







DORE: Document Ordered Relation Extraction based on Generative Framework
文档级关系抽取是从整篇文档中抽取出三元组。更难,但也很有价值。
总的来说,我觉得还是可以的。也说明了在生成模式下,id相比于词组,尤其是在生成文本长度交汇处那个的情况下,id更有优势。
core idea
利用生成模型范式解决文档级关系抽取问题,但文档相比于句子面向句子过长,target sentence定位不准确,可能还存在实体不确定位置的情形。
一般的生成范式是直接生成出对应的词组,但这似乎不能很好的适应于文档级关系抽取。文章中提出,现有的生成式文档级关系抽取方法表现不佳,并不是模型能力不足,而是模型训练的范式不足导致的。
the root cause of the underwhelming performance of the existing generative DocRE models and discover that the culprit is the inadequacy of the training paradigm, instead of the
capacities of the models
在introduction中,作者指明为什么lexicon 范式的performance效果较差?
(1)不会产生特定长度的目标序列。
(2)生成序列过长。
请问,这里,是不是发现他们吧不连续实体识别中用到的数字代替的方式,引导这个任务中了。

Model structure
以表填充作为核心解决方式,表填充以生成序列的方式表示出来了。(将生成式DocRE 转为一个关系矩阵形式)
生成性DocRE是确定性地生成一个关系矩阵,其中每个单元格对应于具有预定关系或没有关系的实体对。
任务定义
k个entity,r是预定义的关系类型,文中集中在了五元组和三元组。
在给定D和E,计算R
2 -ary元祖:<1> <26> <101>
4-ary元祖:<1> <26> <51> <76> <101> 前面四个是实体的id,最后一个是关系的id。
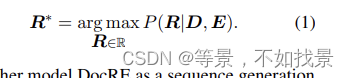
关系矩阵的有序化表示
用ID表示实体和关系。实体的id从1到100,关系的id从101-200这种。
对于每个id的embedding采用对应数字的embedding initialization作为初始化表示。
该种表示方式的优势:
约束解码考虑到参考序列完全是一系列用于二元关系提取的三元组或用于四元关系提取的五元组,与词汇生成范式相比,我们利用相对简单的约束解码方法来控制生成。 **vo cabulary 仅限于一定范围的特殊标记,几乎不依赖于当前步骤,因此解码器的词汇量很小。**相反,词汇生成方法需要完整的词汇表,因为它们需要预测实体的文本形式
我们只是按行-列顺序组织关系元组。矩阵中实体编排的顺序是:头部实体在文档中出现较早的关系实例在输出序列中出现较晚的关系实例,并且共享相同头部实体的关系的顺序由它们的尾部实体决定
辅助措施
加入了negative training examples来辅助模型的学习过程。也就是没有关系的pairs.
**损失函数:**交叉熵损失函数。
R+表示正实例组
R-表示负实例组

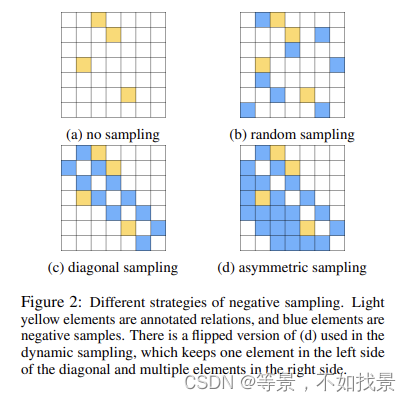
negative samples采样策略:
distant training:
“distant”表示模型首先在额外的嘈杂的distant training corpus(由DocRED提供)上进行训练,然后在人工标注的训练集上进行fine-tune。
实验
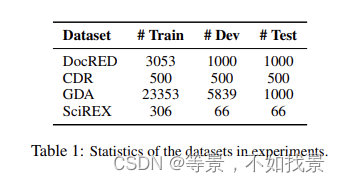
实验数据集
模型实验结果
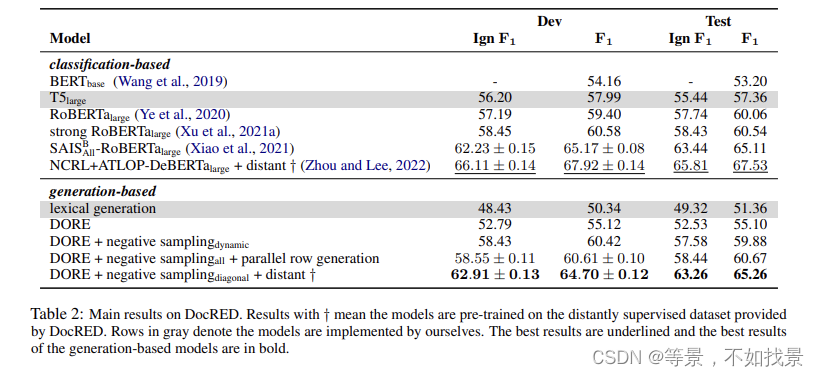
ablation study
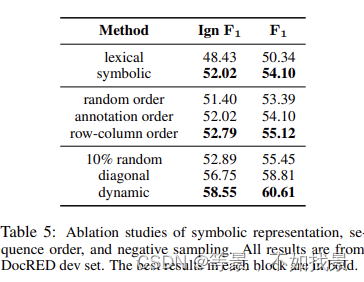
最后的10% random、diagonal、dynamic的采样策略:
“10% random” uniformly
picks 10% negative samples from the relation matrix. “diagonal” means we select negative samples
with window size of 1 around the diagonal.
“dynamic” uniformly selects the different strategies we introduced before. We test these settings
with T5large plus symbolic representation and rowcolumn order. We found the “10% random” option contributes little, the “diagonal” outperforms
it since it is consistent across entities. Finally, the
“dynamic” option performs the best because it provides the model a chance to see all negative samples in different passes
















 7430
7430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











