






KPConv: Flexible and Deformable Convolution for Point Clouds
-
模型:

-
Rigid KPConv
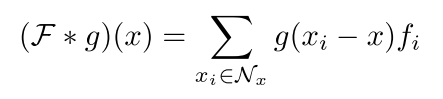
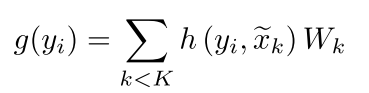
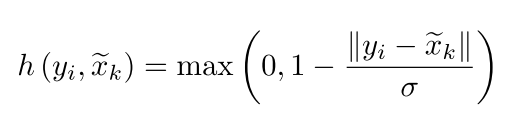
每个kernel point的权重 W k W_k Wk为 C i n ∗ C o u t C_in*C_{out} Cin∗Cout大小的矩阵。
对于球邻域中的每一个点,让它与所有kernel point都计算一个权重,并加在一起(第二个公式)。
对于一整个球邻域,计算出每一个点的权重加在一起,最终乘特征 f i f_i fi(第一个公式)。
h是kernel point与yi的相关性,取决于相对kernel point的位置。选取了线性相关,是一个更简单的表示。 这种更简单的相关性,可以在学习 kernel deformations时缓解梯度反向传播。 -
Deformable KPConv
对于每个Kernel Points学习一个位移Δ(x),通过对一个Rigid Kernel的KPNet,将特征从 D i n D_{in} Din 映射到3K维度,并在训练的时候给予0.1倍的学习率去进行训练.
很遗憾,这种对图像可变形卷积的直接适应并不适合点云。 实际上,内核点最终被拉离输入点。这些内核点会被网络丢失,因为当没有邻元素在其影响范围内时,它们的位移△(x)的梯度为零。
为了解决此问题,提出:
“fitting” regularization loss ,该损失会损失输入相邻点之间的kernel points与其最近的相邻点之间的距离。
“repulsive”regularization loss ,当所有成对的kernel points之间的影响区域重叠时,添加该损失使它们不会一起崩溃。
KPConv layer:卷积层将点 P ∈ R N × 3 P \in R^{N\times3} P∈RN×3,其对应特征 F ∈ R N × D i n F \in R^{N\times D_{in}} F∈RN×Din 和邻域索引 n ∈ [ 1 , N ] N ′ × n m a x n \in \left [ 1,N\right ]^{N'\times n_{max}} n∈[1,N]N′×nmax 矩阵作为输入。N’是被计算邻域的位置数,可以与N(在“strided ” KPConv的情况下)不同。 邻域矩阵被迫具有最大邻域 n m a x n_{max} nmax的大小。 由于大多数邻域包含少于 n m a x n_{max} nmax个邻域,因此矩阵n包含未使用的元素。 我们称它们为shadow neighbors,在卷积计算中将其忽略。
Network parameters:每个层j都有一个像元大小 d l j dl_j dlj,我们可以从中推断其他参数。kernel points 影响距离设置为等于 σ j = Σ × d l j σ_j=Σ×dl_j σj=Σ×dlj。对于rigid KPConv,平均 kernel point radius 为 1.5 σ j 1.5σ_j 1.5σj,卷积半径会自动设置为 2.5 σ j 2.5σ_j 2.5σj。对于deformable KPConv,可以选择卷积半径为 r j = ρ × d l j r_j =ρ×dl_j rj=ρ×dlj。Σ和ρ是为整个网络设置的比例系数。 论文默认对所有实验使用通过交叉验证选择的以下参数:K=15,Σ=1.0和ρ=5.0。第一个子采样像元大小 d l 0 dl_0 dl0取决于数据集, d l j + 1 + 1 = 2 ∗ d l j dl_{j+1} + 1 = 2 * dl_j dlj+1+1=2∗dlj。
实验中的细节
- 在实现代码的时候,由于查找邻居并不能在GPU上很好的完成,所以作者在网络训练之前就在CPU上计算好了每一层所要用到的邻居。因为找邻居的时候只用到了几何上的信息,所以这是完全可行的。
- 在实验中,密集的地方 n m a x n_{max} nmax可能会很大,所以使用neighborhood calibration来减少neighbor的数量。选取的 n m a x n_{max} nmax需要保证90%的邻域不会受到影响,而其余10%的点很多的邻域会损失掉一些点(其实是取了KNN)。
- 实验中不使用元素数量恒定的批处理,因为每个元素(输入球体)内部的点数变化很大。取而代之的是,确定批可以包含并堆叠元素的最大点数,直到达到限制为止。因此,批次具有更规则的大小:每个批次具有大约相同数量的点,但具有不同数量的输入球体。但是,我们仍然有一个batch_num参数。 calibrate_batches函数的作用是校准批中的最大点数(self.batch_limit),以使批中包含的平均输入球数接近batch_num。
- 没有将所有的数据放入一个epoch中,而是确定了batch数量和batch大小,相当于每次只从数据中取出固定数量的帧数(4400 = epoch_step*batch_num*1.1)进行训练。且balance sample保证每次训练时,每个类别的都能取到相同多的帧数。
- 每行neighbors_indices指向每个卷积位置的邻居。 由于每个卷积都有固定的邻居数,因此添加了shadow_point,多余的索引指向shadow_point。
- SemanticKITTIDataset Class
_init_:读取config文件,初始化label,读取calibrarion pose,初始化potentials(每一帧点云被选取到的概率,会在被选中后增加),初始化N(每一个epoch处理多少帧数据是确定好的)。定义了epoch_i(在__getitem__里被更新),epoch_inds(在sampler的__iter__中被更新),epoch_labels(在sampler的__iter__中被更新)。
_len_:返回一共有多少帧。
_getitem_:处理了数据,得到input_list,保存了每一层要用到的点和邻居,以及池化和上采样的信息。
“Eliminate points further than config.in_radius”,在一帧点云上随机选取了一个中心点,距离中心点大于in_radius的点都被去掉了。(所以在一帧点云上只计算了一个球体里的点??)随后加上shuffle打乱顺序。 - SemanticKITTISampler Class
采样方法基于updated potentials,保证对场景的每个部分进行充足的采样。(tf: in batch_gen func)该策略利用potentials使随机采样对密度变化不变。 基本思想是,每个点云帧都有一个电位(随机产生的标量值),每次都选择电位最低的点作为中心,然后增加所有球体点的电位,依此类推。















 1945
1945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









