],
# 增加num_inputs这一维度的目的是为了一次计算更多的Embedding
# 但目前的代码并没有用到,传入的input_ids都是2D的,这增加了代码的阅读难度。
# 如果输入是[batch_size, seq_length],
# 那么我们把它 reshape成[batch_size, seq_length, 1]
if input_ids.shape.ndims == 2:
input_ids = tf.expand_dims(input_ids, axis=[-1])
# 构造Embedding矩阵,shape是[vocab_size, embedding_size]
embedding_table = tf.get_variable(
name=word_embedding_name,
shape=[vocab_size, embedding_size],
initializer=create_initializer(initializer_range))
if use_one_hot_embeddings:
flat_input_ids = tf.reshape(input_ids, [-1])
one_hot_input_ids = tf.one_hot(flat_input_ids, depth=vocab_size)
output = tf.matmul(one_hot_input_ids, embedding_table)
else:
output = tf.nn.embedding_lookup(embedding_table, input_ids)
input_shape = get_shape_list(input_ids)
# 把输出从[batch_size, seq_length, num_inputs(这里总是1), embedding_size]
# 变成[batch_size, seq_length, num_inputs*embedding_size]
output = tf.reshape(output,
input_shape[0:-1] + [input_shape[-1] * embedding_size])
return (output, embedding_table)
Embedding本来很简单,使用tf.nn.embedding_lookup就行了。但是为了优化TPU,它还支持使用矩阵乘法来提取词向量。另外为了提高效率,输入的shape除了[batch_size, seq_length]外,它还增加了一个维度变成[batch_size, seq_length, num_inputs]。如果不关心细节,我们把这个函数当成黑盒,那么我们只需要知道它的输入input_ids(可能)是[8, 128],输出是[8, 128, 768]就可以了。
函数embedding_postprocessor的代码如下,需要注意的部分都有注释。
def embedding_postprocessor(input_tensor,
use_token_type=False,
token_type_ids=None,
token_type_vocab_size=16,
token_type_embedding_name="token_type_embeddings",
use_position_embeddings=True,
position_embedding_name="position_embeddings",
initializer_range=0.02,
max_position_embeddings=512,
dropout_prob=0.1):
"""对word embedding之后的tensor进行后处理
Args:
input_tensor: float Tensor shape为[batch_size, seq_length, embedding_size]
use_token_type: bool 是否增加`token_type_ids`的Embedding
token_type_ids: (可选) int32 Tensor shape为[batch_size, seq_length]
如果`use_token_type`为True则必须有值
token_type_vocab_size: int Token Type的个数,通常是2
token_type_embedding_name: string Token type Embedding的名字
use_position_embeddings: bool 是否使用位置Embedding
position_embedding_name: string,位置embedding的名字
initializer_range: float,初始化范围
max_position_embeddings: int,位置编码的最大长度,可以比最大序列长度大,但是不能比它小。
dropout_prob: float. Dropout 概率
Returns:
float tensor shape和`input_tensor`相同。
"""
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
width = input_shape[2]
if seq_length > max_position_embeddings:
raise ValueError("The seq length (%d) cannot be greater than "
"`max_position_embeddings` (%d)" %
(seq_length, max_position_embeddings))
output = input_tensor
if use_token_type:
if token_type_ids is None:
raise ValueError("`token_type_ids` must be specified if"
"`use_token_type` is True.")
token_type_table = tf.get_variable(
name=token_type_embedding_name,
shape=[token_type_vocab_size, width],
initializer=create_initializer(initializer_range))
# 因为Token Type通常很小(2),所以直接用矩阵乘法(one-hot)更快
flat_token_type_ids = tf.reshape(token_type_ids, [-1])
one_hot_ids = tf.one_hot(flat_token_type_ids, depth=token_type_vocab_size)
token_type_embeddings = tf.matmul(one_hot_ids, token_type_table)
token_type_embeddings = tf.reshape(token_type_embeddings,
[batch_size, seq_length, width])
output += token_type_embeddings
if use_position_embeddings:
full_position_embeddings = tf.get_variable(
name=position_embedding_name,
shape=[max_position_embeddings, width],
initializer=create_initializer(initializer_range))
# 位置Embedding是可以学习的参数,因此我们创建一个[max_position_embeddings, width]的矩阵
# 但实际输入的序列可能并不会到max_position_embeddings(512),为了提高训练速度,
# 我们通过tf.slice取出[0, 1, 2, ..., seq_length-1]的部分,。
if seq_length < max_position_embeddings:
position_embeddings = tf.slice(full_position_embeddings, [0, 0],
[seq_length, -1])
else:
position_embeddings = full_position_embeddings
num_dims = len(output.shape.as_list())
# word embedding之后的tensor是[batch_size, seq_length, width]
# 因为位置编码是与输入内容无关,它的shape总是[seq_length, width]
# 我们无法把位置Embedding加到word embedding上
# 因此我们需要扩展位置编码为[1, seq_length, width]
# 然后就能通过broadcasting加上去了。
position_broadcast_shape = []
for _ in range(num_dims - 2):
position_broadcast_shape.append(1)
position_broadcast_shape.extend([seq_length, width])
# 默认情况下position_broadcast_shape为[1, 128, 768]
position_embeddings = tf.reshape(position_embeddings,
position_broadcast_shape)
# output是[8, 128, 768], position_embeddings是[1, 128, 768]
# 因此可以通过broadcasting相加。
output += position_embeddings
output = layer_norm_and_dropout(output, dropout_prob)
return output
create_attention_mask_from_input_mask函数用于构造Mask矩阵。我们先了解一下它的作用然后再阅读其代码。比如调用它时的两个参数是是:
input_ids=[
[1,2,3,0,0],
[1,3,5,6,1]
]
input_mask=[
[1,1,1,0,0],
[1,1,1,1,1]
]
表示这个batch有两个样本,第一个样本长度为3(padding了2个0),第二个样本长度为5。在计算Self-Attention的时候每一个样本都需要一个Attention Mask矩阵,表示每一个时刻可以attend to的范围,1表示可以attend,0表示是padding的(或者在机器翻译的Decoder中不能attend to未来的词)。对于上面的输入,这个函数返回一个shape是[2, 5, 5]的tensor,分别代表两个Attention Mask矩阵。
[
[1, 1, 1, 0, 0], #它表示第1个词可以attend to 3个词
[1, 1, 1, 0, 0], #它表示第2个词可以attend to 3个词
[1, 1, 1, 0, 0], #它表示第3个词可以attend to 3个词
[1, 1, 1, 0, 0], #无意义,因为输入第4个词是padding的0
[1, 1, 1, 0, 0] #无意义,因为输入第5个词是padding的0
]
[
[1, 1, 1, 1, 1], # 它表示第1个词可以attend to 5个词
[1, 1, 1, 1, 1], # 它表示第2个词可以attend to 5个词
[1, 1, 1, 1, 1], # 它表示第3个词可以attend to 5个词
[1, 1, 1, 1, 1], # 它表示第4个词可以attend to 5个词
[1, 1, 1, 1, 1] # 它表示第5个词可以attend to 5个词
]
了解了它的用途之后下面的代码就很好理解了。
def create_attention_mask_from_input_mask(from_tensor, to_mask):
"""Create 3D attention mask from a 2D tensor mask.
Args:
from_tensor: 2D or 3D Tensor,shape为[batch_size, from_seq_length, ...].
to_mask: int32 Tensor, shape为[batch_size, to_seq_length].
Returns:
float Tensor,shape为[batch_size, from_seq_length, to_seq_length].
"""
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_shape = get_shape_list(to_mask, expected_rank=2)
to_seq_length = to_shape[1]
to_mask = tf.cast(
tf.reshape(to_mask, [batch_size, 1, to_seq_length]), tf.float32)
# `broadcast_ones` = [batch_size, from_seq_length, 1]
broadcast_ones = tf.ones(
shape=[batch_size, from_seq_length, 1], dtype=tf.float32)
# Here we broadcast along two dimensions to create the mask.
mask = broadcast_ones * to_mask
return mask
比如前面举的例子,broadcast_ones的shape是[2, 5, 1],值全是1,而to_mask是
to_mask=[
[1,1,1,0,0],
[1,1,1,1,1]
]
shape是[2, 5],reshape为[2, 1, 5]。然后broadcast_ones * to_mask就得到[2, 5, 5],正是我们需要的两个Mask矩阵,读者可以验证。注意[batch, A, B]*[batch, B, C]=[batch, A, C],我们可以认为是batch个[A, B]的矩阵乘以batch个[B, C]的矩阵。接下来就是transformer_model函数了,它就是构造Transformer的核心代码。
def transformer_model(input_tensor,
attention_mask=None,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
intermediate_act_fn=gelu,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
do_return_all_layers=False):
"""Multi-headed, multi-layer的Transformer,参考"Attention is All You Need".
这基本上是和原始Transformer encoder相同的代码。
原始论文为:
https://arxiv.org/abs/1706.03762
Also see:
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/models/transformer.py
Args:
input_tensor: float Tensor,shape为[batch_size, seq_length, hidden_size]
attention_mask: (可选) int32 Tensor,shape [batch_size, seq_length,
seq_length], 1表示可以attend to,0表示不能。
hidden_size: int. Transformer隐单元个数
num_hidden_layers: int. 有多少个SubLayer
num_attention_heads: int. Transformer Attention Head个数。
intermediate_size: int. 全连接层的隐单元个数
intermediate_act_fn: 函数. 全连接层的激活函数。
hidden_dropout_prob: float. Self-Attention层残差之前的Dropout概率
attention_probs_dropout_prob: float. attention的Dropout概率
initializer_range: float. 初始化范围(truncated normal的标准差)
do_return_all_layers: 返回所有层的输出还是最后一层的输出。
Returns:
如果do_return_all_layers True,返回最后一层的输出,是一个Tensor,
shape为[batch_size, seq_length, hidden_size];
否则返回所有层的输出,是一个长度为num_hidden_layers的list,
list的每一个元素都是[batch_size, seq_length, hidden_size]。
"""
if hidden_size % num_attention_heads != 0:
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention "
"heads (%d)" % (hidden_size, num_attention_heads))
# 因为最终要输出hidden_size,总共有num_attention_heads个Head,因此每个Head输出
# 为hidden_size / num_attention_heads
attention_head_size = int(hidden_size / num_attention_heads)
input_shape = get_shape_list(input_tensor, expected_rank=3)
batch_size = input_shape[0]
seq_length = input_shape[1]
input_width = input_shape[2]
# 因为需要残差连接,我们需要把输入加到Self-Attention的输出,因此要求它们的shape是相同的。
if input_width != hidden_size:
raise ValueError("The width of the input tensor (%d) != hidden size (%d)" %
(input_width, hidden_size))
# 为了避免在2D和3D之间来回reshape,我们统一把所有的3D Tensor用2D来表示。
# 虽然reshape在GPU/CPU上很快,但是在TPU上却不是这样,这样做的目的是为了优化TPU
# input_tensor是[8, 128, 768], prev_output是[8*128, 768]=[1024, 768]
prev_output = reshape_to_matrix(input_tensor)
all_layer_outputs = []
for layer_idx in range(num_hidden_layers):
# 每一层都有自己的variable scope
with tf.variable_scope("layer_%d" % layer_idx):
layer_input = prev_output
# attention层
with tf.variable_scope("attention"):
attention_heads = []
# self attention
with tf.variable_scope("self"):
attention_head = attention_layer(
from_tensor=layer_input,
to_tensor=layer_input,
attention_mask=attention_mask,
num_attention_heads=num_attention_heads,
size_per_head=attention_head_size,
attention_probs_dropout_prob=attention_probs_dropout_prob,
initializer_range=initializer_range,
do_return_2d_tensor=True,
batch_size=batch_size,
from_seq_length=seq_length,
to_seq_length=seq_length)
attention_heads.append(attention_head)
attention_output = None
if len(attention_heads) == 1:
attention_output = attention_heads[0]
else:
# 如果有多个head,那么需要把多个head的输出concat起来
attention_output = tf.concat(attention_heads, axis=-1)
# 使用线性变换把前面的输出变成`hidden_size`,然后再加上`layer_input`(残差连接)
with tf.variable_scope("output"):
attention_output = tf.layers.dense(
attention_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
# dropout
attention_output = dropout(attention_output, hidden_dropout_prob)
# 残差连接再加上layer norm。
attention_output = layer_norm(attention_output + layer_input)
# 全连接层
with tf.variable_scope("intermediate"):
intermediate_output = tf.layers.dense(
attention_output,
intermediate_size,
activation=intermediate_act_fn,
kernel_initializer=create_initializer(initializer_range))
# 然后是用一个线性变换把大小变回`hidden_size`,这样才能加残差连接
with tf.variable_scope("output"):
layer_output = tf.layers.dense(
intermediate_output,
hidden_size,
kernel_initializer=create_initializer(initializer_range))
layer_output = dropout(layer_output, hidden_dropout_prob)
layer_output = layer_norm(layer_output + attention_output)
prev_output = layer_output
all_layer_outputs.append(layer_output)
if do_return_all_layers:
final_outputs = []
for layer_output in all_layer_outputs:
final_output = reshape_from_matrix(layer_output, input_shape)
final_outputs.append(final_output)
return final_outputs
else:
final_output = reshape_from_matrix(prev_output, input_shape)
return final_output
如果对照Transformer的论文,非常容易阅读,里面实现Self-Attention的函数就是attention_layer。
def attention_layer(from_tensor,
to_tensor,
attention_mask=None,
num_attention_heads=1,
size_per_head=512,
query_act=None,
key_act=None,
value_act=None,
attention_probs_dropout_prob=0.0,
initializer_range=0.02,
do_return_2d_tensor=False,
batch_size=None,
from_seq_length=None,
to_seq_length=None):
"""用`from_tensor`(作为Query)去attend to `to_tensor`(提供Key和Value)
这个函数实现论文"Attention
is all you Need"里的multi-head attention。
如果`from_tensor`和`to_tensor`是同一个tensor,那么就实现Self-Attention。
`from_tensor`的每个时刻都会attends to `to_tensor`,
也就是用from的Query去乘以所有to的Key,得到weight,然后把所有to的Value加权求和起来。
这个函数首先把`from_tensor`变换成一个"query" tensor,
然后把`to_tensor`变成"key"和"value" tensors。
总共有`num_attention_heads`组Query、Key和Value,
每一个Query,Key和Value的shape都是[batch_size(8), seq_length(128), size_per_head(512/8=64)].
然后计算query和key的内积并且除以size_per_head的平方根(8)。
然后softmax变成概率,最后用概率加权value得到输出。
因为有多个Head,每个Head都输出[batch_size, seq_length, size_per_head],
最后把8个Head的结果concat起来,就最终得到[batch_size(8), seq_length(128), size_per_head*8=512]
实际上我们是把这8个Head的Query,Key和Value都放在一个Tensor里面的,
因此实际通过transpose和reshape就达到了上面的效果。
Args:
from_tensor: float Tensor,shape [batch_size, from_seq_length, from_width]
to_tensor: float Tensor,shape [batch_size, to_seq_length, to_width].
attention_mask: (可选) int32 Tensor, shape[batch_size,from_seq_length,to_seq_length]。
值可以是0或者1,在计算attention score的时候,
我们会把0变成负无穷(实际是一个绝对值很大的负数),而1不变,
这样softmax的时候进行exp的计算,前者就趋近于零,从而间接实现Mask的功能。
num_attention_heads: int. Attention heads的数量。
size_per_head: int. 每个head的size
query_act: (可选) query变换的激活函数
key_act: (可选) key变换的激活函数
value_act: (可选) value变换的激活函数
attention_probs_dropout_prob: (可选) float. attention的Dropout概率。
initializer_range: float. 初始化范围
do_return_2d_tensor: bool. 如果True,返回2D的Tensor其shape是
[batch_size * from_seq_length, num_attention_heads * size_per_head];
否则返回3D的Tensor其shape为[batch_size, from_seq_length,
num_attention_heads * size_per_head].
batch_size: (可选) int. 如果输入是3D的,那么batch就是第一维,
但是可能3D的压缩成了2D的,所以需要告诉函数batch_size
from_seq_length: (可选) 同上,需要告诉函数from_seq_length
to_seq_length: (可选) 同上,to_seq_length
Returns:
float Tensor,shape [batch_size,from_seq_length,num_attention_heads * size_per_head]。
如果`do_return_2d_tensor`为True,则返回的shape是
[batch_size * from_seq_length, num_attention_heads * size_per_head].
"""
def transpose_for_scores(input_tensor, batch_size, num_attention_heads,
seq_length, width):
output_tensor = tf.reshape(
input_tensor, [batch_size, seq_length, num_attention_heads, width])
output_tensor = tf.transpose(output_tensor, [0, 2, 1, 3])
return output_tensor
from_shape = get_shape_list(from_tensor, expected_rank=[2, 3])
to_shape = get_shape_list(to_tensor, expected_rank=[2, 3])
if len(from_shape) != len(to_shape):
raise ValueError(
"The rank of `from_tensor` must match the rank of `to_tensor`.")
# 如果输入是3D的(没有压缩),那么我们可以推测出batch_size、from_seq_length和to_seq_length
# 即使参数传入也会被覆盖。
if len(from_shape) == 3:
batch_size = from_shape[0]
from_seq_length = from_shape[1]
to_seq_length = to_shape[1]
# 如果是压缩成2D的,那么一定要传入这3个参数,否则抛异常。
elif len(from_shape) == 2:
if (batch_size is None or from_seq_length is None or to_seq_length is None):
raise ValueError(
"When passing in rank 2 tensors to attention_layer, the values "
"for `batch_size`, `from_seq_length`, and `to_seq_length` "
"must all be specified.")
# B = batch size (number of sequences) 默认配置是8
# F = `from_tensor` sequence length 默认配置是128
# T = `to_tensor` sequence length 默认配置是128
# N = `num_attention_heads` 默认配置是12
# H = `size_per_head` 默认配置是64
# 把from和to压缩成2D的。
# [8*128, 768]
from_tensor_2d = reshape_to_matrix(from_tensor)
# [8*128, 768]
to_tensor_2d = reshape_to_matrix(to_tensor)
# 计算Query `query_layer` = [B*F, N*H] =[8*128, 12*64]
# batch_size=8,共128个时刻,12和head,每个head的query向量是64
# 因此最终得到[8*128, 12*64]
query_layer = tf.layers.dense(
from_tensor_2d,
num_attention_heads * size_per_head,
activation=query_act,
name="query",
kernel_initializer=create_initializer(initializer_range))
# 和query类似,`key_layer` = [B*T, N*H]
key_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=key_act,
name="key",
kernel_initializer=create_initializer(initializer_range))
# 同上,`value_layer` = [B*T, N*H]
value_layer = tf.layers.dense(
to_tensor_2d,
num_attention_heads * size_per_head,
activation=value_act,
name="value",
kernel_initializer=create_initializer(initializer_range))
# 把query从[B*F, N*H] =[8*128, 12*64]变成[B, N, F, H]=[8, 12, 128, 64]
query_layer = transpose_for_scores(query_layer, batch_size,
num_attention_heads, from_seq_length,
size_per_head)
# 同上,key也变成[8, 12, 128, 64]
key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads,
to_seq_length, size_per_head)
# 计算query和key的内积,得到attention scores.
# [8, 12, 128, 64]*[8, 12, 64, 128]=[8, 12, 128, 128]
# 最后两维[128, 128]表示from的128个时刻attend to到to的128个score。
# `attention_scores` = [B, N, F, T]
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
attention_scores = tf.multiply(attention_scores,
1.0 / math.sqrt(float(size_per_head)))
if attention_mask is not None:
# 从[8, 128, 128]变成[8, 1, 128, 128]
# `attention_mask` = [B, 1, F, T]
attention_mask = tf.expand_dims(attention_mask, axis=[1])
# 这个小技巧前面也用到过,如果mask是1,那么(1-1)*-10000=0,adder就是0,
# 如果mask是0,那么(1-0)*-10000=-10000。
adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0
# 我们把adder加到attention_score里,mask是1就相当于加0,mask是0就相当于加-10000。
# 通常attention_score都不会很大,因此mask为0就相当于把attention_score设置为负无穷
# 后面softmax的时候就趋近于0,因此相当于不能attend to Mask为0的地方。
attention_scores += adder
# softmax
# `attention_probs` = [B, N, F, T] =[8, 12, 128, 128]
attention_probs = tf.nn.softmax(attention_scores)
# 对attention_probs进行dropout,这虽然有点奇怪,但是Transformer的原始论文就是这么干的。
attention_probs = dropout(attention_probs, attention_probs_dropout_prob)
# 把`value_layer` reshape成[B, T, N, H]=[8, 128, 12, 64]
value_layer = tf.reshape(
value_layer,
[batch_size, to_seq_length, num_attention_heads, size_per_head])
# `value_layer`变成[B, N, T, H]=[8, 12, 128, 64]
value_layer = tf.transpose(value_layer, [0, 2, 1, 3])
# 计算`context_layer` = [8, 12, 128, 128]*[8, 12, 128, 64]=[8, 12, 128, 64]=[B, N, F, H]
context_layer = tf.matmul(attention_probs, value_layer)
# `context_layer` 变换成 [B, F, N, H]=[8, 128, 12, 64]
context_layer = tf.transpose(context_layer, [0, 2, 1, 3])
if do_return_2d_tensor:
# `context_layer` = [B*F, N*V]
context_layer = tf.reshape(
context_layer,
[batch_size * from_seq_length, num_attention_heads * size_per_head])
else:
# `context_layer` = [B, F, N*V]
context_layer = tf.reshape(
context_layer,
[batch_size, from_seq_length, num_attention_heads * size_per_head])
return context_layer
九、自己进行Pretraining
虽然Google提供了Pretraining的模型,但是我们可以也会需要自己通过Mask LM和Next Sentence Prediction进行Pretraining。当然如果我们数据和计算资源都足够多,那么我们可以从头开始Pretraining,如果我们有一些领域的数据,那么我们也可以进行Pretraining,但是可以用Google提供的checkpoint作为初始值。
要进行Pretraining首先需要有数据,前面讲过,数据由很多”文档”组成,每篇文档的句子之间是有关系的。如果只能拿到没有关系的句子则是无法训练的。我们的训练数据需要变成如下的格式:
~/codes/bert$ cat sample_text.txt
This text is included to make sure Unicode is handled properly: 力加勝北区ᴵᴺᵀᵃছজটডণত
Text should be one-sentence-per-line, with empty lines between documents.
This sample text is public domain and was randomly selected from Project Guttenberg.
The rain had only ceased with the gray streaks of morning at Blazing Star, and the settlement awoke to a moral sense of cleanliness, and the finding of forgotten knives, tin cups, and smaller camp utensils, where the heavy showers had washed away the debris and dust heaps before the cabin doors.
Indeed, it was recorded in Blazing Star that a fortunate early riser had once picked up on the highway a solid chunk of gold quartz which the rain had freed from its incumbering soil, and washed into immediate and glittering popularity.
Possibly this may have been the reason why early risers in that locality, during the rainy season, adopted a thoughtful habit of body, and seldom lifted their eyes to the rifted or india-ink washed skies above them.
"Cass" Beard had risen early that morning, but not with a view to discovery.
...省略了很多行
数据是文本文件,每一行表示一个句子,空行表示一个文档的结束(新文档的开始),比如上面的例子,总共有2个文档,第一个文档只有3个句子,第二个文档有很多句子。
我们首先需要使用create_pretraining_data.py把文本文件变成TFRecord格式,便于后面的代码进行Pretraining。由于这个脚本会把整个文本文件加载到内存,因此这个文件不能太大。如果读者有很多文档要训练,比如1000万。那么我们可以把这1000万文档拆分成1万个文件,每个文件1000个文档,从而生成1000个TFRecord文件。
我们先看create_pretraining_data.py的用法:
python create_pretraining_data.py --input_file=./sample_text.txt --output_file=./imdb/tf_examples.tfrecord --vocab_file=./vocab.txt --do_lower_case=True --max_seq_length=128 --max_predictions_per_seq=20 --masked_lm_prob=0.15 --random_seed=12345 --dupe_factor=5- max_seq_length Token序列的最大长度
- max_predictions_per_seq 最多生成多少个MASK
- masked_lm_prob 多少比例的Token变成MASK
- dupe_factor 一个文档重复多少次
首先说一下参数dupe_factor,比如一个句子”it is a good day”,为了充分利用数据,我们可以多次随机的生成MASK,比如第一次可能生成”it is a [MASK] day”,第二次可能生成”it [MASK] a good day”。这个参数控制重复的次数。
masked_lm_prob就是论文里的参数15%。max_predictions_per_seq是一个序列最多MASK多少个Token,它通常等于max_seq_length * masked_lm_prob。这么看起来这个参数没有必要提供,但是后面的脚本也需要用到这个同样的值,而后面的脚本并没有这两个参数。
我们先看main函数。
def main(_):
tokenizer = tokenization.FullTokenizer(
vocab_file=FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case)
input_files = []
# 省略了文件通配符的处理,我们假设输入的文件已经传入input_files
rng = random.Random(FLAGS.random_seed)
instances = create_training_instances(
input_files, tokenizer, FLAGS.max_seq_length, FLAGS.dupe_factor,
FLAGS.short_seq_prob, FLAGS.masked_lm_prob, FLAGS.max_predictions_per_seq,
rng)
output_files = ....
write_instance_to_example_files(instances, tokenizer, FLAGS.max_seq_length,
FLAGS.max_predictions_per_seq, output_files)
main函数很简单,输入文本文件列表是input_files,通过函数create_training_instances构建训练的instances,然后调用write_instance_to_example_files以TFRecord格式写到output_files。
我们先来看一个训练样本的格式,这是用类TrainingInstance来表示的:
class TrainingInstance(object):
def __init__(self, tokens, segment_ids, masked_lm_positions, masked_lm_labels,
is_random_next):
self.tokens = tokens
self.segment_ids = segment_ids
self.is_random_next = is_random_next
self.masked_lm_positions = masked_lm_positions
self.masked_lm_labels = masked_lm_labels
假设原始两个句子为:”it is a good day”和”I want to go out”,那么处理后的TrainingInstance可能为:
1. tokens = ["[CLS], "it", "is" "a", "[MASK]", "day", "[SEP]", "I", "apple", "to", "go", "out", "[SEP]"]
2. segment_ids=[0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1]
3. is_random_next=False
4. masked_lm_positions=[4, 8, 9]
表示Mask后为["[CLS], "it", "is" "a", "[MASK]", "day", "[SEP]", "I", "[MASK]", "to", "go", "out", "[SEP]"]
5. masked_lm_labels=["good", "want", "to"]
is_random_next表示这两句话是有关联的,预测句子关系的分类器应该把这个输入判断为1。masked_lm_positions记录哪些位置被Mask了,而masked_lm_labels记录被Mask之前的词。
注意:tokens已经处理过了,good被替换成[MASK],而want被替换成apple,而to还是被替换成它自己,原因前面的理论部分已经介绍过了。因此根据masked_lm_positions、masked_lm_labels和tokens是可以恢复出原始(分词后的)句子的。
create_training_instances函数的代码为:
def create_training_instances(input_files, tokenizer, max_seq_length,
dupe_factor, short_seq_prob, masked_lm_prob,
max_predictions_per_seq, rng):
"""从原始文本创建`TrainingInstance`"""
all_documents = [[]]
# 输入文件格式:
# (1) 每行一个句子。这应该是实际的句子,不应该是整个段落或者段落的随机片段(span),因为我们需
# 要使用句子边界来做下一个句子的预测。
# (2) 文档之间有一个空行。我们会认为同一个文档的相邻句子是有关系的。
# 下面的代码读取所有文件,然后根据空行切分Document
# all_documents是list的list,第一层list表示document,第二层list表示document里的多个句子。
for input_file in input_files:
with tf.gfile.GFile(input_file, "r") as reader:
while True:
line = tokenization.convert_to_unicode(reader.readline())
if not line:
break
line = line.strip()
# 空行表示旧文档的结束和新文档的开始。
if not line:
#添加一个新的空文档
all_documents.append([])
tokens = tokenizer.tokenize(line)
if tokens:
all_documents[-1].append(tokens)
# 删除空文档
all_documents = [x for x in all_documents if x]
rng.shuffle(all_documents)
vocab_words = list(tokenizer.vocab.keys())
instances = []
# 重复dup_factor次
for _ in range(dupe_factor):
# 遍历所有文档
for document_index in range(len(all_documents)):
# 从一个文档(下标为document_index)里抽取多个TrainingInstance
instances.extend(create_instances_from_document(
all_documents, document_index, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng))
rng.shuffle(instances)
return instances
上面的函数会调用create_instances_from_document来从一个文档里抽取多个训练数据(TrainingInstance)。普通的语言模型只要求连续的字符串就行,通常是把所有的文本(比如维基百科的内容)拼接成一个很大很大的文本文件,然后训练的时候随机的从里面抽取固定长度的字符串作为一个”句子”。但是BERT要求我们的输入是一个一个的Document,每个Document有很多句子,这些句子是连贯的真实的句子,需要正确的分句,而不能随机的(比如按照固定长度)切分句子。代码如下:
def create_instances_from_document(
all_documents, document_index, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng):
"""从一个文档里创建多个`TrainingInstance`。"""
document = all_documents[document_index]
# 为[CLS], [SEP], [SEP]预留3个位置。
max_num_tokens = max_seq_length - 3
# 我们通常希望Token序列长度为最大的max_seq_length,否则padding后的计算是无意义的,浪费计
# 算资源。但是有的时候我们有希望生成一些短的句子,因为在实际应用中会有短句,如果都是
# 长句子,那么就很容易出现Mismatch,所有我们以short_seq_prob == 0.1 == 10%的概率生成
# 短句子。
target_seq_length = max_num_tokens
# 以0.1的概率生成随机(2-max_num_tokens)的长度。
if rng.random() < short_seq_prob:
target_seq_length = rng.randint(2, max_num_tokens)
# 我们不能把一个文档的所有句子的Token拼接起来,然后随机的选择两个片段。
# 因为这样很可能这两个片段是同一个句子(至少很可能第二个片段的开头和第一个片段的结尾是同一个
# 句子),这样预测是否相关句子的任务太简单,学习不到深层的语义关系。
# 这里我们使用"真实"的句子边界。
instances = []
current_chunk = []
current_length = 0
i = 0
while i < len(document):
segment = document[i]
current_chunk.append(segment)
current_length += len(segment)
if i == len(document) - 1 or current_length >= target_seq_length:
if current_chunk:
# `a_end`是第一个句子A(在current_chunk里)结束的下标
a_end = 1
# 随机选择切分边界
if len(current_chunk) >= 2:
a_end = rng.randint(1, len(current_chunk) - 1)
tokens_a = []
for j in range(a_end):
tokens_a.extend(current_chunk[j])
tokens_b = []
# 是否Random next
is_random_next = False
if len(current_chunk) == 1 or rng.random() < 0.5:
is_random_next = True
target_b_length = target_seq_length - len(tokens_a)
# 随机的挑选另外一篇文档的随机开始的句子
# 但是理论上有可能随机到的文档就是当前文档,因此需要一个while循环
# 这里只while循环10次,理论上还是有重复的可能性,但是我们忽略
for _ in range(10):
random_document_index = rng.randint(0, len(all_documents) - 1)
# 不是当前文档,则找到了random_document_index
if random_document_index != document_index:
break
# 随机挑选的文档
random_document = all_documents[random_document_index]
# 随机选择开始句子
random_start = rng.randint(0, len(random_document) - 1)
# 把Token加到tokens_b里,如果Token数量够了(target_b_length)就break。
for j in range(random_start, len(random_document)):
tokens_b.extend(random_document[j])
if len(tokens_b) >= target_b_length:
break
# 之前我们虽然挑选了len(current_chunk)个句子,但是a_end之后的句子替换成随机的其它
# 文档的句子,因此我们并没有使用a_end之后的句子,因此我们修改下标i,使得下一次循环
# 可以再次使用这些句子(把它们加到新的chunk里),避免浪费。
num_unused_segments = len(current_chunk) - a_end
i -= num_unused_segments
# 真实的下一句
else:
is_random_next = False
for j in range(a_end, len(current_chunk)):
tokens_b.extend(current_chunk[j])
# 如果太多了,随机去掉一些。
truncate_seq_pair(tokens_a, tokens_b, max_num_tokens, rng)
tokens = []
segment_ids = []
# 处理句子A
tokens.append("[CLS]")
segment_ids.append(0)
for token in tokens_a:
tokens.append(token)
segment_ids.append(0)
# A的结束
tokens.append("[SEP]")
segment_ids.append(0)
# 处理句子B
for token in tokens_b:
tokens.append(token)
segment_ids.append(1)
# B的结束
tokens.append("[SEP]")
segment_ids.append(1)
(tokens, masked_lm_positions,masked_lm_labels) = create_masked_lm_predictions(
tokens, masked_lm_prob, max_predictions_per_seq, vocab_words, rng)
instance = TrainingInstance(
tokens=tokens,
segment_ids=segment_ids,
is_random_next=is_random_next,
masked_lm_positions=masked_lm_positions,
masked_lm_labels=masked_lm_labels)
instances.append(instance)
current_chunk = []
current_length = 0
i += 1
return instances
代码有点长,但是逻辑很简单,比如有一篇文档有n个句子:
w11,w12,.....,
w21,w22,....
wn1,wn2,....
那么算法首先找到一个chunk,它会不断往chunk加入一个句子的所有Token,使得chunk里的token数量大于等于target_seq_length。通常我们期望target_seq_length为max_num_tokens(128-3),这样padding的尽量少,训练的效率高。但是有时候我们也需要生成一些短的序列,否则会出现训练与实际使用不匹配的问题。
找到一个chunk之后,比如这个chunk有5个句子,那么我们随机的选择一个切分点,比如3。把前3个句子当成句子A,后两个句子当成句子B。这是两个句子A和B有关系的样本(is_random_next=False)。为了生成无关系的样本,我们还以50%的概率把B用随机从其它文档抽取的句子替换掉,这样就得到无关系的样本(is_random_next=True)。如果是这种情况,后面两个句子需要放回去,以便在下一层循环中能够被再次利用。
有了句子A和B之后,我们就可以填充tokens和segment_ids,这里会加入特殊的[CLS]和[SEP]。接下来使用create_masked_lm_predictions来随机的选择某些Token,把它变成[MASK]。其代码为:
def create_masked_lm_predictions(tokens, masked_lm_prob,
max_predictions_per_seq, vocab_words, rng):
# 首先找到可以被替换的下标,[CLS]和[SEP]是不能用于MASK的。
cand_indexes = []
for (i, token) in enumerate(tokens):
if token == "[CLS]" or token == "[SEP]":
continue
cand_indexes.append(i)
# 随机打散
rng.shuffle(cand_indexes)
output_tokens = list(tokens)
# 构造一个namedtuple,包括index和label两个属性。
masked_lm = collections.namedtuple("masked_lm", ["index", "label"])
# 需要被模型预测的Token个数:min(max_predictions_per_seq(20),实际Token数*15%)
num_to_predict = min(max_predictions_per_seq,
max(1, int(round(len(tokens) * masked_lm_prob))))
masked_lms = []
covered_indexes = set()
# 随机的挑选num_to_predict个需要预测的Token
# 因为cand_indexes打散过,因此顺序的取就行
for index in cand_indexes:
# 够了
if len(masked_lms) >= num_to_predict:
break
# 已经挑选过了?似乎没有必要判断,因为set会去重。
if index in covered_indexes:
continue
covered_indexes.add(index)
masked_token = None
# 80%的概率把它替换成[MASK]
if rng.random() < 0.8:
masked_token = "[MASK]"
else:
# 10%的概率保持不变
if rng.random() < 0.5:
masked_token = tokens[index]
# 10%的概率随机替换成词典里的一个词。
else:
masked_token = vocab_words[rng.randint(0, len(vocab_words) - 1)]
output_tokens[index] = masked_token
masked_lms.append(masked_lm(index=index, label=tokens[index]))
# 按照下标排序,保证是句子中出现的顺序。
masked_lms = sorted(masked_lms, key=lambda x: x.index)
masked_lm_positions = []
masked_lm_labels = []
for p in masked_lms:
masked_lm_positions.append(p.index)
masked_lm_labels.append(p.label)
return (output_tokens, masked_lm_positions, masked_lm_labels)
最后是使用函数write_instance_to_example_files把前面得到的TrainingInstance用TFRecord的个数写到文件里,这个函数的核心代码是:
def write_instance_to_example_files(instances, tokenizer, max_seq_length,
max_predictions_per_seq, output_files):
features = collections.OrderedDict()
features["input_ids"] = create_int_feature(input_ids)
features["input_mask"] = create_int_feature(input_mask)
features["segment_ids"] = create_int_feature(segment_ids)
features["masked_lm_positions"] = create_int_feature(masked_lm_positions)
features["masked_lm_ids"] = create_int_feature(masked_lm_ids)
features["masked_lm_weights"] = create_float_feature(masked_lm_weights)
features["next_sentence_labels"] = create_int_feature([next_sentence_label])
tf_example = tf.train.Example(features=tf.train.Features(feature=features))
writers[writer_index].write(tf_example.SerializeToString())
接下来我们使用run_pretraining.py脚本进行Pretraining。用法为:
python run_pretraining.py \
--input_file=/tmp/tf_examples.tfrecord \
--output_dir=/tmp/pretraining_output \
--do_train=True \
--do_eval=True \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--train_batch_size=32 \
--max_seq_length=128 \
--max_predictions_per_seq=20 \
--num_train_steps=20 \
--num_warmup_steps=10 \
--learning_rate=2e-5
参数都比较容易理解,通常我们需要调整的是num_train_steps、num_warmup_steps和learning_rate。run_pretraining.py的代码和run_classifier.py很类似,都是用BertModel构建Transformer模型,唯一的区别在于损失函数不同:
def model_fn(features, labels, mode, params):
input_ids = features["input_ids"]
input_mask = features["input_mask"]
segment_ids = features["segment_ids"]
masked_lm_positions = features["masked_lm_positions"]
masked_lm_ids = features["masked_lm_ids"]
masked_lm_weights = features["masked_lm_weights"]
next_sentence_labels = features["next_sentence_labels"]
is_training = (mode == tf.estimator.ModeKeys.TRAIN)
model = modeling.BertModel(
config=bert_config,
is_training=is_training,
input_ids=input_ids,
input_mask=input_mask,
token_type_ids=segment_ids,
use_one_hot_embeddings=use_one_hot_embeddings)
(masked_lm_loss,
masked_lm_example_loss, masked_lm_log_probs) = get_masked_lm_output(
bert_config, model.get_sequence_output(), model.get_embedding_table(),
masked_lm_positions, masked_lm_ids, masked_lm_weights)
(next_sentence_loss, next_sentence_example_loss,
next_sentence_log_probs) = get_next_sentence_output(
bert_config, model.get_pooled_output(), next_sentence_labels)
total_loss = masked_lm_loss + next_sentence_loss
get_masked_lm_output函数用于计算语言模型的Loss(Mask位置预测的词和真实的词是否相同)。
def get_masked_lm_output(bert_config, input_tensor, output_weights, positions,
label_ids, label_weights):
"""得到masked LM的loss和log概率"""
# 只需要Mask位置的Token的输出。
input_tensor = gather_indexes(input_tensor, positions)
with tf.variable_scope("cls/predictions"):
# 在输出之前再加一个非线性变换,这些参数只是用于训练,在Fine-Tuning的时候就不用了。
with tf.variable_scope("transform"):
input_tensor = tf.layers.dense(
input_tensor,
units=bert_config.hidden_size,
activation=modeling.get_activation(bert_config.hidden_act),
kernel_initializer=modeling.create_initializer(
bert_config.initializer_range))
input_tensor = modeling.layer_norm(input_tensor)
# output_weights是复用输入的word Embedding,所以是传入的,
# 这里再多加一个bias。
output_bias = tf.get_variable(
"output_bias",
shape=[bert_config.vocab_size],
initializer=tf.zeros_initializer())
logits = tf.matmul(input_tensor, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
log_probs = tf.nn.log_softmax(logits, axis=-1)
# label_ids的长度是20,表示最大的MASK的Token数
# label_ids里存放的是MASK过的Token的id
label_ids = tf.reshape(label_ids, [-1])
label_weights = tf.reshape(label_weights, [-1])
one_hot_labels = tf.one_hot(
label_ids, depth=bert_config.vocab_size, dtype=tf.float32)
# 但是由于实际MASK的可能不到20,比如只MASK18,那么label_ids有2个0(padding)
# 而label_weights=[1, 1, ...., 0, 0],说明后面两个label_id是padding的,计算loss要去掉。
per_example_loss = -tf.reduce_sum(log_probs * one_hot_labels, axis=[-1])
numerator = tf.reduce_sum(label_weights * per_example_loss)
denominator = tf.reduce_sum(label_weights) + 1e-5
loss = numerator / denominator
return (loss, per_example_loss, log_probs)
get_next_sentence_output函数用于计算预测下一个句子的loss,代码为:
def get_next_sentence_output(bert_config, input_tensor, labels):
"""预测下一个句子是否相关的loss和log概率"""
# 简单的2分类,0表示真的下一个句子,1表示随机的。这个分类器的参数在实际的Fine-Tuning
# 会丢弃掉。
with tf.variable_scope("cls/seq_relationship"):
output_weights = tf.get_variable(
"output_weights",
shape=[2, bert_config.hidden_size],
initializer=modeling.create_initializer(bert_config.initializer_range))
output_bias = tf.get_variable(
"output_bias", shape=[2], initializer=tf.zeros_initializer())
logits = tf.matmul(input_tensor, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
log_probs = tf.nn.log_softmax(logits, axis=-1)
labels = tf.reshape(labels, [-1])
one_hot_labels = tf.one_hot(labels, depth=2, dtype=tf.float32)
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)
loss = tf.reduce_mean(per_example_loss)
return (loss, per_example_loss, log_probs)十、性能测试
本节主要对BERT在工业部署情况的性能测评。性能测试部分主要参考肖涵大神的本篇文章(github上bert-as-service的作者)。因个人硬件配置有限,后续有机会再进行测试补充。
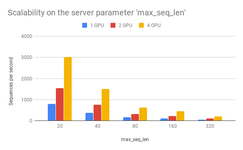
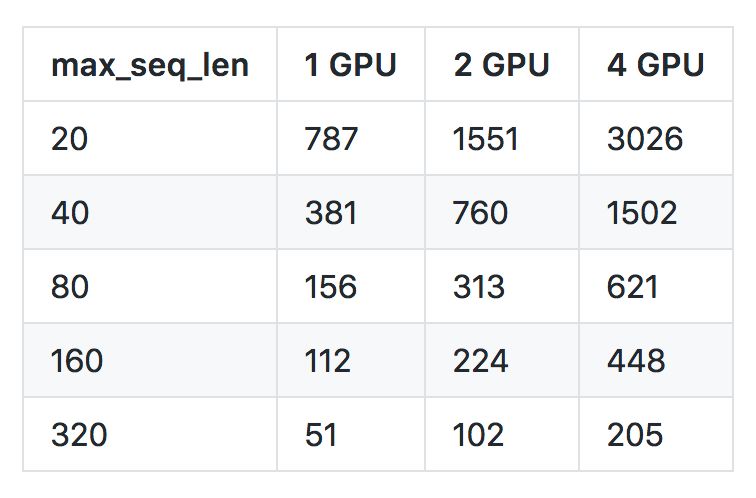
(一)关于max_seq_len对速度的影响
从性能上来讲,过大的max_seq_len 会拖慢计算速度,并很有可能造成内存 OOM。
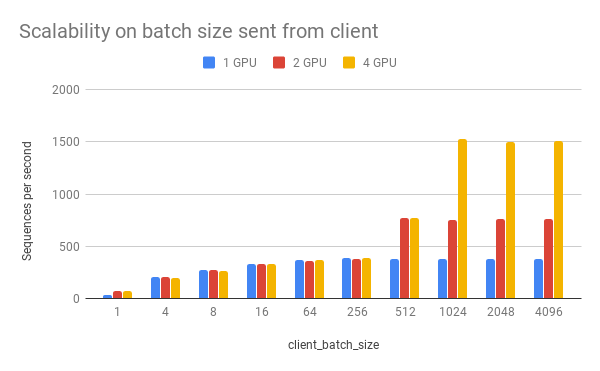
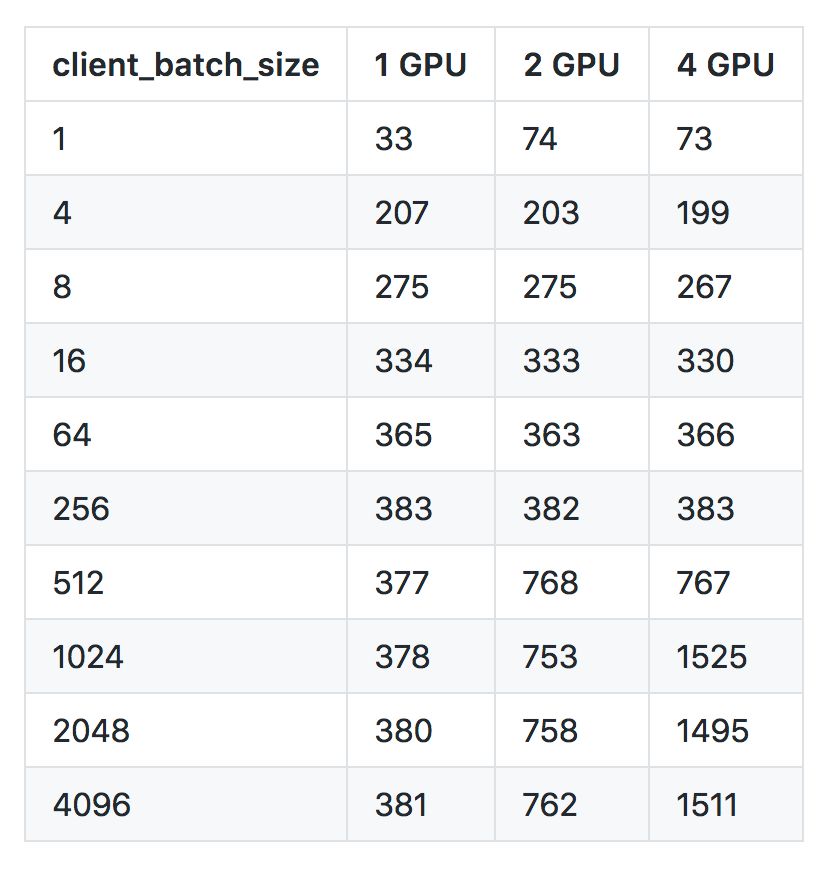
(二)client_batch_size对速度的影响
出于性能考虑,请尽可能每次传入较多的句子而非一次只传一个。比如,使用下列方法调用:
# prepare your sent in advance
bc = BertClient()
my_sentences = [s for s in my_corpus.iter()]
# doing encoding in one-shot
vec = bc.encode(my_sentences)
而不要使用:
bc = BertClient()
vec = []
for s in my_corpus.iter():
vec.append(bc.encode(s))
如果把 bc = BertClient() 放在了循环之内,则性能会更差。
当然在一些时候,一次仅传入一个句子无法避免,尤其是在小流量在线环境中。
(三)num_client 对并发性和速度的影响
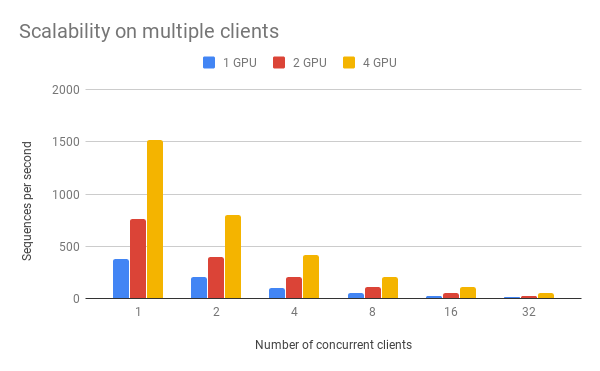

可以看到一个客户端、一块 GPU 的处理速度是每秒 381 个句子(句子的长度为 40),两个客户端、两个 GPU 是每秒 402 个,四个客户端、四个 GPU 的速度是每秒 413 个。当 GPU 的数量增多时,服务对每个客户端请求的处理速度保持稳定甚至略有增高(因为空隙时刻被更有效地利用)。

















 1161
1161












 到【灌水乐园】发言
到【灌水乐园】发言







