






文章介绍
对于ASTE任务,目前主流的基于序列标注的方法或者是一些流水线和端到端的方法大多只是单纯地考虑词语词之间的交互,然而无论是方面实体或者意见词,其都有可能由多个单词或者token组成,仅考虑词级的交互则很容易只提取核心单词,而忽略了诸如“not”等,虽然不是核心词,但却对最后的情感判断起同样作用的token。
因此这篇文章通过两部分的多头注意力机制模拟跨度之间的关联以及跨度与句子之间的语义信息,分别提取语句中所含有的方面实体和意见词,其中对于意见词的提取会接受来自于方面实体的接收。
模型介绍
跨度生成
首先通过BERT预训练语言模型生成其隐藏序列表示,通过平均池化获得不同跨度间的表示。
双向架构
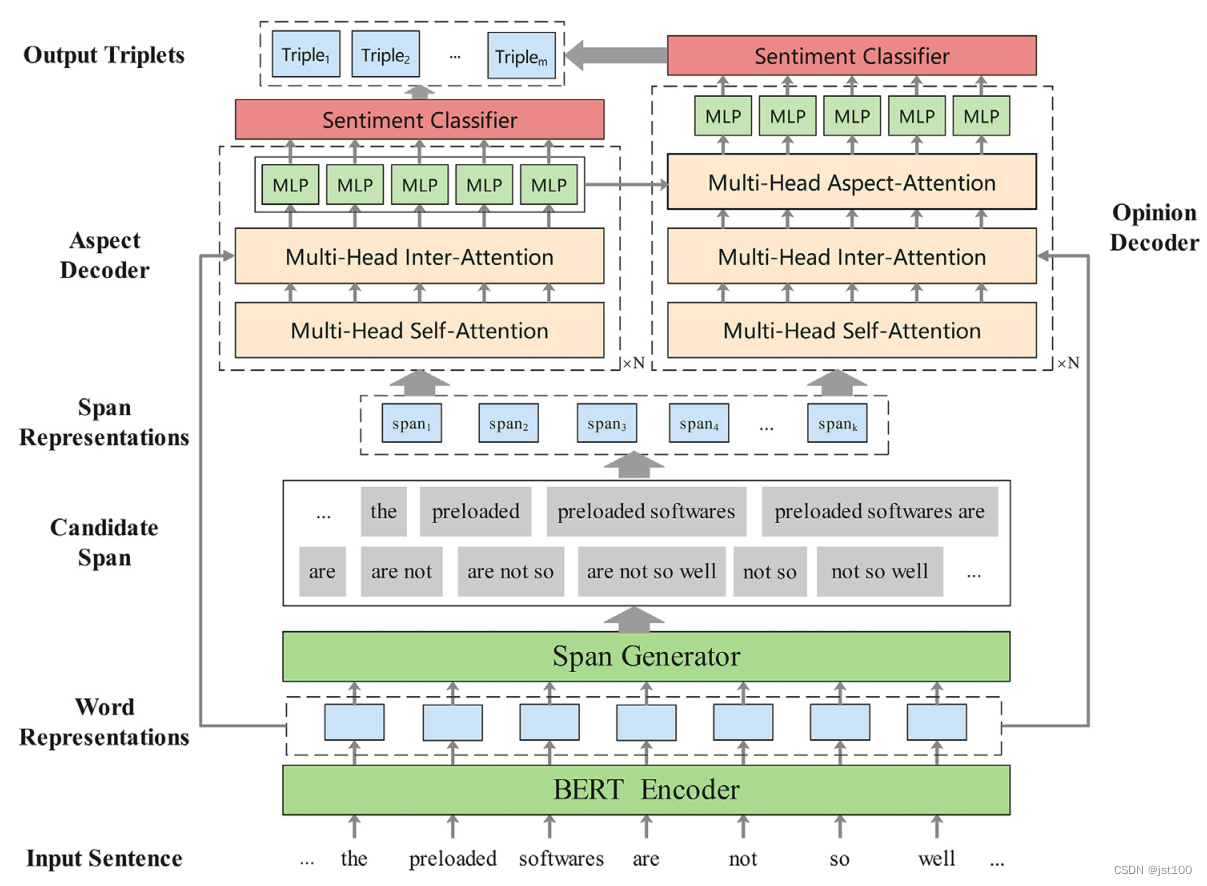
该文提出的模型如上所示。对于方面实体提取的这一部分,是采用了2个多头注意力机制,公式如下所示
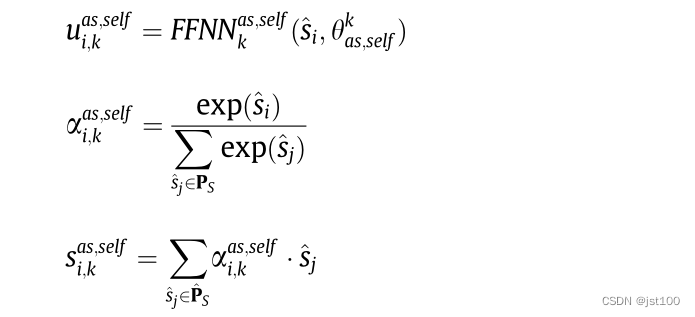

这里作者,不仅是提取出方面实体,并且也判断其情感极性

对于意见词的提取与对方面实体的抽取过程是大致相同,就是中间多加了一个对方面多头注意力机制
总结
自我感觉这篇文章就是在叠BUFF,一直用多头注意力机制,但是也有一定道理,因为方面实体和意见词之间是有关联的,所以分数应该会比普通词要高,因此opinion的第3个多头注意力机制也是有必要的。但是这篇文章没有给出相应的代码,公式我看的也不是很懂。
文章地址:https://www.sciencedirect.com/science/article/pii/S0925231222003897














 943
943











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









