







17.聚类方法
1.系统聚类
系统聚类是一种聚类的方法,它的主要思想是,开始时每个对象自成一类,然后每次将最相似的两个类合并,从而让类别总数减少1。从它的方法上,我们可以看出,系统聚类的过程涵盖了类别数 k = 1 k=1 k=1至样本容量 n n n的所有情况,也就是说,想要分成几类,都可以在系统聚类的过程中得以实现,不过有的划分是有效的,有的划分则显得很勉强。
从系统聚类的步骤中,可以看见系统聚类法的一些特点。系统聚类的步骤是这样的:
-
数据预处理。一般是提取数据矩阵并进行标准化(或者其他数据变换),然后选择合适的距离度量。
-
初始情况下每个样品自成一类,计算 n n n个类两两间的距离。
-
将距离最近的类进行合并,此时类数为 k = n − 1 k=n-1 k=n−1,得到的新类为 C L k CL_k CLk。
-
重复执行2~3步,直到 k = 1 k=1 k=1为止,这样就可以得到 C L k , k = 1 , 2 , ⋯ , n − 1 CL_k,k=1,2,\cdots,n-1 CLk,k=1,2,⋯,n−1。
-
画出谱系聚类图。谱系聚类图是一个树状图,具体形态如下(高度是某种距离度量)。
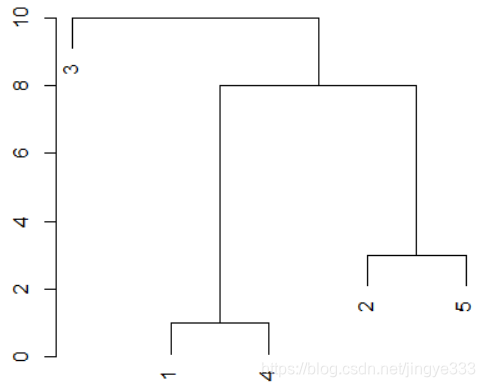
- 决定分类的个数,由聚类过程可以直接根据类数得到聚类结果。
在系统聚类的过程中,我们能够决定的部分,是度量的选择方式,以及最后生成类的个数。度量的选择方式可以是上一篇文章中定义的那些,不过由于距离定义方式不同,递推公式也不同,现有一种统一的递推距离定义式:
D
r
k
2
=
α
p
D
p
k
2
+
α
q
D
q
k
2
+
β
D
p
q
2
+
γ
∣
D
p
k
2
−
D
q
k
2
∣
,
D^2_{rk}=\alpha_pD^2_{pk}+\alpha_qD_{qk}^2+\beta D^2_{pq}+\gamma|D^2_{pk}-D^2_{qk}|,
Drk2=αpDpk2+αqDqk2+βDpq2+γ∣Dpk2−Dqk2∣,
随着聚类方式的不同,参数
α
p
,
α
q
,
β
,
γ
\alpha_p,\alpha_q,\beta,\gamma
αp,αq,β,γ的定义方式也不同,下表是不同方法的参数取值,Euclidean代表必须选择欧氏距离。
| 方法 | α p \alpha_p αp | α q \alpha_q αq | β \beta β | γ \gamma γ |
|---|---|---|---|---|
| single | 1/2 | 1/2 | 0 | -1/2 |
| complete | 1/2 | 1/2 | 0 | 1/2 |
| median | 1/2 | 1/2 | 一般取-1/4 | 0 |
| centroid (Euclidean) | n p / n r n_p/n_r np/nr | n q / n r n_q/n_r nq/nr | − α p α q -\alpha_p\alpha_q −αpαq | 0 |
| average | n p / n r n_p/n_r np/nr | n q / n r n_q/n_r nq/nr | 0 | 0 |
| mcquitty | ( 1 − β ) n p / n r (1-\beta)n_p/n_r (1−β)np/nr | ( 1 − β ) n q / n r (1-\beta)n_q/n_r (1−β)nq/nr | β < 1 \beta<1 β<1 | 0 |
| ward (Euclidean) | n p + n k n r + n k \frac{n_p+n_k}{n_r+n_k} nr+nknp+nk | n q + n k n r + n k \frac{n_q+n_k}{n_r+n_k} nr+nknq+nk | − n k n r + n k -\frac{n_k}{n_r+n_k} −nr+nknk | 0 |
2.类数选择
由于系统聚类法最终给出的是结果是谱系聚类图,任给一个类的个数,都能够得到相应的聚类结果,因此,类数必须由人为确定。直观地,我们可以从谱系聚类图上画出一条阈值线,将低于这条线的聚类情况当作聚类结果,并由此决定类数;也可以绘制数据点的二维、三维散点图(高维的可以嵌入二维或三维),从图上直观地得到聚类结果。
还可以根据以下的统计量,来确定类的个数。
-
R 2 R^2 R2统计量。参照方差分析的部分,定义为
R k 2 = B k T = 1 − P k T , R_k^2=\frac{B_k}{T}=1-\frac{P_k}{T}, Rk2=TBk=1−TPk,
这里
T = ∑ t = 1 k ∑ i = 1 n t ( X ( i ) ( t ) − X ˉ ) ′ ( X ( i ) ( t ) − X ˉ ) = P k + B k , P k = ∑ t = 1 k ∑ i = 1 n t ( X ( i ) ( t ) − X ˉ ( t ) ) ′ ( X ( i ) ( t ) − X ˉ ( t ) ) , B k = ∑ t = 1 k n t ( X ˉ ( t ) − X ˉ ) ′ ( X ˉ ( t ) − X ˉ ) . T=\sum_{t=1}^k\sum_{i=1}^{n_t}(X_{(i)}^{(t)}-\bar X)'(X_{(i)}^{(t)}-\bar X)=P_k+B_k,\\ P_k=\sum_{t=1}^k\sum_{i=1}^{n_t}(X_{(i)}^{(t)}-\bar X^{(t)})'(X_{(i)}^{(t)}-\bar X^{(t)}),\\ B_k=\sum_{t=1}^k n_t(\bar X^{(t)}-\bar X)'(\bar X^{(t)}-\bar X). T=t=1∑ki=1∑nt(X(i)(t)−Xˉ)′(X(i)(t)−Xˉ)=Pk+Bk,Pk=t=1∑ki=1∑nt(X(i)(t)−Xˉ(t))′(X(i)(t)−Xˉ(t)),Bk=t=1∑knt(Xˉ(t)−Xˉ)′(Xˉ(t)−Xˉ).
也就是组内离差平方和与总离差平方和的比值。如果 R k 2 R_k^2 Rk2随着 k k k的增加变化不大,则不需要继续划分类。 -
半偏 R k R_k Rk统计量。定义为
半 偏 R k 2 = R k + 1 2 − R k 2 . 半偏R_k^2=R^2_{k+1}-R^2_k. 半偏Rk2=Rk+12−Rk2. -
伪 F F F统计量。定义为
伪 F k = ( T − P k ) / ( k − 1 ) P k / ( n − k ) = B k P k n − k k − 1 , 伪F_k=\frac{(T-P_k)/(k-1)}{P_k/(n-k)}=\frac{B_k}{P_k}\frac{n-k}{k-1}, 伪Fk=Pk/(n−k)(T−Pk)/(k−1)=PkBkk−1n−k,
如果伪 F k F_k Fk越大,则分为 k k k个类的效果越显著。但是 F k F_k Fk并不具有 F F F分布的特点。
3.动态聚类
动态聚类的思想是,开始时粗略地分类,然后按照某种最优的原则修改不合理的分类,直至分类比较合理为止,形成最终的分类结果。有一种动态聚类的步骤如下:
- 选择凝聚点(初始类中心)与距离定义。
- 确定初始分类,可以按照距离判别归类。
- 计算每类重心,将重心作为新的凝聚点。
- 重复2~3步骤,直到所有新凝聚点与老的凝聚点重合。
这种方法叫做按批修改法,最终会收敛于凝聚点,其修改原则是使得分类函数(组内平方和)逐渐减小,直至不能再减小为止。
另一种方法叫逐个修改法,也叫K均值方法,它的步骤如下:
- 人为选定三个数,类数 K K K,类间距离最小值 C C C与类内距离最大值 R R R。
- 取前 K K K个样品作为凝聚点,计算 K K K个凝聚点两两间的距离,如果最小距离 < C <C <C,就合并这两个凝聚点,并使用这两个点的重心作为凝聚点,重复此步骤直到所有凝聚点之间的距离 ≥ C \ge C ≥C。
- 将剩下的 n − K n-K n−K个样品逐个归类。对于每一个样品,如果该样品与所有凝聚点之间的距离都 > R >R >R,就将其作为新的凝聚点;否则将其归入距离最近的凝聚点所在的类,随即重新计算这一类的重心作为新凝聚点。如果此时凝聚点之间的距离都 ≥ C \ge C ≥C,就考虑下一个样品,否则重复步骤2。
- 将全部样品按照步骤3进行归类,如果某个样品归类后分类与原来一致,则重心不必计算;否则重新计算所涉及到的两类重心(原先分的类与新分的类)。
4.最优分割法(Fisher算法)
最优分割法的应用情况是,给定的样本是有序的,这个顺序不能随意打乱,此时的聚类相当于往给定样本中设置分割(插入挡板),从而将样本分为几类。由于样本的顺序固定,所以此时要讨论的情况比无序情况要少得多。
这种情况下,Fisher算法可以保证获得最优解,接下来简要介绍一下Fisher算法。
-
定义类直径。对于类 G : { X ( i ) , X ( i + 1 ) , ⋯ , X ( j ) } G:\{X_{(i)},X_{(i+1)},\cdots,X_{(j)} \} G:{X(i),X(i+1),⋯,X(j)},定义类均值为 X ˉ G = 1 j − i + 1 ∑ t = 1 j X ( t ) \bar X_G=\frac{1}{j-i+1}\sum_{t=1}^j X_{(t)} XˉG=j−i+11∑t=1jX(t)。直径的定义为
D ( i , j ) = ∑ t = i j ( X ( t ) − X ˉ G ) ′ ( X ( t ) − X ˉ G ) . D(i,j)=\sum_{t=i}^j(X_{(t)}-\bar X_G)'(X_{(t)}-\bar X_G). D(i,j)=t=i∑j(X(t)−XˉG)′(X(t)−XˉG). -
定义分类的损失函数。令 b ( n , k ) b(n,k) b(n,k)代表把 n n n个有序样品分为 k k k类的某种分法,假设分点为 i 1 , ⋯ , i k i_1,\cdots,i_k i1,⋯,ik,它们是每一类的第一个下标,则分类的损失函数记作
L [ b ( n , k ) ] = ∑ i = 1 k D ( i t , i t + 1 − 1 ) , L[b(n,k)]=\sum_{i=1}^kD(i_t, i_{t+1}-1), L[b(n,k)]=i=1∑kD(it,it+1−1),
也就是每一类的直径加总,最优解的判定就是使得 L [ b ( n , k ) ] L[b(n,k)] L[b(n,k)]最小的一种分类方法,记作 P ( n , k ) P(n,k) P(n,k)。 -
求最优解。Fisher算法是一种动态规划,其核心过程是以下两个递推公式:
L [ P ( n , 2 ) ] = min 2 ≤ j ≤ n { D ( 1 , j − 1 ) + D ( j , n ) } , L [ P ( n , k ) ] = min k ≤ j ≤ n { L [ P ( j − 1 , k − 1 ) ] + D ( j , n ) } . L[P(n,2)]=\min_{2\le j\le n}\{D(1,j-1)+D(j,n) \},\\ L[P(n,k)]=\min_{k\le j\le n}\{L[P(j-1,k-1)]+D(j,n) \}. L[P(n,2)]=2≤j≤nmin{D(1,j−1)+D(j,n)},L[P(n,k)]=k≤j≤nmin{L[P(j−1,k−1)]+D(j,n)}.
回顾总结
- 系统聚类是一种静态聚类的方法,它的主要思想是一开始每一个样品自成一类,然后每次比较两个类之间的距离,将距离最小的两类进行合并并重复此流程。
- 动态聚类的思想是,通过初始设定的分类数与初始点,进行动态调整,最后返回一个收敛的聚类结果。
态聚类的方法,它的主要思想是一开始每一个样品自成一类,然后每次比较两个类之间的距离,将距离最小的两类进行合并并重复此流程。 - 动态聚类的思想是,通过初始设定的分类数与初始点,进行动态调整,最后返回一个收敛的聚类结果。
- 最优分割是一种动态规划的聚类方式,它将有序样品划分为组内离差和最小的类。

















 2496
2496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









