







 文章介绍了Transformer模型的结构,其由多个包含多头自注意力机制和全连接前馈神经网络的层组成,以及解码器中的位置掩码机制。此外,文章探讨了自监督学习的不同形式,如BERT等模型如何通过自监督预训练提升语义表征能力,强调了自监督学习在自然语言处理任务中的重要性。
文章介绍了Transformer模型的结构,其由多个包含多头自注意力机制和全连接前馈神经网络的层组成,以及解码器中的位置掩码机制。此外,文章探讨了自监督学习的不同形式,如BERT等模型如何通过自监督预训练提升语义表征能力,强调了自监督学习在自然语言处理任务中的重要性。
一、Transformer变换器模型
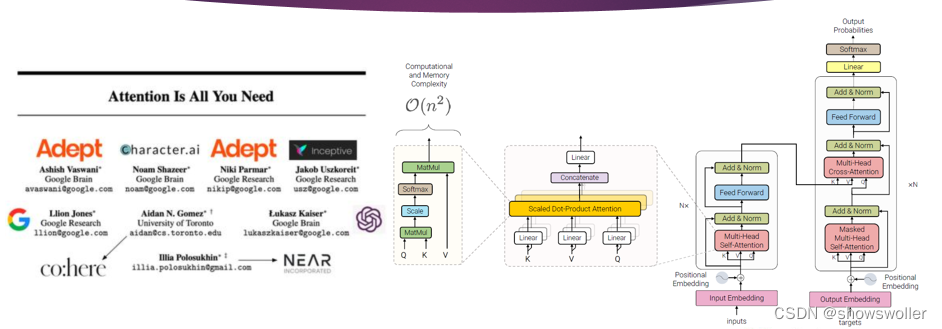
Transformer模型的编码器是由6个完全相同的层堆叠而成,每一层有两个子层 。
第一个子层是多头自注意力机制层,第二个子层是由一一个简单的、按逐个位置进行全连接的前馈神经网络。在两个子层之间通过残差网络结构进行连接,后接一一个层正则化层。可以得出,每一一个子层的输出通过公式可以表示为LayerNorm(x + Sublayer(x)),其中,Sublayer(x)函数由各个子层独立实现。为了方便各层之间的残差连接,模型中所有的子层包括嵌人层,固定输出的维度为512。Transformer 模型网络架构如图2.2所示。
Transformer模型的解码器也是由6个完全相同的层堆叠而成。除了编码器中介绍过的两个子层之外解码器还有第三个子层用于对编码器对的输出实现多头注意力机制。与编码器类似,使用残差架构连接每个子层,后接 一个层正则化层。对于解码器对的掩码自注意力子层,原论文对结构做了了改变来防止当前序列的位置信息和后续序列的位置信息混在一起。 这样的一个位置掩码操作作,再加上原有输出嵌入端对位置信息做悄难,我可以确保对位置;的预测仅依赖于已知的位置:之前的输出,而不会依赖于位置i之后的输出。
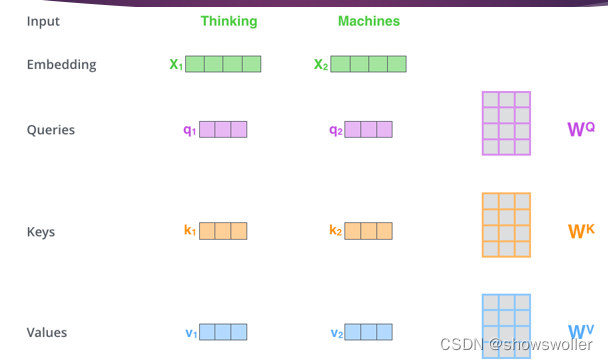
Transformer采用多头自注意力(multitheadsltentin)机制通过联合处理来自序列中不同表征子空间的不同位置的信息来来计算序列语义表征,利用不同的自注意力模块获得文本中每个词在不同语义空间下与原始词向量长度)相同的上下文语义向量在一系列任务中都表现很好
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 809
809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











