








论文:TinyLLaVA: A Framework of Small-scale Large Multimodal Models
代码:https://github.com/TinyLLaVA/TinyLLaVA_Factory
贡献:
- 证明了使用小型 LLM 的情况下,只要模块组合方式和训练数据质量高,也能取得和大型 LLM 相当的效果
- 最好的 TinyLLaVA-3.1B (TinyLLaVA-share-Sig-Phi) 能够取得和 LLaVA-1.5、QWen-VL 等 7b 大小的模型相当的效果
一、背景
虽然不断扩大模型的容量能够提升模型对很多不同任务的解决能力,但训练庞大的模型需要很多的资源,如 Flamingo 为 80b,PaLM-E 为 562b,所以现在有很多 LLM 的模型也在降低模型参数量,降低到 7B 或 3B,但性能没有下降很多
所以 LMM 也出现了类似的方向,如 OpenFlamingo 和 LLaVA 所做的模型是从 3b 到 15b,这样也能提升模型的效率和可部署性
基于此,本文作者提出了 TinyLLaVA:
- 一个利用小型 LLM 实现大型 LMM 的模型框架,框架由视觉编码器、小型 LLM 解码器和中间连接器组成
- 作者探究了不同的 vision encoder、connector、language model、training data、train recipes 组合起来的效果
- 证明了通过更好的训练组合方式和更高质量的数据,使用较小的 LMM 就能实现较大模型相当的性能
- 小型 LLM:Phi-2 [33], StableLM-2 [47], and TinyLlama [59]
- vision encoder: CLIP [44], and SigLIP [58]
- 最好的 TinyLLaVA-3.1B 能够取得和 LLaVA-1.5、QWen-VL 等 7b 大小的模型相当的效果
小型的 LLM 模型:
- Phi-2
- TinyLlama
- StableLM-2
一些大型的 LMM 模型:
- Flamingo
- BLIP
- LLava
- InstructBLIP
一些小型的 LMM 模型:
- TinyGPT-V:使用 Phi
- LLava-Phi:使用 LLaVA-1.5 的结构,将 LLM 换成了 Phi-2
- MoE-LLaVA:给 LLaVA 引入了 Mixture-ofExperts [23] ,使用更少的参数量取得了和 LLaVA-1.5 相当的性能
本文作者会详细的分析如何选择模型、训练策略、数据等方面,从而构建一个高水准的小型 LMM
二、方法
TinyLLaVA 的结构是根据 LLaVA 衍生而来的
2.1 模型结构
模型结构如图 2 所示,由下面几个部分组成:
- small-scale LLM
- vision encoder
- connector
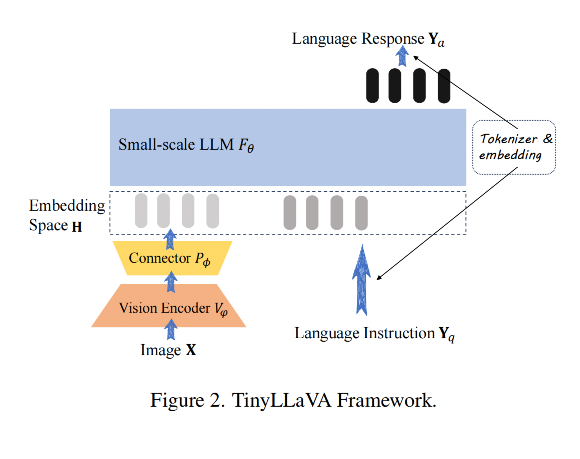
1、small-scale LLM
small-scale LLM 的输入是一系列的向量 { h i } i = 0 N − 1 \{h_i\}_{i=0}^{N-1} {hi}i=0N−1,该向量是长度为 N 且维度为 d 的 text embedding,输出是下一个预测结果 { h i } i = 1 N \{h_i\}_{i=1}^{N} {hi}i=1N
一般 LLM 模型会绑定一个 tokenizer,用于将 input sequence { y i } i = 0 N − 1 \{y_i\}_{i=0}^{N-1} {yi}i=0N−1 映射到 embedding space
2、Vision encoder
vision encoder 的输入是 image X,输出是一系列 visual patch features
3、Connector
连接器的作用是将 visual patch 特征映射到 text embedding 空间,将图像特征和文本特征连接起来
2.2 训练 pipeline
训练的数据是 image-text pairs ( X , Y ) (X, Y) (X,Y),训练分为预训练和微调两个阶段
text sequence Y 是由一系列多轮对话组成,即 Y = Y q 1 , Y a 1 , . . . , Y q T , Y a T Y={Y_q^1, Y_a^1, ... , Y_q^T, Y_a^T} Y=Yq1,Ya1,...,YqT,YaT:
- 其中 T 是总共的轮数
- Y q T Y_q^T YqT 是人类指令
- Y a T Y_a^T YaT 是机器响应
1、预训练来实现特征对齐
本阶段的目标是为了在 embedding 空间更好的对齐 vision 和 text information
训练使用的是 image-caption 形式的数据,即 ( X , Y a ) (X, Y_a) (X,Ya),X 是图像,Y 是 caption 描述
给定目标响应 Y a = { y i } i = 1 N a Y_a=\{y_i\}_{i=1}^{N_a} Ya={yi}i=1Na,其中 N a N_a Na 是 length,作者通过下面的方式来计算生成 Y a Y_a Ya 的概率:
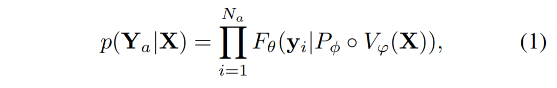
目标函数就变成了最大化上述概率的 log 似然:
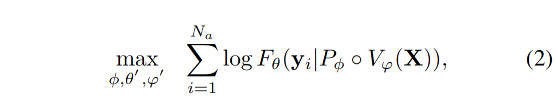
注意:作者在预训练的时候也会让 LLM 和 vision encoder 的部分参数参与训练,因为考虑到使用小型的 LLM 如果只训练 connector 的话可能训练不好
2、有监督微调
使用图像-文本对(X, Y)进行多轮对话的原始形式。
A 表示属于 assistant responses 的所有 token 集合, A = { y ∣ y ∈ Y a t , f o r a n y t = 1, ..., T } A = \{y | y ∈ Y_a^t, for\ any\ \text{t = 1, ..., T}\} A={y∣y∈Yat,for any t = 1, ..., T}, Y a t Y_a^t Yat 表示在多轮对话中第 t 轮中助手的响应。A 是一个集合,包含了所有属于助手响应的标记,即从每一轮对话中提取出的助手生成的所有标记。
假设有一个多轮对话,共有三轮(T = 3),每一轮对话中助手的响应分别如下:
- 第一轮(t=1):助手响应 “Hello, how can I help you?” 对应的标记集合可能是 {“Hello”, “,”, “how”, “can”, “I”, “help”, “you”, “?”}
- 第二轮(t=2):助手响应 “Sure, I can do that.” 对应的标记集合可能是 {“Sure”, “,”, “I”, “can”, “do”, “that”, “.”}
- 第三轮(t=3):助手响应 “Please wait a moment.” 对应的标记集合可能是 {“Please”, “wait”, “a”, “moment”, “.”}
那么,集合 A 将包含所有这些标记,即:
A = {“Hello”, “,”, “how”, “can”, “I”, “help”, “you”, “?”,
“Sure”, “,”, “I”, “can”, “do”, “that”, “.”,
“Please”, “wait”, “a”, “moment”}
在公式 (3) 中,这些标记用于计算对数似然函数,以优化模型参数,从而提高助手生成响应的准确性和相关性。
训练的目标函数:最大化 assistant responses 的对数似然性来逐步进行训练,作为监督微调期间的训练目标。
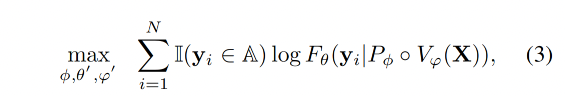
- N 是文本序列 Y 的长度,也就是一个句子中 token 的总数。
- 当 y i ∈ A y_i \in A yi∈A 时, I ( y i ∈ A ) = 1 \mathbb{I}(y_i \in A)=1 I(yi∈A)=1 ,否则为0。这里 I ( y i ∈ A ) \mathbb{I}(y_i \in A) I(yi∈A) 是一个指示函数,用来判断当前标记 y_i 是否属于助手响应。如果是,则该项为1,否则为0。
在监督微调阶段,也允许 LLM 和视觉编码器部分参数微调。
三、模型设置
3.1 模型结构
1、小型 LLM
表 1 中展示了 LLM 的选择,作者选择了 3 个相对小型的模型,且这几个模型基本涵盖了不同小型模型的范围:
- TinyLlama (1.1B) [59]
- StableLM-2-1.6B(1.6B) [47]
- Phi-2(2.7B) [33]

结论:
- Phi-2 对不同的 benchmark 表现都比较好,可能是由于其参数量更大
- Phi-2 variants 在 SQA-I 上超过了其他 variants,可能是由于其使用了 text-book 数据进行了训练
- TinyLLaVA 在 POPE 上的表现比较好
- 证明:大的 language 模型在 base setting 时的表现更好
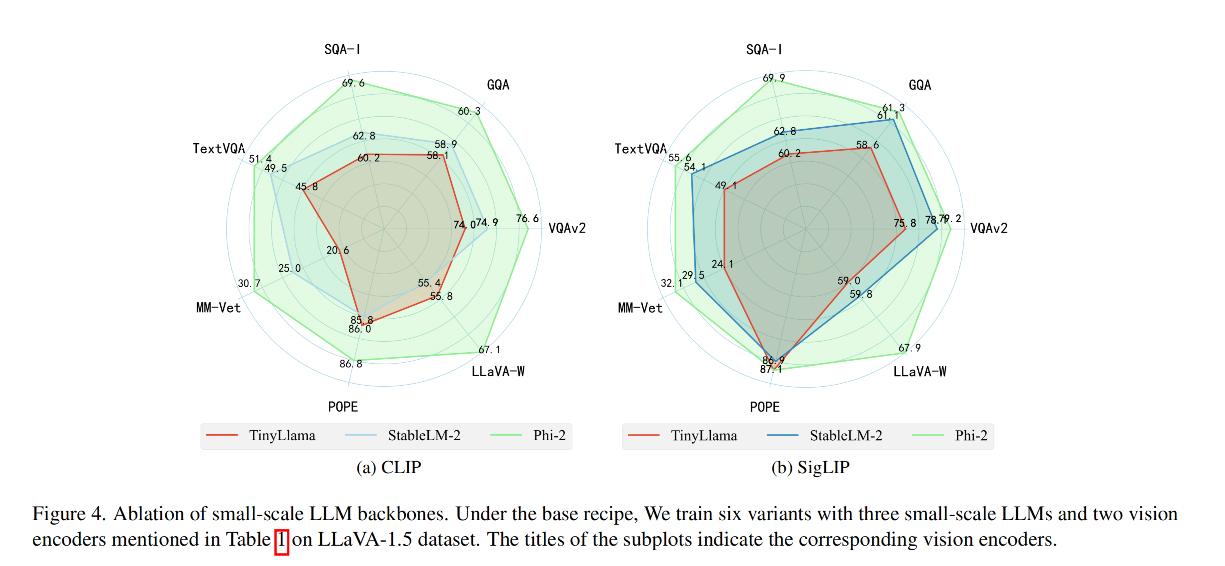
2、Vision encoder
通过对比发现 SigLIP 和小型 LLM 的结合能够生成比 CLIP 更好的效果
效果:

结论:
- 使用SigLIP [58]的模型变体相比于使用CLIP [44]的模型变体,在模型性能上有显著提升,这在TextVQA [45]和LLaVA-W [38]基准测试中尤为明显
- SigLIP 变体具有更高的输入分辨率(384 vs. 336)和更多的视觉令牌(729 vs. 576),与CLIP相比。这些因素可能使SigLIP包含了更多有利于进行细粒度图像理解的视觉信息。
3、Connector
作者继承了 LLaVA-v1.5 中使用 MLP+GELU 的思想,同样了使用了 resampler 进行了两者效果的对比
效果对比:
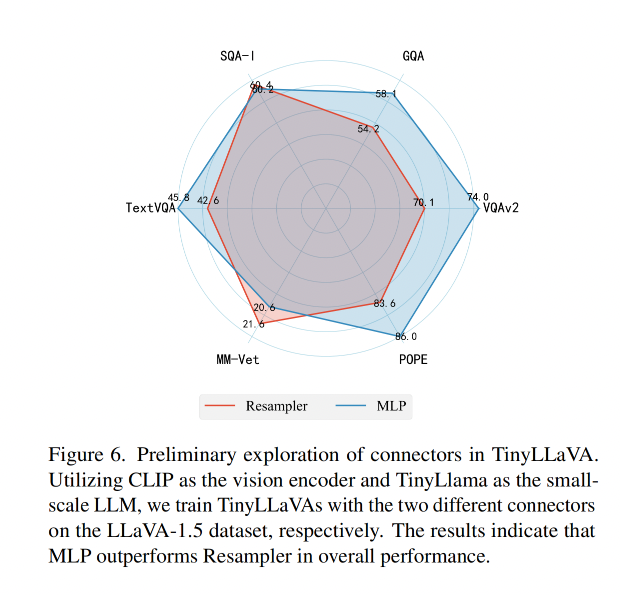
结论:
- MLP 效果更好
总结:
- 经过上述对比,作者最终使用了如下搭配
- 较大的 LLM
- SigLIP(有更大的输入分辨率和更多的 visual token)
- MLP
3.2 训练数据
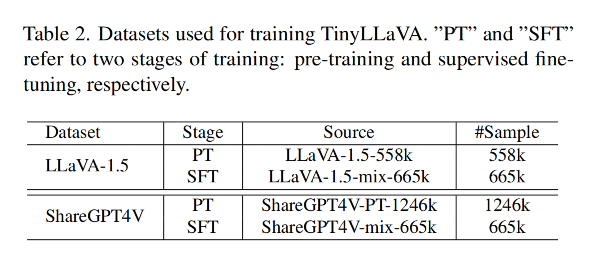
作者选择了两个不同的训练数据,分别来自 LLaVA-1.5 [37] 和 ShareGPT4V [7],来验证不同数据质量对 LMM 的影响
- LLaVA-1.5-PT: 包含 558k 的描述文字
- LLaVA-1.5-SFT 包含总计 665k 的视觉指令调优对话,这些对话是学术导向的视觉问答(VQA)[17, 22, 28, 45] 样本、来自 LLaVA-Instruct [38] 和 ShareGPT [20] 的指令调优数据的组合。
- ShareGPT4V-PT [7] 包含由 Share-Captioner [7] 生成的 1246k 描述文字
- ShareGPT4V-SFT 数据集与 LLaVA-1.5-SFT [37] 类似,不同之处在于 LLaVA-1.5-SFT 中的 23K 详细描述数据被随机抽取自 100K ShareGPT4V 数据中的详细描述替换。
效果对比:
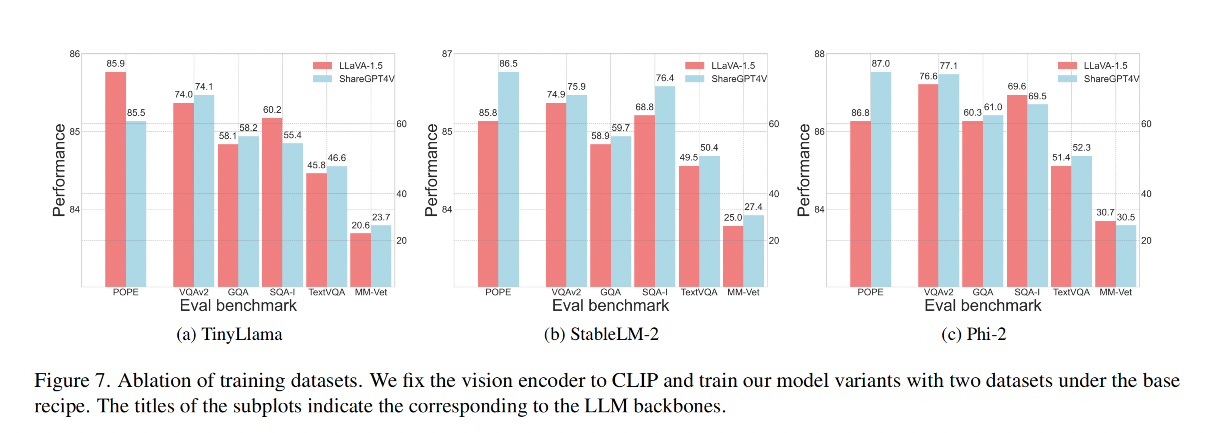
结论:使用 ShareGPT4V [7]
- 当在更大规模和更多样化的ShareGPT4V [7]数据集上进行预训练时,使用TinyLlama [59]作为小规模LLM的模型变体在评估性能上相比于LLaVA-1.5数据集[37]有整体提升。然而,在POPE [55]中观察到明显的性能下降
- 使用 ShareGPT4V [7] 时 StableLM-2和Phi-2的模型变体表现出全面的性能提升。
- 可能是由于TinyLlama [59]的参数不足,导致其无法充分适应大量数据,从而导致部分知识退化和更多幻觉生成。
这里是常见数据集的描述:
Here, we provide a brief overview of the key aspects each benchmark focuses on when assessing model capabilities.
• VQAv2 [17] contains image-question-answer tuples with images collected from the COCO dataset [36]. The test set of
VQAv2 evaluates models’ capabilities in terms of visual recognition, visual grounding, spatial reasoning as well as language
understanding.
• GQA [22] collected its data according to the scene graph structure provided by the Visual Genome [28] dataset. The test
set of GQA extensively evaluates models’ capabilities in terms of visual and compositional reasoning.
• TextVQA [45] is an image question answering dataset that contains images with texts. The test set of TextVQA requires
models to not only recognize textual information in the given images but also to reason over them.
• ScienceQA-IMG [40] is a subset of the ScienceQA [40] benchmark that contains images. The benchmark contains
scientific questions and answers collected from lectures and textbooks. During the evaluation, the model is prompted with
questions, choices, and relevant contexts, and is asked to predict the correct answers. This benchmark mainly evaluates models’
capabilities in reasoning with respect to scientific knowledge.
• POPE [55] benchmark is designed to evaluate the hallucination issues in LMMs. Its test samples incorporate positive
and negative objects (non-existent objects), which require the model to not only recognize positive samples accurately but
also correctly identify negative samples (measuring hallucination). It effectively assesses the model’s ability to handle
hallucinations.
• MM-Vet [56] is a comprehensive benchmark that evaluates LMMs on complicated multimodal tasks. MM-Vet uses
GPT-4 [1] to evaluate the outputs generated by LMMs. Its test set evaluates LMMs on six dimensions: visual recognition,
spatial reason- ing, common knowledge deduction, language generation, visual math reasoning, and OCR recognition.
• LLaVA-W benchmark includes 24 images and 60 questions, which are collected to evaluate LMMs’ capabilities in
challenging tasks and generalizability in novel domains [38].
• MME is a LMM evaluation benchmark that measures both perception and cognition abilities on a total of 14 subtasks [16].
This benchmark is automatically evaluated by GPT-4 [1].
• MMBench is a LMM evaluation benchmark that comprehensively assess models’ capabilities across 20 dimensions [39].
This benchmark is automatically evaluated by ChatGPT [42].
3.3 训练策略
作者探究了两个不同的训练策略,即 llava-1.5 和 shareGPT4V,对比如图 3
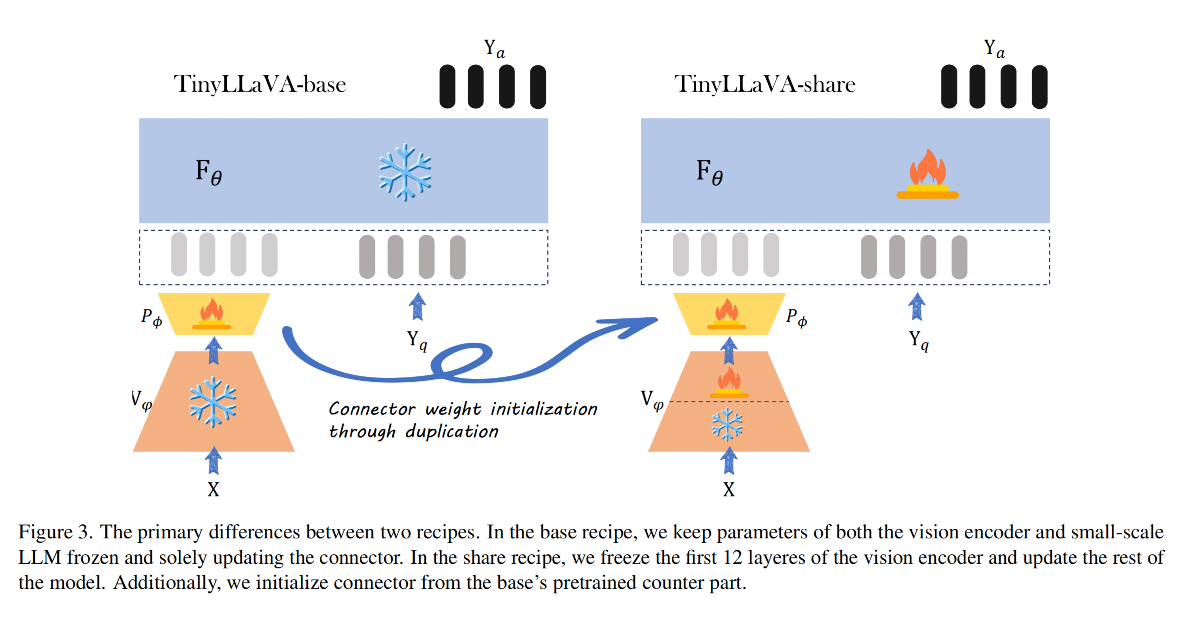
-
左侧方法来源于 LLaVA-v1.5,命名为 base,作为 base 策略
- 在 pretrain 阶段中,只更新 connector 的参数, LLM 和 vision encoder 都冻结,训练 1 epoch,学习率为 1e-3,batch size 为 256
- 在 SFT 阶段中,冻结 vision encoder,更新其他两个模块,训练 1 epoch,学习率为 2e-5,batch size 为 128
-
右侧方法来源于 ShareGPT4V[7],命名为 share
- 在 pretrain 阶段中,作者使用 base 的 pretrain 阶段训练的 connector 来初始化这里的 connector,冻结 vision encoder 的前 12 层,更新其他所有模块的参数,学习率为 2e-5,batch size 为 256
- 在 SFT 阶段中,和 base 的一样,冻结 vision encoder,更新其他两个模块,训练 1 epoch,学习率为 2e-5,batch size 为 128
效果对比:
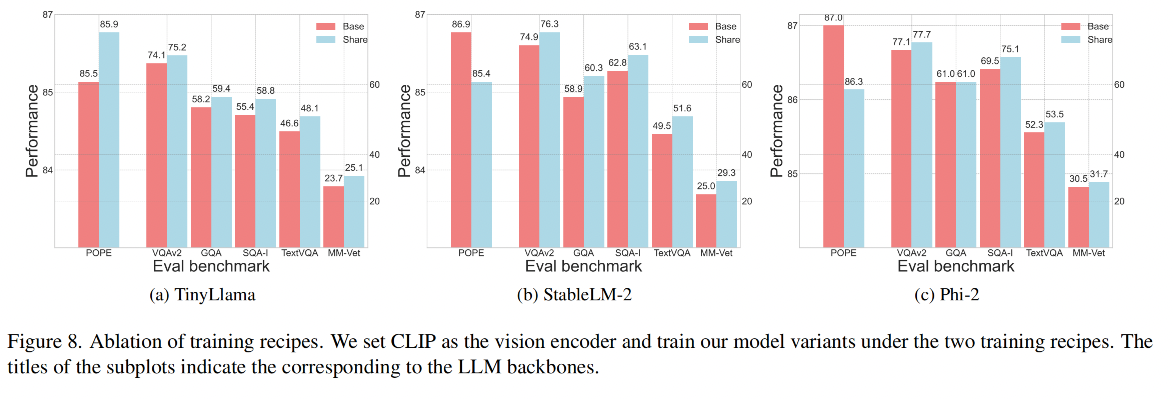
结论:
- 当模型在更大规模和更多样化的ShareGPT4V数据集[7]上进行预训练时,使用 share 可以显著提升所有变体的性能。也就是当使用小规模LLM时,微调视觉编码器可以提升性能,这与[27]中的结果相反,该结果指出在使用标准LLM时微调视觉编码器会显著降低性能。作者推测,是否微调视觉编码器能够提升性能取决于所伴随的LLM的规模和训练数据的规模,
- 故此使用 share 的模式微调 vision encoder 效果更好
总结:tinyllama 需要使用 share 方式,其他两种更大的模型使用 share 时会引入幻觉
-
使用 share 策略时,StableLM-2 和 Phi-2 在其他 benchmark 上有性能提升,但在 pope 上性能下降了很多(说明有更多的幻觉),share 和 base 的差别就在于 pretrain 阶段 share 训练的参数更多,所以这肯定是导致这一现象的根本原因,
-
所以作者认为,使用较小 LLM 的模型变体在预训练阶段可能需要更多可训练参数来很好地适应更大的数据集。因此,拥有更多可训练参数使得使用 TinyLlama 的模型变体能够在ShareGPT4V上取得更好的结果。然而,在预训练期间使用更多可训练参数对于较大的模型来说可能并不完全有利。例如,虽然使用StableLM-2和Phi-2的模型变体总体上表现出性能提升,但也引入了处理幻觉方面的更差表现。
-
结论1:在更大规模和更多样化的数据上训练模型变体使它们能够实现整体更好的性能。
-
结论2:使用较小LLM的模型变体可能需要更多可训练参数来减少幻觉
-
结论3:对于较大LLM的变体,使用更多可训练参数反而会导致更多幻觉。
3.4 评测 benchmark
- four image questionanswering benchmarks: VQA-v2 [17], GQA [22], ScienceQA-IMG [40], TextVQA [45],
- five comprehensive benchmark: POPE [55], MM-Vet [56], LLaVAW (LLaVA-Bench-in-the-Wild) [38], MME [16] , MMBench [39].
四、效果
模型命名规则:TinyLLaVA-{recipe name}-{vision encoder}-{languagemodel}.
例如:TinyLLaVA-base-C-TL 就是使用 base recipe, CLIP,TinyLlama
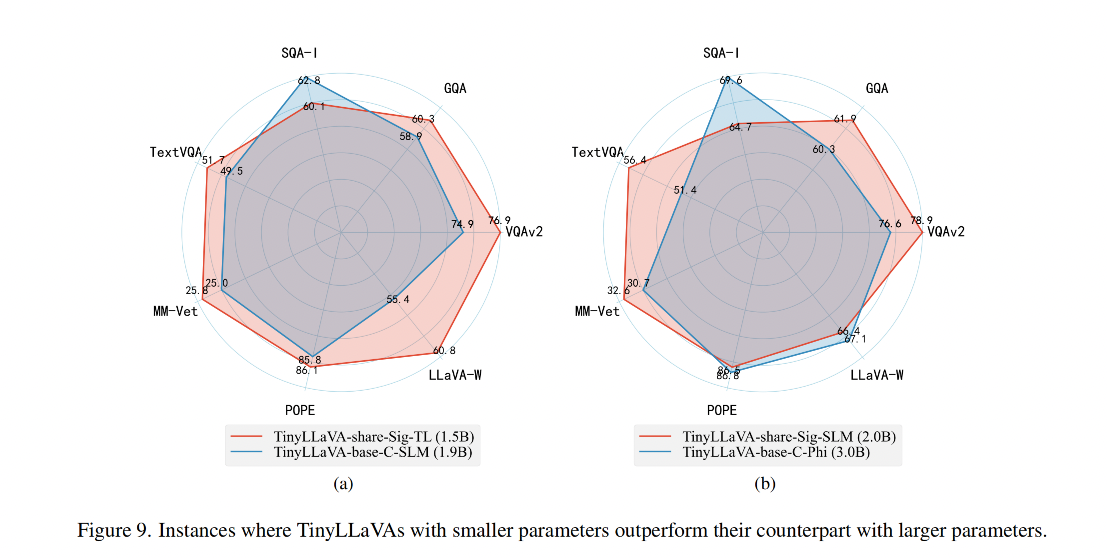
TinyLLaVA 的所有变体:
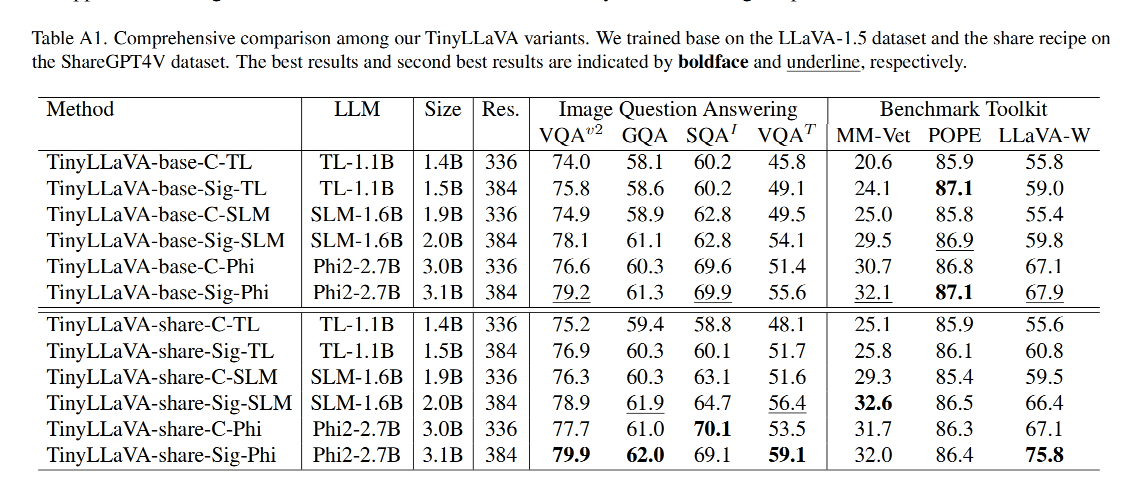
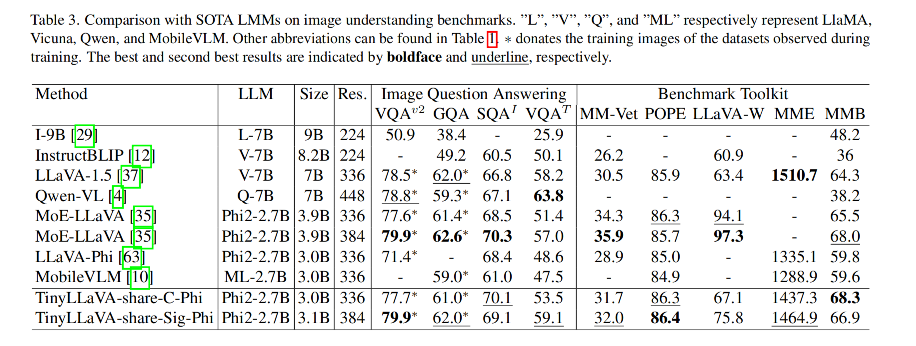
和其他模型的对比:
作者提出的最好的模型是 TinyLLaVA-3.1B (TinyLLaVA-share-Sig-Phi),和 7B 大小的 LLaVA-1.5 和 Qwen-VL 都取得了相当的效果
TinyLLaVA-3.1B 的一些可视化:


五、代码
模型的训练主要使用的是 transformer 库中 train 方法,在 train.py 中调用 trainer.train() 时,其实调用的是 transformer 中的 train 方法中的 inner_training_loop
pretrain 训练代码:
from packaging import version
import pathlib
import tokenizers
import transformers
from tinyllava.train.tinyllava_trainer import LLaVATrainer
from tinyllava.training_recipe import TrainingRecipeFactory
from tinyllava.utils import *
from tinyllava.model import *
from tinyllava.data.dataset import make_supervised_data_module
IS_TOKENIZER_GREATER_THAN_0_14 = version.parse(tokenizers.__version__) >= version.parse('0.14')
def load_settings(model_arguments, data_arguments, training_arguments):
model_arguments.tune_type_connector = training_arguments.tune_type_connector
model_arguments.tune_type_llm = training_arguments.tune_type_llm
model_arguments.tune_type_vision_tower = training_arguments.tune_type_vision_tower
model_arguments.image_aspect_ratio = data_arguments.image_aspect_ratio
model_args = {}
model_args['llm'] = _load_llm_settings(model_arguments)
model_args['vision_tower'] = _load_vision_settings(model_arguments)
model_args['connector'] = _load_connector_settings(model_arguments)
return model_args
def _load_llm_settings(model_arguments):
llm_args = {}
llm_args['model_name_or_path'] = model_arguments.model_name_or_path
llm_args['cache_dir'] = model_arguments.cache_dir
llm_args['attn_implementation'] = model_arguments.attn_implementation # flash_attention_2 only supports torch.float16 and torch.bfloat16 dtypes
return llm_args
def _load_vision_settings(model_arguments):
vision_args = {}
vision_args['model_name_or_path'] = model_arguments.vision_tower.split(':')[-1]
if model_arguments.vision_tower2 != '':
vision_args['model_name_or_path2'] = model_arguments.vision_tower2.split(':')[-1]
return vision_args
def _load_connector_settings(model_arguments):
connector_args = {}
connector_args['connector_type'] = model_arguments.connector_type
return connector_args
def train():
# load argument
import pdb; pdb.set_trace()
parser = transformers.HfArgumentParser(
(ModelArguments, DataArguments, TrainingArguments)) # HfArgumentParser 是一个解析器,用于解析这三个输入的参数
model_arguments, data_arguments, training_arguments = parser.parse_args_into_dataclasses()
logger_setting(getattr(training_arguments, 'output_dir', None))
training_recipe = TrainingRecipeFactory(training_arguments.training_recipe)(training_arguments)
# model_args contain arguements for huggingface model .from_pretrained function
model_args = load_settings(model_arguments, data_arguments, training_arguments)
model_args = training_recipe.add_args(model_args)
model_config = TinyLlavaConfig()
model_config.load_from_config(model_arguments)
model = TinyLlavaForConditionalGeneration(model_config)
# load pretrained checkpoint
if training_arguments.pretrained_model_path is not None:
model = training_recipe.load(model, model_args)
else:
model.load_llm(**model_args['llm'])
model.load_vision_tower(**model_args['vision_tower'])
model.load_connector(**model_args['connector'])
model = training_recipe(model)
model.config.use_cache = False
model.config.image_aspect_ratio = data_arguments.image_aspect_ratio
tokenizer = model.tokenizer
data_arguments.image_processor = model.vision_tower._image_processor
data_arguments.is_multimodal = True
data_module = make_supervised_data_module(tokenizer=tokenizer,
data_args=data_arguments)
log_trainable_params(model) # not work well with zero3
trainer = LLaVATrainer(model=model, #does not require model.to(device), huggingface/deepspeed does it for you?
tokenizer=tokenizer,
args=training_arguments,
**data_module)
trainer.train()
training_recipe.save(model, trainer)
if __name__ == "__main__":
train()
model_arguments: ModelArguments(cache_dir=None, model_name_or_path='open_models/phi-2', tokenizer_name_or_path=None, attn_implementation='flash_attention_2', vision_tower='open_models/siglip-so400m-patch14-384', vision_tower2='', connector_type='mlp2x_gelu', mm_vision_select_layer=-2, mm_patch_merge_type='flat', mm_vision_select_feature='patch', resampler_hidden_size=768, num_queries=128, num_resampler_layers=3, model_max_length=3072, tokenizer_use_fast=False, tokenizer_padding_side='right')
data_arguments: DataArguments(data_path='dataset/text_files/blip_laion_cc_sbu_558k.json', lazy_preprocess=True, is_multimodal=True, image_folder='dataset/llava/llava_pretrain/images', image_aspect_ratio='square', conv_version='pretrain')
training_arguments:TrainingArguments(output_dir='checkpoints/llava_factory/tiny-llava-phi-2-siglip-so400m-patch14-384-base-pretrain', overwrite_output_dir=False, do_train=False, do_eval=False, do_predict=False, evaluation_strategy=<IntervalStrategy.NO: 'no'>, prediction_loss_only=False, per_device_train_batch_size=1, per_device_eval_batch_size=4, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=1, eval_accumulation_steps=None, eval_delay=0, learning_rate=0.001, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=1.0, max_steps=-1, lr_scheduler_type=<SchedulerType.COSINE: 'cosine'>, lr_scheduler_kwargs={}, warmup_ratio=0.03, warmup_steps=0, log_level='passive', log_level_replica='warning', log_on_each_node=True, logging_dir='checkpoints/llava_factory/tiny-llava-phi-2-siglip-so400m-patch14-384-base-pretrain/runs/Jun21_18-16-26_cv-h800-2-master-0', logging_strategy=<IntervalStrategy.STEPS: 'steps'>, logging_first_step=False, logging_steps=1.0, logging_nan_inf_filter=True, save_strategy=<IntervalStrategy.STEPS: 'steps'>, save_steps=24000, save_total_limit=1, save_safetensors=True, save_on_each_node=False, save_only_model=False, no_cuda=False, use_cpu=False, use_mps_device=False, seed=42, data_seed=None, jit_mode_eval=False, use_ipex=False, bf16=False, fp16=True, fp16_opt_level='O1', half_precision_backend='auto', bf16_full_eval=False, fp16_full_eval=False, tf32=False, local_rank=0, ddp_backend=None, tpu_num_cores=None, tpu_metrics_debug=False, debug=[], dataloader_drop_last=False, eval_steps=None, dataloader_num_workers=8, dataloader_prefetch_factor=None, past_index=-1, run_name='tiny-llava-phi-2-siglip-so400m-patch14-384-base-pretrain', disable_tqdm=False, remove_unused_columns=False, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, fsdp=[], fsdp_min_num_params=0, fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}, fsdp_transformer_layer_cls_to_wrap=None, accelerator_config=AcceleratorConfig(split_batches=False, dispatch_batches=None, even_batches=True, use_seedable_sampler=True), deepspeed='./scripts/zero3.json', label_smoothing_factor=0.0, optim=<OptimizerNames.ADAMW_TORCH: 'adamw_torch'>, optim_args=None, adafactor=False, group_by_length=False, length_column_name='length', report_to=['tensorboard'], ddp_find_unused_parameters=None, ddp_bucket_cap_mb=None, ddp_broadcast_buffers=None, dataloader_pin_memory=True, dataloader_persistent_workers=False, skip_memory_metrics=True, use_legacy_prediction_loop=False, push_to_hub=False, resume_from_checkpoint=None, hub_model_id=None, hub_strategy=<HubStrategy.EVERY_SAVE: 'every_save'>, hub_token=None, hub_private_repo=False, hub_always_push=False, gradient_checkpointing=True, gradient_checkpointing_kwargs=None, include_inputs_for_metrics=False, fp16_backend='auto', push_to_hub_model_id=None, push_to_hub_organization=None, push_to_hub_token=None, mp_parameters='', auto_find_batch_size=False, full_determinism=False, torchdynamo=None, ray_scope='last', ddp_timeout=1800, torch_compile=False, torch_compile_backend=None, torch_compile_mode=None, dispatch_batches=None, split_batches=None, include_tokens_per_second=False, include_num_input_tokens_seen=False, neftune_noise_alpha=None, optim_target_modules=None, training_recipe='common', tune_type_llm='frozen', tune_type_vision_tower='frozen', tune_vision_tower_from_layer=0, tune_type_connector='full', tune_embed_tokens=False, double_quant=True, quant_type='nf4', bits=16, lora_r=64, lora_alpha=16, lora_dropout=0.05, lora_weight_path='', lora_bias='none', mm_projector_lr=None, group_by_modality_length=False, vision_tower_lr=None, pretrained_model_path=None)
model 模型结构:model = TinyLlavaForConditionalGeneration(model_config)
TinyLlavaForConditionalGeneration(
(language_model): PhiForCausalLM(
(model): PhiModel(
(embed_tokens): Embedding(51200, 2560)
(embed_dropout): Dropout(p=0.0, inplace=False)
(layers): ModuleList(
(0-31): 32 x PhiDecoderLayer(
(self_attn): PhiSdpaAttention(
(q_proj): Linear(in_features=2560, out_features=2560, bias=True)
(k_proj): Linear(in_features=2560, out_features=2560, bias=True)
(v_proj): Linear(in_features=2560, out_features=2560, bias=True)
(dense): Linear(in_features=2560, out_features=2560, bias=True)
(rotary_emb): PhiRotaryEmbedding()
)
(mlp): PhiMLP(
(activation_fn): NewGELUActivation()
(fc1): Linear(in_features=2560, out_features=10240, bias=True)
(fc2): Linear(in_features=10240, out_features=2560, bias=True)
)
(input_layernorm): LayerNorm((2560,), eps=1e-05, elementwise_affine=True)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
)
(final_layernorm): LayerNorm((2560,), eps=1e-05, elementwise_affine=True)
)
(lm_head): Linear(in_features=2560, out_features=51200, bias=True)
)
(vision_tower): SIGLIPVisionTower(
(_vision_tower): SiglipVisionModel(
(vision_model): SiglipVisionTransformer(
(embeddings): SiglipVisionEmbeddings(
(patch_embedding): Conv2d(3, 1152, kernel_size=(14, 14), stride=(14, 14), padding=valid)
(position_embedding): Embedding(729, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(self_attn): SiglipAttention(
(k_proj): Linear(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear(in_features=1152, out_features=1152, bias=True)
(q_proj): Linear(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear(in_features=1152, out_features=1152, bias=True)
)
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): PytorchGELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(head): SiglipMultiheadAttentionPoolingHead(
(attention): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=1152, out_features=1152, bias=True)
)
(layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): PytorchGELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
)
)
)
)
(connector): MLPConnector(
(_connector): Sequential(
(0): Linear(in_features=1152, out_features=2560, bias=True)
(1): GELU(approximate='none')
(2): Linear(in_features=2560, out_features=2560, bias=True)
)
)
)
stablelm 的 tokenizer 如下所示:
tokenizer:
GPT2TokenizerFast(name_or_path='stablelm-2-zephyr-1_6b', vocab_size=100289, model_max_length=2048, is_fast=True, padding_side='right', truncation_side='right', special_tokens={'bos_token': '<|endoftext|>', 'eos_token': '<|endoftext|>', 'unk_token': '<|endoftext|>', 'pad_token': '<|endoftext|>', 'additional_special_tokens': ['<|reg_extra|>', '<|endoftext|>', '<|fim_prefix|>', '<|fim_middle|>', '<|fim_suffix|>', '<|fim_pad|>', '<gh_stars>', '<filename>', '<issue_start>', '<issue_comment>', '<issue_closed>', '<jupyter_start>', '<jupyter_text>', '<jupyter_code>', '<jupyter_output>', '<empty_output>', '<commit_before>', '<commit_msg>', '<commit_after>', '<reponame>', '<|endofprompt|>', '<|im_start|>', '<|im_end|>', '<|pause|>', '<|reg0|>', '<|reg1|>', '<|reg2|>', '<|reg3|>', '<|reg4|>', '<|reg5|>', '<|reg6|>', '<|reg7|>', '<|extra0|>']}, clean_up_tokenization_spaces=True), added_tokens_decoder={
100256: AddedToken("<|reg_extra|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100257: AddedToken("<|endoftext|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100258: AddedToken("<|fim_prefix|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100259: AddedToken("<|fim_middle|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100260: AddedToken("<|fim_suffix|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100261: AddedToken("<|fim_pad|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100262: AddedToken("<gh_stars>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100263: AddedToken("<filename>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100264: AddedToken("<issue_start>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100265: AddedToken("<issue_comment>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100266: AddedToken("<issue_closed>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100267: AddedToken("<jupyter_start>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100268: AddedToken("<jupyter_text>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100269: AddedToken("<jupyter_code>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100270: AddedToken("<jupyter_output>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100271: AddedToken("<empty_output>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100272: AddedToken("<commit_before>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100273: AddedToken("<commit_msg>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100274: AddedToken("<commit_after>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100275: AddedToken("<reponame>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100276: AddedToken("<|endofprompt|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100277: AddedToken("<|im_start|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100278: AddedToken("<|im_end|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100279: AddedToken("<|pause|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100280: AddedToken("<|reg0|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100281: AddedToken("<|reg1|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100282: AddedToken("<|reg2|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100283: AddedToken("<|reg3|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100284: AddedToken("<|reg4|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100285: AddedToken("<|reg5|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100286: AddedToken("<|reg6|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100287: AddedToken("<|reg7|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100288: AddedToken("<|extra0|>", rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
下面这是:打印出来的参数 log,这是 pretrain 阶段的
2024-06-22 17:11:58,229 | INFO: Total Parameters: 6295552, Total Trainable Parameters: 6295552
2024-06-22 17:11:58,229 | INFO: Trainable Parameters:
connector._connector.0.weight: 2097152 parameters
connector._connector.0.bias: 2048 parameters
connector._connector.2.weight: 4194304 parameters
connector._connector.2.bias: 2048 parameters
图像处理和文本处理都在 prepare_inputs_labels_for_multimodal 中:
图像处理逻辑:使用 vision_tower 提取特征,然后输入 connector 就得到了和文本 align 的特征
image_features = self.encode_images(images) # torch.Size([1, 576, 2048])
def encode_images(self, images):
kwargs = {}
kwargs['vision_feature_layer'] = self.config.vision_feature_layer # -2
kwargs['vision_feature_select_strategy'] = self.config.vision_feature_select_strategy # 'patch'
images = images.to(device=self.device, dtype=self.dtype)
image_features = self.vision_tower(images, **kwargs) # torch.Size([1, 576, 1024])
image_features = self.connector(image_features) # torch.Size([1, 576, 2048])
return image_features
文本处理逻辑:使用文本模型,提取文本 token 的特征,每个 token 编码成 2048 维的特征
cur_input_embeds = self.language_model.get_input_embeddings()(torch.cat(cur_input_ids_noim)) # 对文本的token进行特征提取,得到 [11,2048] 维
得到图像特征和文本特征后,将图像特征和文本特征 concat 起来(按 prompt 中 和 文本单词的顺序),作为处理后的输入特征
处理后的特征包括两部分:
cur_new_input_embeds:[587, 2048] 维,是图像和文本的特征cur_new_labels:[587] 维,是图像和文本token的标签,图像 token 的标签为 -100,其中有多少图像 token,就有多少个 -100
def prepare_inputs_labels_for_multimodal(
self, input_ids, position_ids, attention_mask, past_key_values, labels,
images, image_sizes=None
):
import pdb; pdb.set_trace()
'''
input_ids: tensor([[ -200, 1820, 93308, 272, 16115, 1879, 4994, 3189, 343, 3258, 2115, 198]], device='cuda:0')
position_ids: None
attention_mask: tensor([[True, True, True, True, True, True, True, True, True, True, True, True]], device='cuda:0')
labels: tensor([[ -100, 1820, 93308, 272, 16115, 1879, 4994, 3189, 343, 3258, 2115, 198]], device='cuda:0')
images.shape: torch.Size([1, 3, 336, 336])
'''
vision_tower = self.vision_tower
if vision_tower is None or images is None or input_ids.shape[1] == 1:
return input_ids, position_ids, attention_mask, past_key_values, None, labels
image_features = self.encode_images(images) # torch.Size([1, 576, 2048])
# TODO: image start / end is not implemented here to support pretraining.
if getattr(self.config, 'tune_mm_mlp_adapter', False): # 检查配置是否需要调整多模态 MLP 适配器,如果需要则抛出未实现错误
raise NotImplementedError
# Let's just add dummy tensors if they do not exist,
# it is a headache to deal with None all the time.
# But it is not ideal, and if you have a better idea,
# please open an issue / submit a PR, thanks.
_labels = labels
_position_ids = position_ids
_attention_mask = attention_mask
if attention_mask is None: # 如果注意力掩码为空,则创建一个全为true的掩码,不为空时则转换为布尔类型
attention_mask = torch.ones_like(input_ids, dtype=torch.bool)
else:
attention_mask = attention_mask.bool() # [[True, True, True, True, True, True, True, True, True, True, True, True]],当 attention_mask 全为 True 时,这意味着输入序列中的所有标记都是有效的,没有任何需要被忽略或填充的部分。
if position_ids is None:
position_ids = torch.arange(0, input_ids.shape[1], dtype=torch.long, device=input_ids.device) # tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11], device='cuda:0')
if labels is None:
labels = torch.full_like(input_ids, IGNORE_INDEX)
# remove the padding using attention_mask -- FIXME
_input_ids = input_ids # tensor([[ -200, 1820, 93308, 272, 16115, 1879, 4994, 3189, 343, 3258, 2115, 198]], device='cuda:0')
input_ids = [cur_input_ids[cur_attention_mask] for cur_input_ids, cur_attention_mask in zip(input_ids, attention_mask)] #[ -200, 1820, 93308, 272, 16115, 1879, 4994, 3189, 343, 3258, 2115, 198]
labels = [cur_labels[cur_attention_mask] for cur_labels, cur_attention_mask in zip(labels, attention_mask)]
new_input_embeds = []
new_labels = []
cur_image_idx = 0
for batch_idx, cur_input_ids in enumerate(input_ids):
num_images = (cur_input_ids == IMAGE_TOKEN_INDEX).sum() # IMAGE_TOKEN_INDEX=200
if num_images == 0: # 1
cur_image_features = image_features[cur_image_idx]
cur_input_embeds_1 = self.language_model.get_input_embeddings()(cur_input_ids)
cur_input_embeds = torch.cat([cur_input_embeds_1, cur_image_features[0:0]], dim=0)
new_input_embeds.append(cur_input_embeds)
new_labels.append(labels[batch_idx])
cur_image_idx += 1
continue
image_token_indices = [-1] + torch.where(cur_input_ids == IMAGE_TOKEN_INDEX)[0].tolist() + [cur_input_ids.shape[0]] # [-1,0,12]
# image_token_indices 用于标识图像token在输入序列中位置的列表
# -1:用于方便后续计算边界或区间
# 0:找到图像token的位置
# 12:这是输入序列的长度。将这个长度添加到列表中,通常用于表示序列的结束位置
cur_input_ids_noim = []
cur_labels = labels[batch_idx] # tensor([ -100, 1820, 93308, 272, 16115, 1879, 4994, 3189, 343, 3258, 2115, 198], device='cuda:0')
cur_labels_noim = [] # 用于存储从 cur_labels 中提取的不包含图像标记的标签子序列,也就是 label 不等于 -100 的所有token
for i in range(len(image_token_indices) - 1):
cur_input_ids_noim.append(cur_input_ids[image_token_indices[i]+1:image_token_indices[i+1]])
cur_labels_noim.append(cur_labels[image_token_indices[i]+1:image_token_indices[i+1]])
'''
cur_input_ids_noim: [tensor([], device='cuda:0', dtype=torch.int64), tensor([ 1820, 93308, 272, 16115, 1879, 4994, 3189, 343, 3258, 2115, 198], device='cuda:0')]
cur_labels_noim: [tensor([], device='cuda:0', dtype=torch.int64), tensor([ 1820, 93308, 272, 16115, 1879, 4994, 3189, 343, 3258, 2115, 198], device='cuda:0')]
这里这两个空向量,其实是为图像特征准备的位置
'''
split_sizes = [x.shape[0] for x in cur_labels_noim] # [0,11]
cur_input_embeds = self.language_model.get_input_embeddings()(torch.cat(cur_input_ids_noim)) # 对文本的token进行特征提取,得到 [11,2048] 维
cur_input_embeds_no_im = torch.split(cur_input_embeds, split_sizes, dim=0)
'''
(Pdb) cur_input_embeds_no_im, cur_input_embeds_no_im[1].shape=torch.Size([11, 2048])
(tensor([], device='cuda:0', size=(0, 2048), dtype=torch.float16,
grad_fn=<SplitWithSizesBackward0>), tensor([[ 0.0493, 0.0090, 0.0266, ..., 0.0219, 0.0205, 0.0153],
[ 0.0042, 0.0229, 0.0310, ..., -0.0723, 0.0547, 0.0148],
[ 0.0332, 0.0334, -0.0364, ..., -0.0096, -0.0260, 0.0026],
...,
[-0.0281, -0.0354, 0.0269, ..., 0.0732, 0.0152, 0.0100],
[-0.0042, -0.0085, 0.0044, ..., 0.0106, 0.0471, 0.0206],
[-0.0049, -0.0210, 0.0110, ..., 0.0420, 0.0164, 0.0120]],
device='cuda:0', dtype=torch.float16, grad_fn=<SplitWithSizesBackward0>))
'''
cur_new_input_embeds = []
cur_new_labels = []
# 这里循环两次:
# 第一次循环的时候,cur_new_input_embeds加一个空[], 然后将图像特征[576,2048]加到cur_new_input_embeds中,将576个-100加到cur_new_labels中
# 第二次循环的时候,cur_new_input_embeds加上文本[11,2048]特征,将11个文本label 加到 cur_new_labels中
# 最后得到的就是cur_new_input_embeds 中是 图像特征+文本特征,cur_new_labels 中是图像标签+文本标签
for i in range(num_images + 1): # [0,1]
cur_new_input_embeds.append(cur_input_embeds_no_im[i]) # []
cur_new_labels.append(cur_labels_noim[i]) # []
if i < num_images: # 只有在前 num_images 次迭代时才会插入图像特征
cur_image_features = image_features[cur_image_idx] # 获取当前图像特征
cur_image_idx += 1 # 增加索引
cur_new_input_embeds.append(cur_image_features) # 将图像特征加到cur_new_input_embeds中, cur_new_input_embeds[1].shape=torch.Size([576, 2048])
'''
(Pdb) cur_new_input_embeds
[tensor([], device='cuda:0', size=(0, 2048), dtype=torch.float16,
grad_fn=<SplitWithSizesBackward0>), tensor([[ 0.0793, 0.0826, 0.1770, ..., 0.1801, 0.2981, 0.4966],
[ 0.5674, 1.1934, 0.2754, ..., 0.9082, -0.0468, 0.7847],
[-0.0399, -0.0409, 0.4421, ..., 0.1904, 0.2856, 0.5449],
...,
[ 0.0781, 0.0622, 0.2316, ..., 0.0292, 0.0978, 0.4910],
[ 0.1106, 0.0220, 0.2448, ..., 0.0934, 0.1439, 0.4155],
[-0.0681, -0.0571, 0.3655, ..., 0.1196, 0.2247, 0.5801]],
'''
cur_new_labels.append(torch.full((cur_image_features.shape[0],), IGNORE_INDEX, device=cur_labels.device, dtype=cur_labels.dtype))
# cur_new_labels 是一个list,cur_new_labels[0]=[], cur_new_labels[1] 是 576 个 -100
cur_new_input_embeds = [x.to(self.device) for x in cur_new_input_embeds]
cur_new_input_embeds = torch.cat(cur_new_input_embeds) # torch.Size([587, 2048])
cur_new_labels = torch.cat(cur_new_labels) # torch.Size([587])
new_input_embeds.append(cur_new_input_embeds) # batch 级别
new_labels.append(cur_new_labels) # batch 级别
# Truncate sequences to max length as image embeddings can make the sequence longer
tokenizer_model_max_length = getattr(self.config, 'tokenizer_model_max_length', None) # 2048
if tokenizer_model_max_length is not None:
new_input_embeds = [x[:tokenizer_model_max_length] for x in new_input_embeds]
new_labels = [x[:tokenizer_model_max_length] for x in new_labels]
# Combine them
max_len = max(x.shape[0] for x in new_input_embeds) # 587
batch_size = len(new_input_embeds)
# 下面是给每个 batch 内的不同样本进行维度填充,统一填充到一个batch内最长的样本的维度,同时给batch中每个样本对应的label和attention_mask 也进行填充
new_input_embeds_padded = []
new_labels_padded = torch.full((batch_size, max_len), IGNORE_INDEX, dtype=new_labels[0].dtype, device=new_labels[0].device)
attention_mask = torch.zeros((batch_size, max_len), dtype=attention_mask.dtype, device=attention_mask.device) # [False, ..., False]
position_ids = torch.zeros((batch_size, max_len), dtype=position_ids.dtype, device=position_ids.device) # [0, ..., 0]
for i, (cur_new_embed, cur_new_labels) in enumerate(zip(new_input_embeds, new_labels)): # 按 batch 提取, 这里是给
cur_len = cur_new_embed.shape[0]
if getattr(self.config, 'tokenizer_padding_side', 'right') == "left":
new_input_embeds_padded.append(torch.cat((
torch.zeros((max_len - cur_len, cur_new_embed.shape[1]), dtype=cur_new_embed.dtype, device=cur_new_embed.device),
cur_new_embed
), dim=0))
if cur_len > 0:
new_labels_padded[i, -cur_len:] = cur_new_labels
attention_mask[i, -cur_len:] = True
position_ids[i, -cur_len:] = torch.arange(0, cur_len, dtype=position_ids.dtype, device=position_ids.device)
else: # go in
new_input_embeds_padded.append(torch.cat((
cur_new_embed,
torch.zeros((max_len - cur_len, cur_new_embed.shape[1]), dtype=cur_new_embed.dtype, device=cur_new_embed.device)
), dim=0))
if cur_len > 0:
new_labels_padded[i, :cur_len] = cur_new_labels
attention_mask[i, :cur_len] = True
position_ids[i, :cur_len] = torch.arange(0, cur_len, dtype=position_ids.dtype, device=position_ids.device)
new_input_embeds = torch.stack(new_input_embeds_padded, dim=0)
if _labels is None:
new_labels = None
else:
new_labels = new_labels_padded
if _attention_mask is None:
attention_mask = None
else:
attention_mask = attention_mask.to(dtype=_attention_mask.dtype)
if _position_ids is None:
position_ids = None
return None, position_ids, attention_mask, past_key_values, new_input_embeds, new_labels
数据都处理完后,可以进行模型 forward 了,以 stablelm 为例,会进入这里来进行前传,在这里会将图文混合特征送入语言模型,输出预测结果,然后计算预测结果和真实 label 的交叉熵损失:
../tinyllava/lib/python3.9/site-packages/transformers/models/stablelm/modeling_stablelm.py(1066)forward()
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, CausalLMOutputWithPast]:
r"""
Args:
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
Returns:
Example:
```python
>>> from transformers import AutoTokenizer, StableLmForCausalLM
>>> model = StableLmForCausalLM.from_pretrained("stabilityai/stablelm-3b-4e1t")
>>> tokenizer = AutoTokenizer.from_pretrained("stabilityai/stablelm-3b-4e1t")
>>> prompt = "The weather is always wonderful in"
>>> inputs = tokenizer(prompt, return_tensors="pt")
>>> # Generate
>>> generate_ids = model.generate(inputs.input_ids, max_length=30)
>>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
'The weather is always wonderful in the summer in the city of San Diego. The city is located on the coast of the Pacific Ocean and is surrounded by'
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0] # torch.Size([1, 587, 2048])
logits = self.lm_head(hidden_states) # Linear(in_features=2048, out_features=100352, bias=False), torch.Size([1, 587, 100352])
loss = None
if labels is not None:
# Shift so that tokens < n predict n
shift_logits = logits[..., :-1, :].contiguous()
shift_labels = labels[..., 1:].contiguous()
# Flatten the tokens
loss_fct = CrossEntropyLoss()
shift_logits = shift_logits.view(-1, self.config.vocab_size)
shift_labels = shift_labels.view(-1)
# Enable model parallelism
shift_labels = shift_labels.to(shift_logits.device)
loss = loss_fct(shift_logits, shift_labels)
if not return_dict:
output = (logits,) + outputs[1:]
return (loss,) + output if loss is not None else output
return CausalLMOutputWithPast(
loss=loss,
logits=logits,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
推理代码:
from tinyllava.eval.run_tiny_llava import eval_model
model_path = "/absolute/path/to/your/model/"
prompt = "What are the things I should be cautious about when I visit here?"
image_file = "https://llava-vl.github.io/static/images/view.jpg"
conv_mode = "phi" # or llama, gemma, etc
args = type('Args', (), {
"model_path": model_path,
"model": None,
"query": prompt,
"conv_mode": conv_mode,
"image_file": image_file,
"sep": ",",
"temperature": 0,
"top_p": None,
"num_beams": 1,
"max_new_tokens": 512
})()
eval_model(args)
"""
Output:
XXXXXXXXXXXXXXXXX
"""
这里尝试的是使用自己训练的模型进行推理,推理使用的是 generate() 方法,图像预处理和训练时候一样,generate 的方法调用的是 tinyllava/lib/python3.9/site-packages/transformers/generation/utils.py(1325)generate() 方法

下面是 phi-2 的回答:
When visiting the wooden pier in the image, there are a few things to consider. First, it is important to be aware of the weather conditions, as the pier is located near a mountain and the water is calm. This could mean that the weather might change rapidly, so it is advisable to bring appropriate clothing and gear for the weather conditions. Second, since the pier is located in a wooded area, it is essential to be cautious of any wildlife or potential hazards in the vicinity. Lastly, it is advisable to follow any posted signs or guidelines provided by the pier or local authorities to ensure a safe and enjoyable experience.



















 1264
1264

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











