









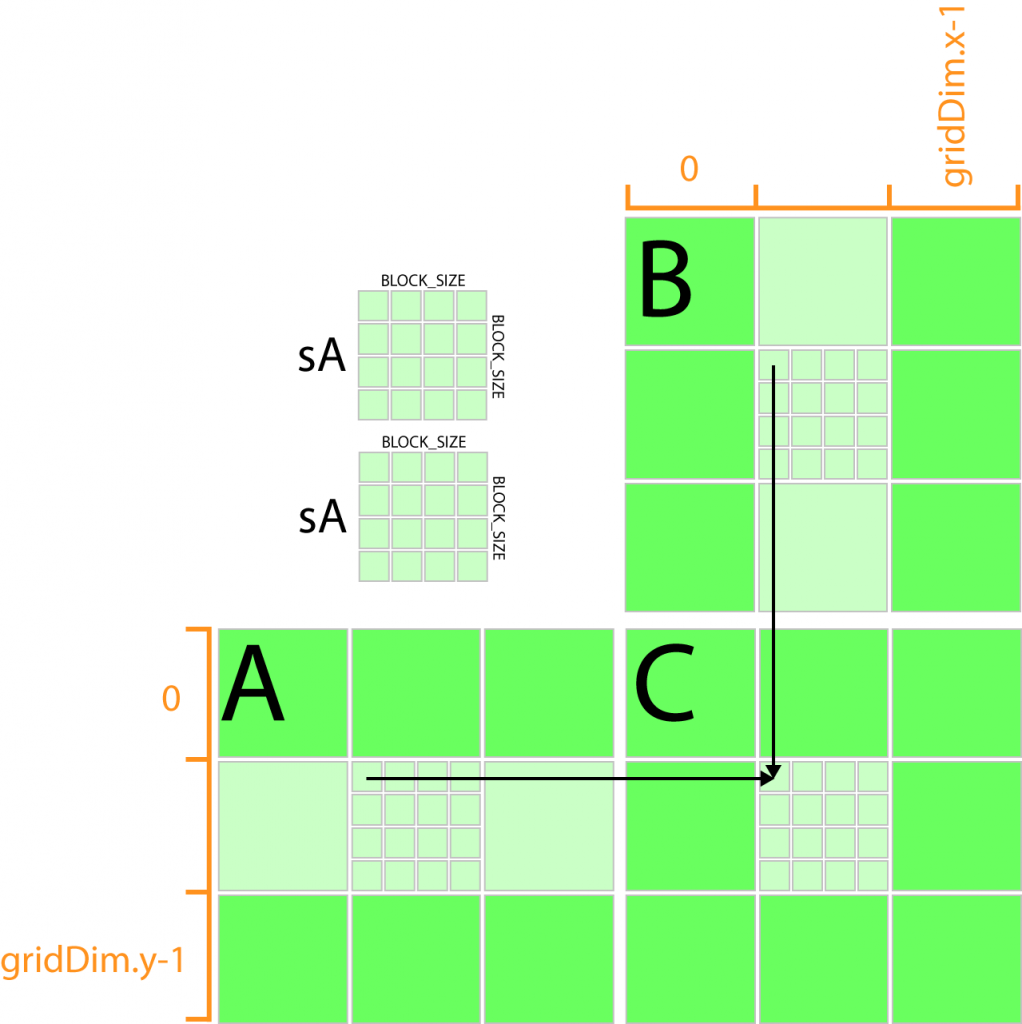
在CUDA编程03——矩阵相乘 最后,指出了存在长度限制的缺点。本例中我们降尝试解决这个问题。具体做法是:我们将输出矩阵拆分成小块(Tile),把拆分的每个小块放到一个block中,然后通过threadIdx和blockIdx来索引。
CPU计算的代码不变,只是现在的矩阵维度从32x32变成了1024x1024。
GPU计算代码:
__global__ void matrix_mul_device(FLOAT* M, FLOAT* N, FLOAT* P, int width)
{
int x = blockIdx.x*blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
float sum = 0, a, b;
for (int i = 0; i < width; ++i)
{
a = M[y*width + i];
b = N[i*width + x];
sum += a * b;
}
P[y*width + x] = sum;
}在上面的kernel代码关键在于如何计算当前block中的当前thread在全局中的x和y索引。
完整代码:
#include <stdio.h>
#include <stdlib.h>
#include <cuda.h>
#include <math.h>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <windows.h>
typedef float FLOAT;
double get_time();
void warm_up();
void matrix_mul_host(FLOAT* M, FLOAT* N, FLOAT* P, int width);
__global__ void matrix_mul_device(FLOAT* M, FLOAT* N, FLOAT* P, int width);
// <2d grid, 1d block>
#define get_tid() ((blockIdm.y*gridDim.x + blockIdm.x)*blockDim.x + threadIdm.x)
#define get_bid() (blockIdm.y*gridDim.x + blockIdm.x)
double get_time()
{
LARGE_INTEGER timer;
static LARGE_INTEGER fre;
static int init = 0;
double t;
if (init != 1)
{
QueryPerformanceFrequency(&fre);
init = 1;
}
QueryPerformanceCounter(&timer);
t = timer.QuadPart * 1. / fre.QuadPart;
return t;
}
// warm up gpu
__global__ void warmup_knl(void)
{
int i, j;
i = 1;
j = 1;
i = i + j;
}
void warm_up()
{
int i = 0;
for (; i < 8; ++i)
{
warmup_knl << <1, 256 >> > ();
}
}
// host code
void matrix_mul_host(FLOAT* M, FLOAT* N, FLOAT* P, int width)
{
for (int i = 0; i < width; ++i)
{
for (int j = 0; j < width; ++j)
{
float sum = 0, a, b;
for (int k = 0; k < width; ++k)
{
a = M[i*width + k];
b = N[k*width + j];
sum += a * b;
}
P[i*width + j] = sum;
}
}
}
// device code
__global__ void matrix_mul_device(FLOAT* M, FLOAT* N, FLOAT* P, int width)
{
int x = blockIdx.x*blockDim.x + threadIdx.x;
int y = blockIdx.y * blockDim.y + threadIdx.y;
float sum = 0, a, b;
for (int i = 0; i < width; ++i)
{
a = M[y*width + i];
b = N[i*width + x];
sum += a * b;
}
P[y*width + x] = sum;
}
int main()
{
int N = 1024, n_block=32;
int nbytes = N * N * sizeof(FLOAT);
int n_grid = int(N / n_block);
dim3 dimGrid(n_grid, n_grid);
dim3 dimBlock(n_block, n_block);
cudaError_t cudaStatus = cudaSetDevice(0);
// memory pointers
FLOAT* dm = NULL, *hm = NULL;
FLOAT* dn = NULL, *hn = NULL;
FLOAT* dp = NULL, *hp = NULL;
int iter = 1;
int i;
double th, td;
warm_up();
/* allocate gpu memory */
cudaMalloc((void**)&dm, nbytes);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc dm failed!");
goto Error;
}
cudaMalloc((void**)&dn, nbytes);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc dn failed!");
goto Error;
}
cudaMalloc((void**)&dp, nbytes);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc dp failed!");
goto Error;
}
if (dm == NULL || dn == NULL || dp == NULL)
{
printf("could not allocate gpu memory/n");
goto Error;
}
hm = (FLOAT*)malloc(nbytes);
hn = (FLOAT*)malloc(nbytes);
hp = (FLOAT*)malloc(nbytes);
if (hm == NULL || hn == NULL || hp == NULL)
{
printf("could not allocate cpu memory/n");
goto Error;
}
/* init */
for (i = 0; i < N*N; ++i)
{
hm[i] = i % 2 == 0 ? 1 : -1;
hn[i] = 1;
hp[i] = 2;
}
/* copy data to gpu*/
cudaMemcpy(dm, hm, nbytes, cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy dm failed!");
goto Error;
}
cudaMemcpy(dn, hn, nbytes, cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy dn failed!");
goto Error;
}
cudaMemcpy(dp, hp, nbytes, cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy dp failed!");
goto Error;
}
warm_up();
// call for gpu
cudaThreadSynchronize();
td = get_time();
for (i = 0; i < iter; ++i) matrix_mul_device << <dimGrid, dimBlock >> > (dm, dn, dp, N);
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "matmulKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
cudaThreadSynchronize();
td = get_time() - td;
// call for cpu
th = get_time();
for (i = 0; i < iter; ++i) matrix_mul_host(hm, hn, hp, N);
th = get_time() - th;
printf("GPU time: %.8f, CPU time: %.6f, Speedup: %g\n", td, th, th / td);
FLOAT* hp2 = (FLOAT*)malloc(nbytes);
for (int i = 0; i < N*N; ++i) hp2[i] = 0;
cudaMemcpy(hp2, dp, nbytes, cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!!!");
goto Error;
}
// check final results, should be zeros
float xh = 0, xd = 0;
for (int i = 0; i < N*N; ++i)
{
xh += hp[i];
xd += hp2[i];
}
printf("%.6f, %.6f", xh, xd);
Error:
// free
cudaFree(dm);
cudaFree(dn);
cudaFree(dp);
free(hm);
free(hn);
free(hp);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}实验结果:
GPU time: 0.01590590, CPU time: 6.316026, Speedup: 397.087
0.000000, 0.000000













 132
132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









